Диаграмма рассеяния matplotlib с различным текстом в каждой точке данных
Я пытаюсь составить точечный график и аннотировать точки данных различными номерами из списка. так, например, я хочу построить y против x и аннотировать с соответствующими числами из n.
y = [2.56422, 3.77284, 3.52623, 3.51468, 3.02199]
z = [0.15, 0.3, 0.45, 0.6, 0.75]
n = [58, 651, 393, 203, 123]
ax = fig.add_subplot(111)
ax1.scatter(z, y, fmt='o')
Есть идеи?
2 ответа
Я не знаю ни одного метода построения графиков, который бы использовал массивы или списки, но вы могли бы использовать annotate() перебирая значения в n,
y = [2.56422, 3.77284, 3.52623, 3.51468, 3.02199]
z = [0.15, 0.3, 0.45, 0.6, 0.75]
n = [58, 651, 393, 203, 123]
fig, ax = plt.subplots()
ax.scatter(z, y)
for i, txt in enumerate(n):
ax.annotate(txt, (z[i], y[i]))
Есть много вариантов форматирования для annotate() Посетите веб-сайт matplotlib:

В случае, если кто-то пытается применить вышеуказанные решения к.scatter () вместо.subplot (),
Я попытался запустить следующий код
y = [2.56422, 3.77284, 3.52623, 3.51468, 3.02199]
z = [0.15, 0.3, 0.45, 0.6, 0.75]
n = [58, 651, 393, 203, 123]
fig, ax = plt.scatter(z, y)
for i, txt in enumerate(n):
ax.annotate(txt, (z[i], y[i]))
Но натолкнулся на ошибки, в которых говорилось, что "невозможно распаковать не повторяемый объект PathCollection", а ошибка указывает на кодовую строку fig, ax = plt.scatter(z, y)
Я в конце концов решил ошибку, используя следующий код
plt.scatter(z, y)
for i, txt in enumerate(n):
plt.annotate(txt, (z[i], y[i]))
Я не ожидал, что будет разница между.scatter () и.subplot (), я должен был знать лучше.
В версии более ранней, чем Matplotlib 2.0, ax.scatter Не обязательно печатать текст без маркеров. В версии 2.0 вам понадобится ax.scatter установить правильный диапазон и маркеры для текста.
y = [2.56422, 3.77284, 3.52623, 3.51468, 3.02199]
z = [0.15, 0.3, 0.45, 0.6, 0.75]
n = [58, 651, 393, 203, 123]
fig, ax = plt.subplots()
for i, txt in enumerate(n):
ax.annotate(txt, (z[i], y[i]))
И в этой ссылке вы можете найти пример в 3d.
Вы также можете использовать pyplot.text (см. здесь).
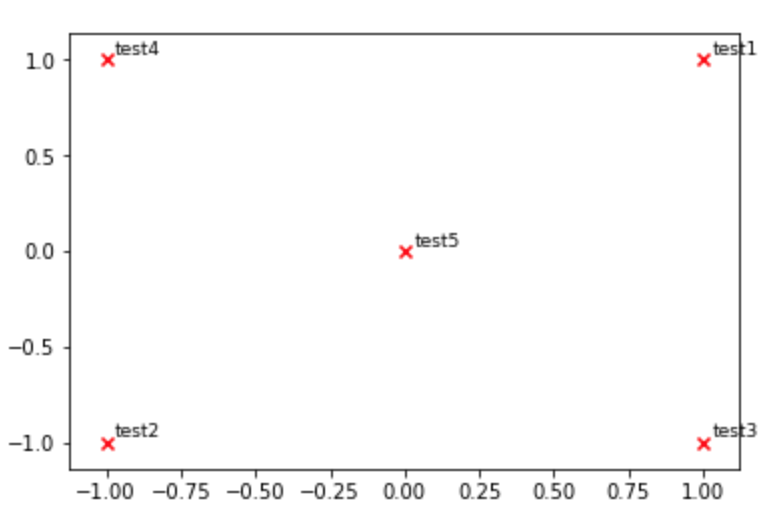
def plot_embeddings(M_reduced, word2Ind, words):
""" Plot in a scatterplot the embeddings of the words specified in the list "words".
Include a label next to each point.
"""
for word in words:
x, y = M_reduced[word2Ind[word]]
plt.scatter(x, y, marker='x', color='red')
plt.text(x+.03, y+.03, word, fontsize=9)
plt.show()
M_reduced_plot_test = np.array([[1, 1], [-1, -1], [1, -1], [-1, 1], [0, 0]])
word2Ind_plot_test = {'test1': 0, 'test2': 1, 'test3': 2, 'test4': 3, 'test5': 4}
words = ['test1', 'test2', 'test3', 'test4', 'test5']
plot_embeddings(M_reduced_plot_test, word2Ind_plot_test, words)
Я хотел бы добавить, что вы даже можете использовать стрелки / текстовые поля для аннотирования меток. Вот что я имею в виду:
import random
import matplotlib.pyplot as plt
y = [2.56422, 3.77284, 3.52623, 3.51468, 3.02199]
z = [0.15, 0.3, 0.45, 0.6, 0.75]
n = [58, 651, 393, 203, 123]
fig, ax = plt.subplots()
ax.scatter(z, y)
ax.annotate(n[0], (z[0], y[0]), xytext=(z[0]+0.05, y[0]+0.3),
arrowprops=dict(facecolor='red', shrink=0.05))
ax.annotate(n[1], (z[1], y[1]), xytext=(z[1]-0.05, y[1]-0.3),
arrowprops = dict( arrowstyle="->",
connectionstyle="angle3,angleA=0,angleB=-90"))
ax.annotate(n[2], (z[2], y[2]), xytext=(z[2]-0.05, y[2]-0.3),
arrowprops = dict(arrowstyle="wedge,tail_width=0.5", alpha=0.1))
ax.annotate(n[3], (z[3], y[3]), xytext=(z[3]+0.05, y[3]-0.2),
arrowprops = dict(arrowstyle="fancy"))
ax.annotate(n[4], (z[4], y[4]), xytext=(z[4]-0.1, y[4]-0.2),
bbox=dict(boxstyle="round", alpha=0.1),
arrowprops = dict(arrowstyle="simple"))
plt.show()
Это сгенерирует следующий график: https://i.stack.imgur.com/IM6fl.png
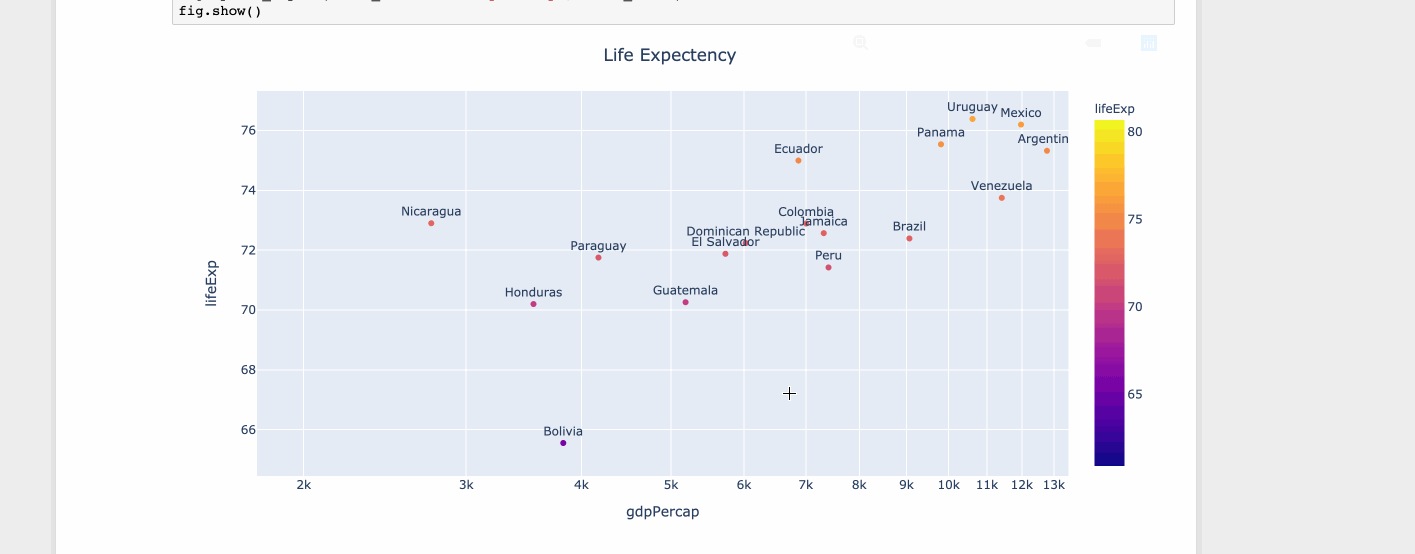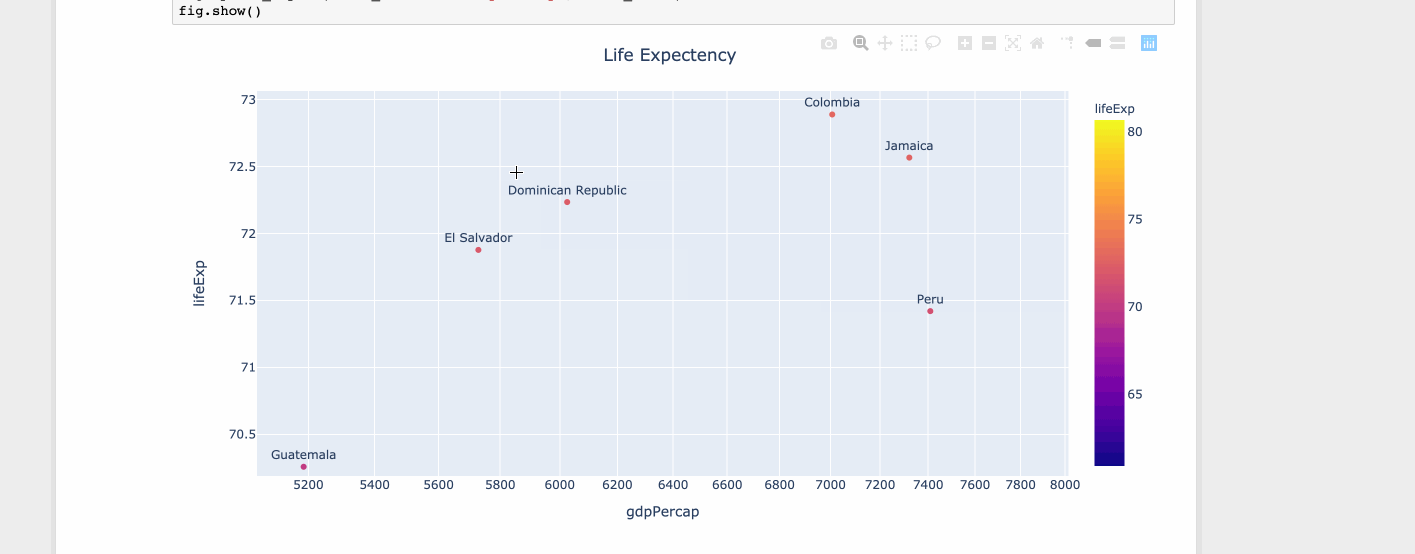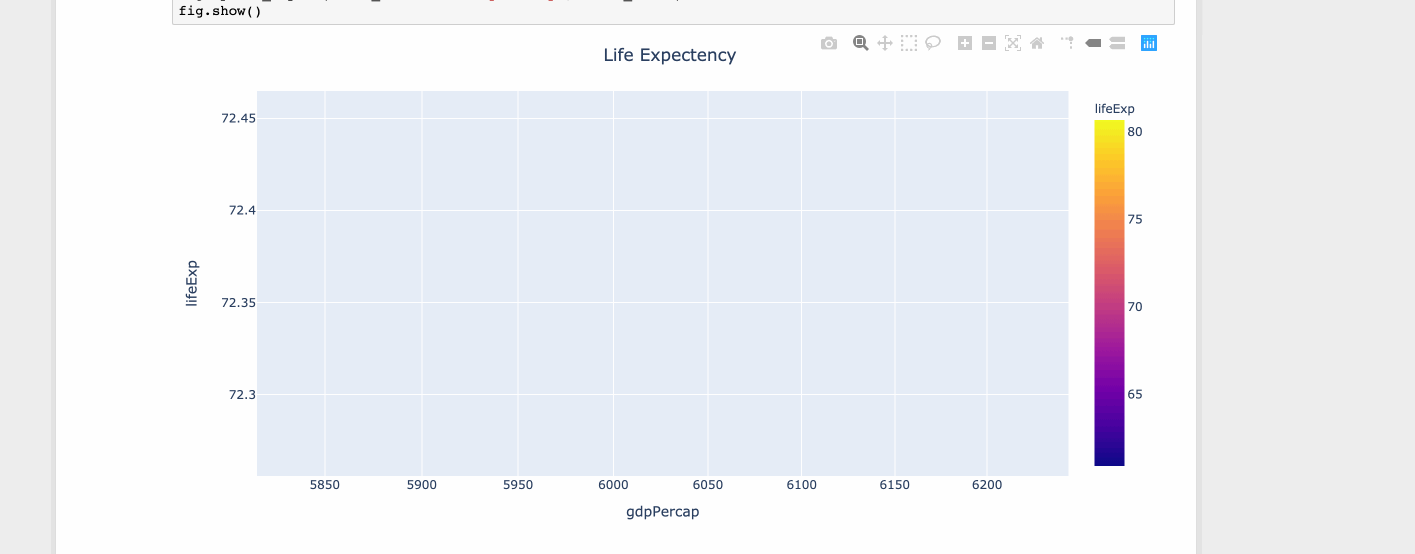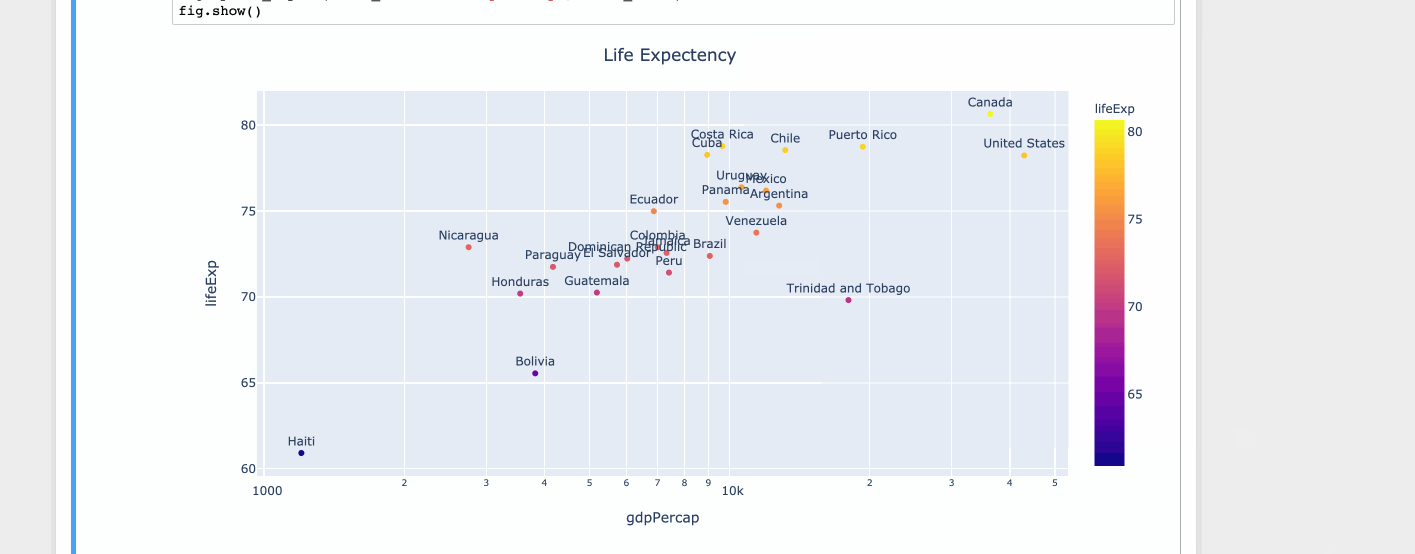
Для ограниченного набора значений подойдет matplotlib. Но когда у вас много значений, всплывающая подсказка начинает перекрывать другие точки данных. Но с ограниченным пространством вы не можете игнорировать значения. Следовательно, лучше уменьшить или увеличить масштаб.
Сюжетно
import plotly.express as px
df = px.data.tips()
df = px.data.gapminder().query("year==2007 and continent=='Americas'")
fig = px.scatter(df, x="gdpPercap", y="lifeExp", text="country", log_x=True, size_max=100, color="lifeExp")
fig.update_traces(textposition='top center')
fig.update_layout(title_text='Life Expectency', title_x=0.5)
fig.show()
Python 3.6+:
coordinates = [('a',1,2), ('b',3,4), ('c',5,6)]
for x in coordinates: plt.annotate(x[0], (x[1], x[2]))
Это может быть полезно, когда вам нужно индивидуально аннотировать в разное время (я имею в виду, не в одном цикле for)
ax = plt.gca()
ax.annotate('your_lable', (x,y))
где
x и
yваша целевая координата и тип float/int.
В качестве одного лайнера с использованием понимания списка и numpy:
[ax.annotate(x[0], (x[1], x[2])) for x in np.array([n,z,y]).T]
настройка - это то же самое, что и ответ Рутгера.