Нечеткое совпадение нечеткой строки на 2 больших наборах данных на основе условия - python
У меня есть 2 больших набора данных, которые я прочитал в Pandas DataFrames (~ 20K строк и ~40K строк соответственно). Когда я пытаюсь объединить эти два файла DF напрямую, используя pandas.merge в поле адреса, я получаю ничтожное количество совпадений по сравнению с количеством строк. Поэтому я подумал, что я попытаюсь найти нечеткое совпадение строк, чтобы увидеть, улучшает ли оно количество совпадений на выходе.
Я подошел к этому, пытаясь создать новый столбец в DF1 (20K строк), который был результатом применения функции нечеткого извлечения на DF1[addressline] к DF2[addressline]. Вскоре я понял, что это будет длиться вечно, поскольку он будет проводить около 1 миллиарда сравнений.
Оба этих набора данных имеют поля "County", и я спрашиваю: есть ли способ условно выполнить нечеткое совпадение строк в полях "addressline" в обоих DF на основе одинаковых полей "county"? Изучая вопросы, подобные моим, я наткнулся на это обсуждение: нечеткая логика на больших наборах данных с использованием Python
Тем не менее, я все еще не уверен (как каламбур) о том, как группировать / блокировать поля в зависимости от округа. Любой совет будет принята с благодарностью!
import pandas as pd
from fuzzywuzzy import process
def fuzzy_match(x, choices, scorer, cutoff):
return process.extractOne(x, choices = choices, scorer = scorer, score_cutoff= cutoff)[0]
test = pd.DataFrame({'Address1':['123 Cheese Way','234 Cookie Place','345 Pizza Drive','456 Pretzel Junction'],'ID':['X','U','X','Y']})
test2 = pd.DataFrame({'Address1':['123 chese wy','234 kookie Pl','345 Pizzza DR','456 Pretzel Junktion'],'ID':['X','U','X','Y']})
test['Address1'] = test['Address1'].apply(lambda x: x.lower())
test2['Address1'] = test2['Address1'].apply(lambda x: x.lower())
test['FuzzyAddress1'] = test['Address1'].apply(fuzzy_match, args = (test2['Address1'], fuzz.ratio, 80))
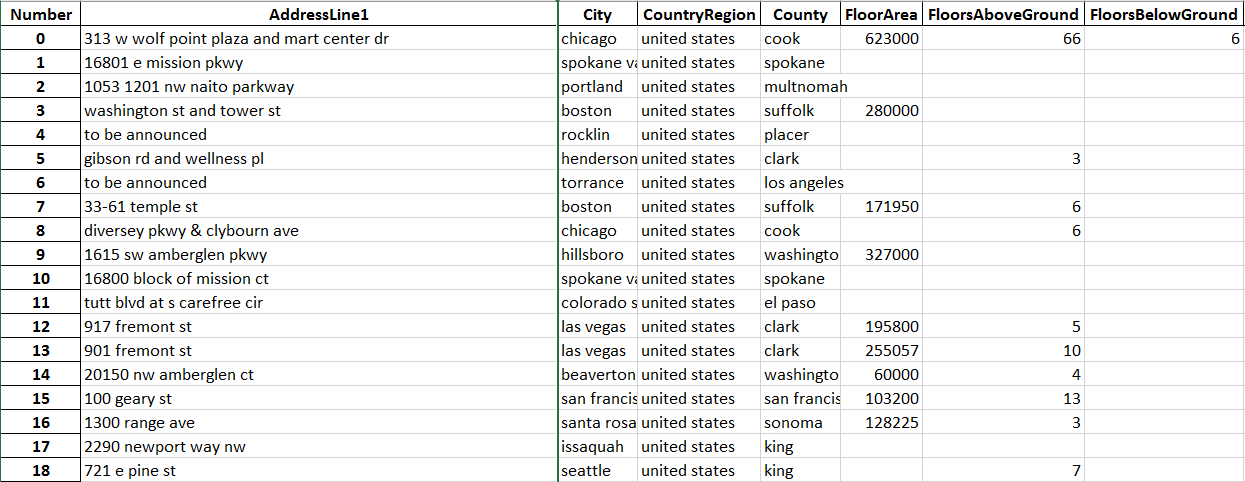
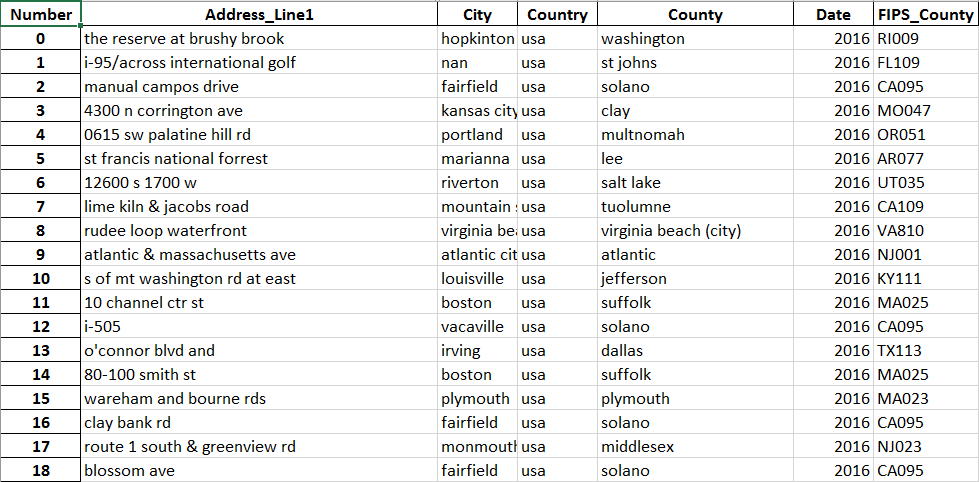
Я добавил 2 изображения, которые являются примерами наборов из 2 разных DF, импортированных в Excel. Не все поля были включены, так как они не важны для моего вопроса. Чтобы повторить мою конечную цель, я хочу новый столбец в одном из DF, который имеет лучший результат из-за нечеткого соответствия адресной строки с другими адресными строками во 2-м DF, но только для тех линий, где округа совпадают между обоими DF. Оттуда я планирую объединить два dfs, один по нечеткому согласованному адресу и столбец адресной строки во втором DF. Надеюсь, это не звучит запутанно.
1 ответ
Вы могли бы адаптировать свой fuzzy_match функция для получения идентификатора в качестве переменной и использования его для подстановки вашего выбора перед выполнением нечеткого поиска (обратите внимание, что для этого требуется применять функцию ко всему фрейму данных, а не только к столбцу адресов)
def fuzzy_match(x, choices, scorer, cutoff):
match = process.extractOne(x['Address1'],
choices=choices.loc[choices['ID'] == x['ID'],
'Address1'],
scorer=scorer,
score_cutoff=cutoff)
if match:
return match[0]
test['FuzzyAddress1'] = test.apply(fuzzy_match,
args=(test2, fuzz.ratio, 80),
axis=1)