Копаться в R профилирования информации
Я пытаюсь оптимизировать немного кода, и озадачен информацией из summaryRprof(), В частности, похоже, что несколько вызовов выполняются внешними C-программами, но я не могу определить, какая C-программа, какая R-функция. Я планирую решить эту проблему с помощью нарезки и нарезки кода, но мне было интересно, не пропускаю ли я какой-то лучший способ интерпретации данных профилирования.
Самая потребляющая функция .Call, который, по-видимому, является общим описанием для вызовов кода C; Следующими ведущими функциями являются операции присваивания:
$by.self
self.time self.pct total.time total.pct
".Call" 2281.0 54.40 2312.0 55.14
"[.data.frame" 145.0 3.46 218.5 5.21
"initialize" 123.5 2.95 217.5 5.19
"$<-.data.frame" 121.5 2.90 121.5 2.90
"as.vector" 110.5 2.64 416.0 9.92
Я решил сосредоточиться на .Call чтобы увидеть, как это возникает. Я просмотрел файл профилирования, чтобы найти эти записи с .Call в стеке вызовов, и следующие являются верхними записями в стеке вызовов (по количеству появлений):
13640 "eval"
11252 "["
7044 "standardGeneric"
4691 "<Anonymous>"
4658 "tryCatch"
4654 "tryCatchList"
4652 "tryCatchOne"
4648 "doTryCatch"
Этот список ясен как грязь: у меня есть <Anonymous> а также standardGeneric там.
Я полагаю, что это связано с вызовами функций в пакете Matrix, но это потому, что я смотрю на код, и этот пакет, похоже, является единственным возможным источником кода на языке Си. Однако в этом пакете вызывается множество различных функций из Matrix, и очень трудно определить, какая функция потребляет в этот раз.
Итак, мой вопрос довольно простой: есть ли способ расшифровки и приписывания этих вызовов (например, .Call, <Anonymous>и т. д.) по-другому? График графа вызовов для этого кода довольно сложен для отображения, учитывая количество задействованных функций.
Тактика отступления, которую я вижу, состоит в том, чтобы (1) закомментировать кусочки кода (и взломать, чтобы заставить код работать с этим), чтобы увидеть, где происходит потребление времени, или (2) обернуть определенные операции внутри других функций и посмотреть когда эти функции появляются в стеке вызовов. Последний не элегантен, но кажется, что это лучший способ добавить тег в стек вызовов. Первое неприятно, потому что выполнение кода занимает довольно много времени, а итеративно раскомментирование кода и повторный запуск неприятны.
3 ответа
Кажется, что короткий ответ - "Нет", а длинный - "Да, но вам это не понравится". Даже ответ на этот вопрос займет некоторое время (так что постарайтесь, я могу его обновить).
При работе с профилированием в R есть несколько основных моментов, на которые стоит обратить внимание:
Во-первых, есть много разных способов думать о профилировании. Весьма типично думать в терминах стека вызовов. В любой данный момент это последовательность вызовов функций, которые активны, по сути, вложенные друг в друга (подпрограммы, если хотите). Это очень полезно для понимания состояния вычислений, где будут возвращаться функции, и многих других вещей, которые важны для того, чтобы видеть вещи так, как их видит компьютер / интерпретатор / ОС. Rprof вызывает профилирование стека
Во-вторых, другая точка зрения состоит в том, что у меня есть куча кода, и конкретный вызов занимает много времени: какая строка в моем коде вызвала этот вызов? Это профилирование линии. Насколько я могу судить, у R нет профилирования линий. Это в отличие от Python и Matlab, которые оба имеют линейные профилировщики.
В-третьих, отображение от строк к вызовам сюръективно, но не биективно: учитывая конкретный стек вызовов, мы не можем гарантировать, что сможем отобразить его обратно в код. Фактически, анализ стека вызовов часто суммирует вызовы полностью вне контекста всего стека (т. Е. Совокупное время сообщается независимо от того, где был этот вызов во всех различных стеках, в которых он произошел).
В-четвертых, хотя у нас есть эти ограничения, мы можем надеть статистические шляпы и тщательно проанализировать данные стека вызовов и посмотреть, что из этого можно сделать. Информация о стеке вызовов - это данные, и нам нравятся данные, не так ли?:)
Просто краткое введение в стек вызовов. Давайте просто предположим, что наш стек вызовов выглядел так:
"C" "B" "A"
Это означает, что функция A называется B, которая затем вызывает C (порядок меняется), а стек вызовов имеет 3 уровня глубины. В моем коде стек вызовов достигает 41 уровня. Поскольку стеки могут быть настолько глубокими и представлены в обратном порядке, это более понятно для программного обеспечения, чем для человека. Естественно, мы начинаем очищать и преобразовывать эти данные.:)
Теперь наши данные действительно выглядят так:
".Call" "subCsp_cols" "[" "standardGeneric" "[" "eval" "eval" "callGeneric"
"[" "standardGeneric" "[" "myFunc2" "myFunc1" "eval" "eval" "doTryCatch"
"tryCatchOne" "tryCatchList" "tryCatch" "FUN" "lapply" "mclapply"
"<Anonymous>" "%dopar%"
Несчастный, не так ли? У него даже есть дубликаты таких вещей, как evalкакой-то парень позвонил <Anonymous> - вероятно, какой-то чертов хакер. (Аноним это легион, кстати.:-))
Первым шагом в превращении этого в нечто полезное было разделение каждой строки Rprof() вывести и перевернуть записи (через strsplit а также rev). Первые 12 записей (последние 12, если вы посмотрите на необработанный стек вызовов, а не послеrev версия) были одинаковыми для каждой строки (из которых было около 12000, интервал выборки составлял 0,5 секунды, то есть около 100 минут профилирования), и их можно отбросить.
Помните, что мы все еще заинтересованы в том, чтобы знать, какие строки привели к .Call, что заняло так много времени. Прежде чем мы перейдем к этому вопросу, мы добавим статистические ограничения: отчеты по профилированию, например, из summaryRprof, profr, ggplotи т. д., отражают только совокупное время, потраченное на данный вызов или на вызовы ниже данного вызова. Что эта накопительная информация не говорит нам? Бинго: был ли этот вызов сделан много раз или несколько раз, и было ли время, проведенное постоянно, в течение всех вызовов этого вызова, или есть некоторые выбросы. Определенная функция может выполняться 100 или 100 тыс. Раз, но вся стоимость может быть вызвана одним вызовом (не должно, но мы не узнаем, пока не посмотрим на данные).
Это только начинает описывать веселье. Пример A->B->C не отражает то, как все может выглядеть на самом деле, например, A->B->C->D->B->E. Теперь "В" можно посчитать пару раз. Более того, предположим, что на уровне C тратится много времени, но мы никогда не выполняем выборки именно на этом уровне, а только видим его дочерние вызовы в стеке. Мы можем видеть значительное время для "total.time", но не для "self.time". Если в C много разных дочерних вызовов, мы можем упускать из виду то, что нужно оптимизировать - стоит ли вообще убирать C или настраивать дочерние элементы, B, D и E?
Просто чтобы учесть потраченное время, я взял последовательности и провел их digest, сохраняя счет для усвоенных значений, через hash, Я также разделяю последовательности, сохраняя {(A),(A,B), (A,B,C) и т. Д.}. Это не кажется интересным, но удаление синглетонов из подсчетов очень помогает в очистке данных. Мы также можем хранить время, потраченное на каждый звонок, используя rle(), Это полезно для анализа распределения времени, затраченного на данный вызов.
Тем не менее, мы не находимся ближе к тому, чтобы найти фактическое время, потраченное на строку кода Мы никогда не получим строки кода из стека вызовов. Более простой способ сделать это - сохранить список раз по всему коду, в котором хранятся выходные данные proc.time()для данного вызова. Разница во времени показывает, какие строки или разделы кода занимают много времени. (Подсказка: это то, что мы действительно ищем, а не реальные звонки.)
Однако у нас есть этот стек вызовов, и мы могли бы сделать что-то полезное. Подниматься вверх по стеку несколько интересно, но если мы перемотаем информацию профиля немного раньше, мы можем найти, какие вызовы имеют тенденцию предшествовать более длительным вызовам. Это позволяет нам искать ориентиры в стеке вызовов - позиции, где мы можем связать вызов с определенной строкой кода. Это немного упрощает сопоставление большего количества обращений к коду, если все, что у нас есть, это стек вызовов, а не инструментальный код. (Как я постоянно повторяю: вне контекста нет отображения 1:1, но при достаточно тонкой детализации, особенно при неодинаковых вызовах с неоднократным обращением, вы можете найти ориентиры в вызовах, которые сопоставляются с кодом.)
В целом, я смог найти, какие вызовы занимают много времени, будь то длительный интервал или много мелких, каково распределение времени, проведенного, и, приложив некоторые усилия, я смог отобразить наиболее важные и трудоемкие обращения к коду и выяснение того, какие части кода могут извлечь наибольшую выгоду от переписывания или изменения алгоритмов.
Статистический анализ стека вызовов доставляет массу удовольствия, но исследование конкретного вызова на основе совокупного потребления времени не очень хороший способ. Кумулятивное время, потребляемое вызовом, является информативным относительно, но оно не дает нам информации о том, потреблял ли один или несколько вызовов это время, ни о глубине вызова в стеке, ни о разделе кода, отвечающем за вызовы., Первые две вещи могут быть решены с помощью немного большего количества R-кода, в то время как последняя лучше всего реализуется с помощью инструментального кода.
Поскольку у R еще нет профилировщиков линий, таких как Python и Matlab, самый простой способ справиться с этим - просто обработать свой код.
Могу ли я предложить вам использовать profr пакет. Это еще одна часть магии Хэдли. Это обертка вокруг Rprof и дает представление о стеке вызовов и таймингах.
я нахожу profr очень прост в использовании и интерпретации. Например, вот профиль немного ddply пример кода и полученный profr сюжет:
library(profr)
p <- profr(
ddply(baseball, .(year), "nrow"),
0.01
)
plot(p)
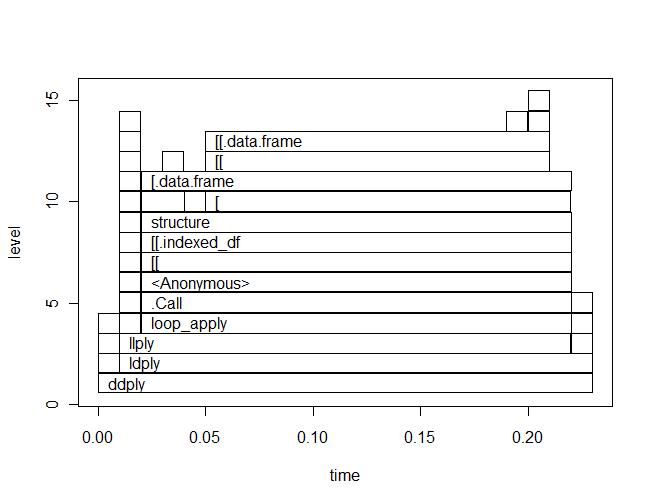
Вы можете сразу увидеть следующее:
- Как
ddplyзвонкиldply,llplyа такжеloop_apply, - внутри
loop_applyE сть.Callфункция.
Вы можете подтвердить это, прочитав исходный код loop_apply:
> plyr:::loop_apply
function (n, f, env = parent.frame())
{
.Call("loop_apply", as.integer(n), f, env)
}
<environment: namespace:plyr>
Редактировать. Есть что-то очень странное в ggplot.profr метод. Я предложил следующее исправление Хэдли. (Вы можете попробовать это на своем примере.)
ggplot.profr <- function (data, ..., minlabel = 0.1, angle = 0){
if (!require("ggplot2", quiet = TRUE))
stop("Please install ggplot2 to use this plotting method")
data$range <- diff(range(data$time))
ggplot(as.data.frame(data), aes(y=level)) +
geom_rect(
#aes(xmin=(level), xmax=factor(level)+1, ymin=start, ymax=end),
aes(ymin=level-0.5, ymax=level+0.5, xmin=start, xmax=end),
#position = "identity", stat = "identity", width = 1,
fill = "grey95",
colour = "black", size = 0.5) +
geom_text(aes(label = f, x = start + range/60),
data = subset(data, time > max(time) * minlabel), size = 4, angle = angle, vjust=0.5, hjust = 0) +
scale_x_continuous("time") +
scale_y_continuous("level")
}
Строка в файле профиля может выглядеть так
"strsplit" ".parseTabix" ".readVcf" "readVcf" "standardGeneric" "readVcf" "system.time"
который говорит, читая справа налево, что самая внешняя функция была system.time, которая вызывала readVcf, который был универсальным S4, который отправлялся методу readVcf, вызывая функцию.readVcf, которая вызывала.parseTabix, который в конце концов вызвал strsplit.
Здесь мы читаем в файле профиля, сортируем строки, подсчитываем их (используя rle - выполнить кодировку длины), затем выберите шесть наиболее распространенных путей в файле профиля
r = rle(sort(readLines("readVcf.Rprof"))
o = order(r$lengths, decreasing=TRUE)
r$values[head(o)]
это
r$lengths[head(o)]
говорит нам, сколько раз каждый из этих стеков вызовов был выбран.
Есть некоторые общие закономерности, которые могут помочь интерпретировать это. Вот тип S4, отправляемый его методу
"readVcf" "standardGeneric" "readVcf"
lapply перебирая свою функцию
"FUN" "lapply"
и tryCatch окружающий .Call
".Call" "doTryCatch" "tryCatchOne" "tryCatchList" "tryCatch"
Обычно кто-то пытается профилировать относительно небольшие куски кода, а не целый сценарий, с небольшим фрагментом, идентифицированным, например, путем интерактивного пошагового выполнения кода или составления некоторых образованных предположений о том, какие части могут быть медленными. Тот факт, что.Call является наиболее часто используемой функцией выборки, не внушает оптимизма - это говорит о том, что большую часть времени уже проводится в C. Вероятно, ваша лучшая ставка будет заключаться в том, чтобы придумать лучший общий алгоритм, а не использовать метод грубой силы,