Обнаружение и получение кодовых точек и суррогатов из строки Delphi
Я пытаюсь лучше понять суррогатные пары и реализацию Unicode в Delphi.
Если я вызову length() для строки Unicode S:= 'Ĥà̲V̂e' в Delphi, я вернусь, 8.
Это связано с тем, что длины отдельных символов [Ĥ],[à̲],[V̂] и [e] равны 2, 3, 2 и 1 соответственно. Это потому, что у Ĥ есть суррогат, у ̲ есть два дополнительных суррогата, у V ̂ есть суррогат, а у e нет суррогатов.
Если бы я хотел вернуть второй элемент в строке, включая все суррогаты, [à̲], как бы я это сделал? Я знаю, что мне нужно было бы провести какое-то тестирование отдельных байтов. Я провел несколько тестов, используя рутину
function GetFirstCodepointSize(const S: UTF8String): Integer;
упоминается в этом вопросе.
но получил некоторые необычные результаты, например, вот некоторые длины и размеры некоторых разных кодовых точек. Ниже приведен фрагмент того, как я генерировал эти таблицы.
...
UTFCRUDResultStrings.add('INPUT: '+#9#9+ DATA +#9#9+ 'GetFirstCodePointSize = ' +intToStr(GetFirstCodepointSize(DATA))
+#9#9+ 'Length =' + intToStr(length(DATA)));
...
Первый набор: это имеет смысл для меня, каждый размер кодовой точки удваивается, но это один символ каждый, и Delphi дает мне длину всего 1, идеально.
INPUT: ď GetFirstCodePointSize = 2 Length =1
INPUT: ơ GetFirstCodePointSize = 2 Length =1
INPUT: ǥ GetFirstCodePointSize = 2 Length =1
Второй сет: мне изначально кажется, что длины и кодовые точки поменялись местами? Я предполагаю, что причина этого в том, что символы + суррогаты обрабатываются индивидуально, следовательно, первый размер кодовой точки для "H", который равен 1, но длина возвращает длины "H" плюс "^".
INPUT: Ĥ GetFirstCodePointSize = 1 Length =2
INPUT: à̲ GetFirstCodePointSize = 1 Length =3
INPUT: V̂ GetFirstCodePointSize = 1 Length =2
INPUT: e GetFirstCodePointSize = 1 Length =1
Некоторые дополнительные тесты...
INPUT: ¼ GetFirstCodePointSize = 2 Length =1
INPUT: ₧ GetFirstCodePointSize = 3 Length =1
INPUT: GetFirstCodePointSize = 4 Length =2
INPUT: ß GetFirstCodePointSize = 2 Length =1
INPUT: GetFirstCodePointSize = 4 Length =2
Есть ли надежный способ в Delphi определить, где начинается и заканчивается элемент в строке Unicode?
Я знаю, что моя терминология, использующая элемент word, может быть отключена, но я не думаю, что кодовая точка и символ также правильны, особенно учитывая, что один элемент может иметь размер кодовой точки 3, но иметь длину только один.
2 ответа
Я пытаюсь лучше понять суррогатные пары и реализацию Unicode в Delphi.
Давайте уберем терминологию.
Каждому "символу" (известному как графема), который определяется Unicode, присваивается уникальный код.
В кодировке UTF - UTF-7, UTF-8, UTF-16 и UTF-32 - каждая кодовая точка кодируется как последовательность кодовых единиц. Размер каждого кодового блока определяется кодированием - 7 бит для UTF-7, 8 бит для UTF-8, 16 бит для UTF-16 и 32 бита для UTF-32 (отсюда и их названия).
В Delphi 2009 и позже String это псевдоним для UnicodeString, а также Char это псевдоним для WideChar, WideChar 16 бит. UnicodeString содержит строку в кодировке UTF-16 (в более ранних версиях Delphi эквивалентный тип строки был WideString) и каждый WideChar кодовый блок UTF-16
В UTF-16 кодовая точка может быть закодирована с использованием 1 или 2 кодовых единиц. 1 кодовый блок может кодировать значения кодовых точек в диапазоне базовой многоязычной плоскости (BMP) - от $0000 до $FFFF включительно. Для более высоких кодовых точек требуется 2 кодовых блока, которые также называются суррогатной парой.
Если я вызову length() для строки Unicode S:= 'Ĥà̲V̂e' в Delphi, я вернусь, 8.
Это связано с тем, что длины отдельных символов [Ĥ],[à̲],[V̂] и [e] равны 2, 3, 2 и 1 соответственно.
Это потому, что у Ĥ есть суррогат, у ̲ есть два дополнительных суррогата, у V ̂ есть суррогат, а у e нет суррогатов.
Да, есть 8 WideChar элементы (кодовые блоки) в вашем UTF-16 UnicodeString, То, что вы называете "суррогатами", на самом деле называют "объединяющими знаками". Каждый объединяющий знак представляет собой свою собственную уникальную кодовую точку и, следовательно, свою собственную последовательность кодовых единиц.
Если бы я хотел вернуть второй элемент в строке, включая все суррогаты, [à̲], как бы я это сделал?
Вы должны начать в начале UnicodeString и проанализировать каждый WideChar пока вы не найдете тот, который не является объединяющим знаком, прикрепленным к предыдущему WideChar, В Windows самый простой способ сделать это - использовать CharNextW() функция, например:
var
S: String;
P: PChar;
begin
S := 'Ĥà̲V̂e';
P := CharNext(PChar(S)); // returns a pointer to à̲
end;
Delphi RTL не имеет эквивалентной функции. Вы должны были бы написать один вручную или использовать стороннюю библиотеку. У RTL есть StrNextChar() функция, но она обрабатывает только суррогаты UTF-16, не объединяя метки (CharNext() обрабатывает оба). Итак, вы могли бы использовать StrNextChar() сканировать каждую кодовую точку в UnicodeString, но вы должны искать в каждой кодовой точке, чтобы знать, является ли это комбинационной меткой или нет, например:
uses
Character;
function MyCharNext(P: PChar): PChar;
begin
if (P <> nil) and (P^ <> #0) then
begin
Result := StrNextChar(P);
while GetUnicodeCategory(Result^) = ucCombiningMark do
Result := StrNextChar(Result);
end else begin
Result := nil;
end;
end;
var
S: String;
P: PChar;
begin
S := 'Ĥà̲V̂e';
P := MyCharNext(PChar(S)); // should return a pointer to à̲
end;
Я знаю, что мне нужно было бы провести какое-то тестирование отдельных байтов.
Не байты, а кодовые точки, которые они представляют при декодировании.
Я провел несколько тестов, используя рутину
Функция GetFirstCodepointSize(const S: UTF8String): целое число
Посмотрите внимательно на эту функцию подписи. Видите тип параметра? Это строка UTF-8, а не строка UTF-16. Об этом даже говорилось в ответе, от которого вы получили эту функцию:
Вот пример, как разобрать строку UTF8
UTF-8 и UTF-16 - очень разные кодировки и, следовательно, имеют разную семантику. Вы не можете использовать семантику UTF-8 для обработки строки UTF-16 и наоборот.
Есть ли надежный способ в Delphi определить, где начинается и заканчивается элемент в строке Unicode?
Не напрямую. Вы должны проанализировать строку с самого начала, пропуская элементы по мере необходимости, пока не дойдете до нужного элемента. Помните, что каждая кодовая точка может быть закодирована как 1 или 2 элемента кодового блока, и каждый логический глиф может быть закодирован с использованием нескольких кодовых точек (и, следовательно, нескольких последовательностей кодовых блоков).
Я знаю, что моя терминология, использующая элемент word, может быть отключена, но я не думаю, что кодовая точка и символ также правильны, особенно учитывая, что один элемент может иметь размер кодовой точки 3, но иметь длину только один.
1 глиф состоит из 1+ кодовых точек, и каждая кодовая точка кодируется как 1+ кодовых единиц.
Может ли кто-нибудь реализовать следующую функцию?
function GetElementAtIndex (S: String; StrIdx: Integer): String;
Попробуйте что-то вроде этого:
uses
SysUtils, Character;
function MyCharNext(P: PChar): PChar;
begin
Result := P;
if Result <> nil then
begin
Result := StrNextChar(Result);
while GetUnicodeCategory(Result^) = ucCombiningMark do
Result := StrNextChar(Result);
end;
end;
function GetElementAtIndex(S: String; StrIdx : Integer): String;
var
pStart, pEnd: PChar;
begin
Result := '';
if (S = '') or (StrIdx < 0) then Exit;
pStart := PChar(S);
while StrIdx > 1 do
begin
pStart := MyCharNext(pStart);
if pStart^ = #0 then Exit;
Dec(StrIdx);
end;
pEnd := MyCharNext(pStart);
{$POINTERMATH ON}
SetString(Result, pStart, pEnd-pStart);
end;
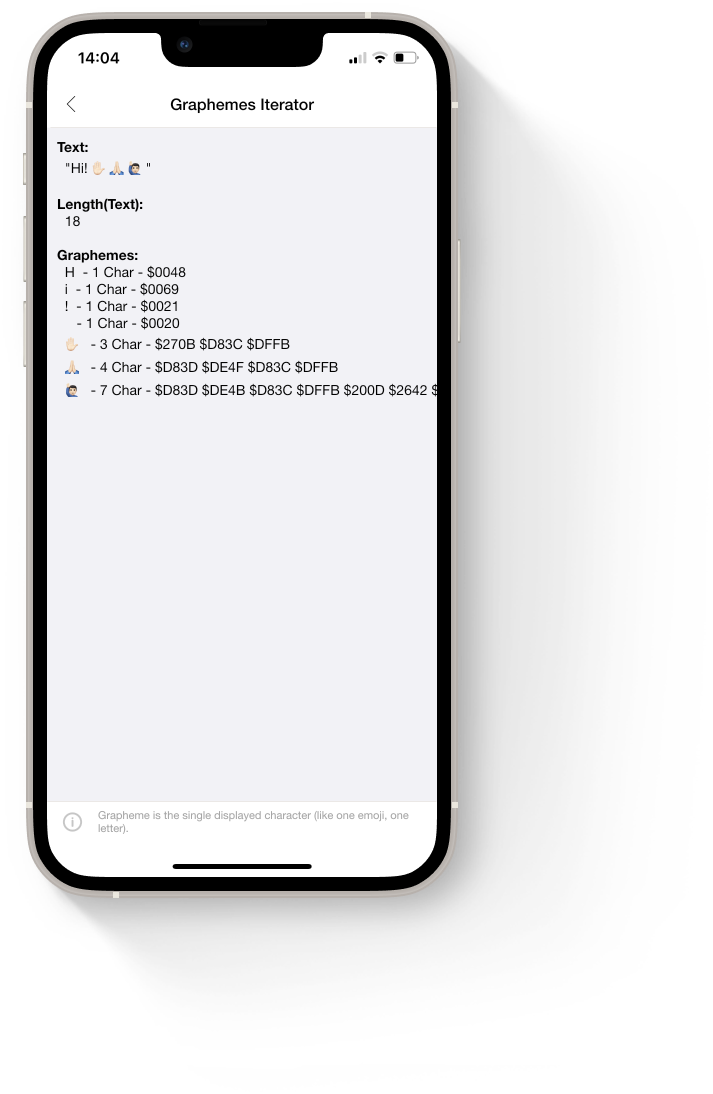
Циклическое перебор графем строки может быть сложнее, чем вы думаете. В Unicode 13 некоторые графемы имеют длину до 14 байт. Советую для этого использовать стороннюю библиотеку. Одним из лучших для этого является Skia4Delphi: https://github.com/skia4delphi/skia4delphi .
Код очень прост:
var LUnicode: ISkUnicode := TSkUnicode.Create;
for var LGrapheme: string in LUnicode.GetBreaks('Text', TSkBreakType.Graphemes) do
Showmessage(LGrapheme);
В самой демке библиотеки также есть пример итератора графем. Смотреть: