Отображение панд: усечение столбца, а не перенос
С длинными именами столбцов DataFrames будут отображаться в очень грязной форме, казалось бы, независимо от того, какие параметры установлены.
Информация: Я нахожусь в Jupyter QtConsole, pandas 0.20.1, со следующими соответствующими параметрами, указанными при запуске:
pd.set_option('display.max_colwidth', 20)
pd.set_option('expand_frame_repr', False)
pd.set_option('display.max_rows', 25)
Вопрос: как я могу обрезать DataFrame при необходимости вместо переноса столбцов на следующую строку, сохраняя при этом expand_frame_repr=False?
Вот пример. Опять же, проблема не зависит от количества столбцов, а от длины столбцов.
Это не вызовет проблемы:
df = pd.DataFrame(np.random.randn(1000, 1000),
columns=['col' + str(i) for i in range(1000)])
Поскольку вывод отлично читается и выглядит так: 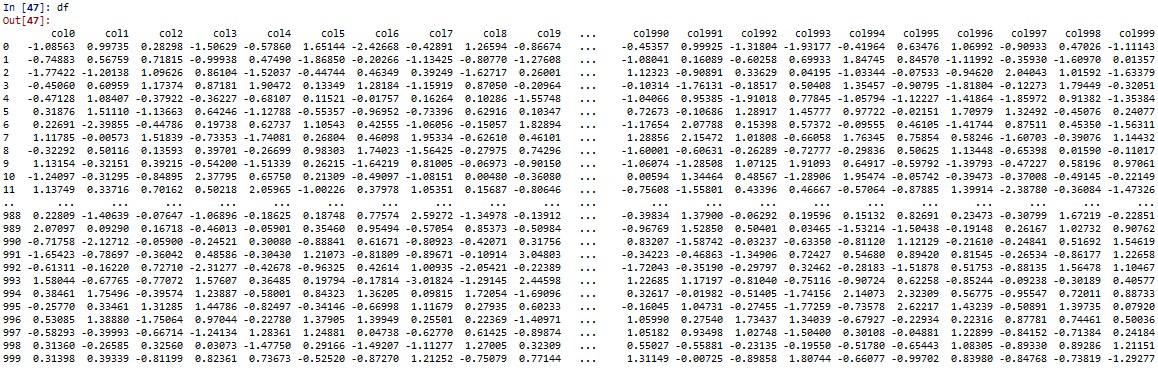
Тот же самый DataFrame с длинными именами столбцов вызывает проблему, о которой я говорю:
df = pd.DataFrame(np.random.randn(1000, 1000),
columns=['very_long_col_name_'
+ str(i) for i in range(1000)])
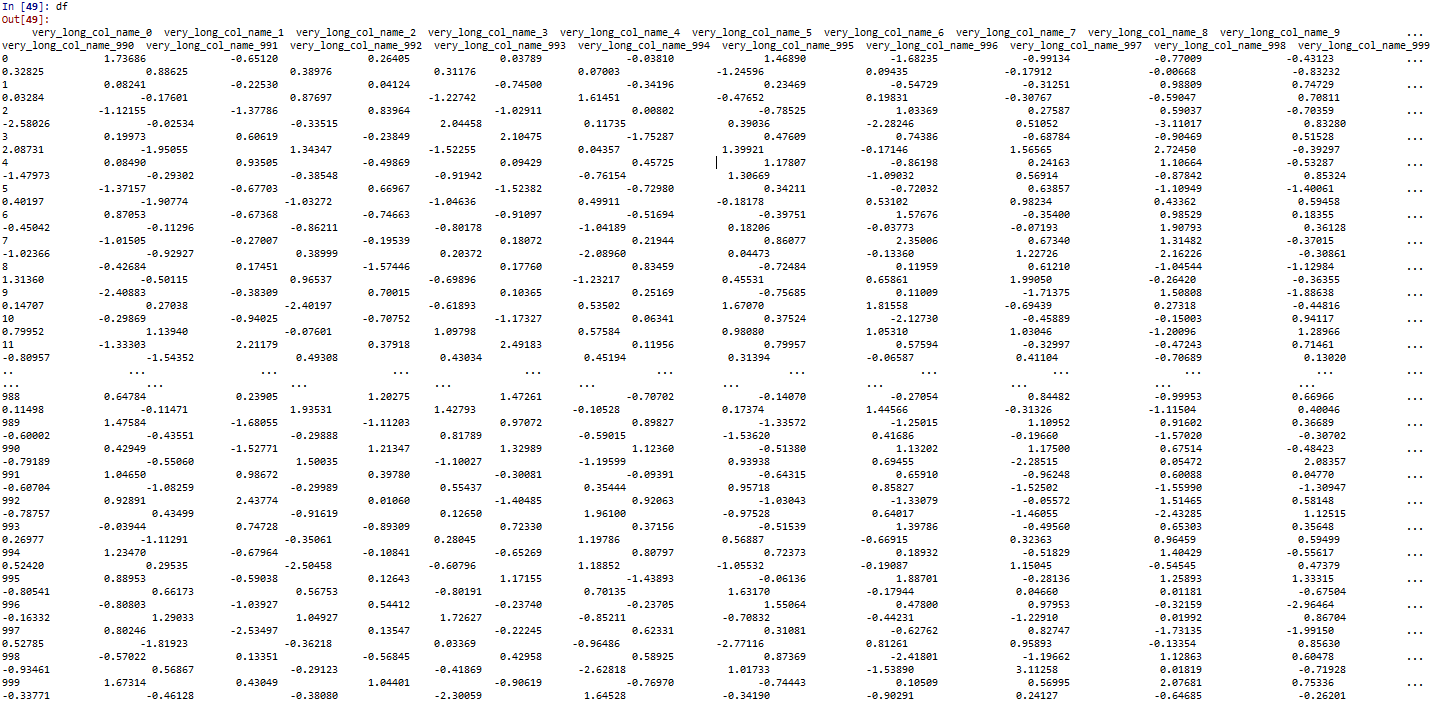
Есть ли способ, чтобы второй вывод соответствовал первому, который мне не хватает? (Через указание параметра, а не через использование .iloc каждый раз хочу посмотреть.)
3 ответа
Похоже, это потребует улучшения. Соответствующий код в repr функция, кажется, здесь:
max_rows = get_option("display.max_rows")
max_cols = get_option("display.max_columns")
show_dimensions = get_option("display.show_dimensions")
if get_option("display.expand_frame_repr"):
width, _ = console.get_console_size()
else:
width = None
self.to_string(buf=buf, max_rows=max_rows, max_cols=max_cols,
line_width=width, show_dimensions=show_dimensions)
Так что либо вы проходите expand_frame_repr=True и он оборачивается на ширину линии, или вы передаете expand_frame_repr=False и это не должно Но похоже, что в коде есть ошибка (это должна быть pandas 0.20.3 iirc):
в pd.io.formats.format.DataFrameFormatter:
def _chk_truncate(self):
"""
Checks whether the frame should be truncated. If so, slices
the frame up.
"""
from pandas.core.reshape.concat import concat
# Column of which first element is used to determine width of a dot col
self.tr_size_col = -1
# Cut the data to the information actually printed
max_cols = self.max_cols
max_rows = self.max_rows
if max_cols == 0 or max_rows == 0: # assume we are in the terminal
# (why else = 0)
(w, h) = get_terminal_size()
self.w = w
self.h = h
if self.max_rows == 0:
dot_row = 1
prompt_row = 1
if self.show_dimensions:
show_dimension_rows = 3
n_add_rows = (self.header + dot_row + show_dimension_rows +
prompt_row)
# rows available to fill with actual data
max_rows_adj = self.h - n_add_rows
self.max_rows_adj = max_rows_adj
# Format only rows and columns that could potentially fit the
# screen
if max_cols == 0 and len(self.frame.columns) > w:
max_cols = w
if max_rows == 0 and len(self.frame) > h:
max_rows = h
Похоже, он собирался сделать то, что хотел, но был незаконченным. Это проверка max_cols от количества столбцов, а не от общей ширины столбцов.
Таким образом, вы можете создать show_df функция, которая будет рассчитывать правильное количество столбцов и показывать его в option_context например, ответ pi2Squared или исправьте его здесь (и, возможно, отправьте патч, если он вам нужен).
Использование max_columns
from string import ascii_letters
df = pd.DataFrame(np.random.randint(10, size=(5, 52)), columns=list(ascii_letters))
with pd.option_context(
'display.max_colwidth', 20,
'expand_frame_repr', False,
'display.max_rows', 25,
'display.max_columns', 5,
):
print(df.add_prefix('really_long_column_name_'))
really_long_column_name_a really_long_column_name_b ... really_long_column_name_Y really_long_column_name_Z
0 8 1 ... 1 9
1 8 5 ... 2 1
2 5 0 ... 9 9
3 6 8 ... 0 9
4 1 2 ... 7 1
[5 rows x 52 columns]
Другая идея... Очевидно, не совсем то, что вы хотите, но, возможно, вы можете изменить его в соответствии с вашими потребностями.
d1 = df.add_suffix('_really_long_column_name')
with pd.option_context('display.max_colwidth', 4, 'expand_frame_repr', False):
mw = pd.get_option('display.max_colwidth')
print(d1.rename(columns=lambda x: x[:mw-3] + '...' if len(x) > mw else x))
a... b... c... d... e... f... g... h... i... j... ... Q... R... S... T... U... V... W... X... Y... Z...
0 6 5 5 5 8 3 5 0 7 6 ... 9 0 6 9 6 8 4 0 6 7
1 0 5 4 7 2 5 4 3 8 7 ... 8 1 5 3 5 9 4 5 5 3
2 7 2 1 6 5 1 0 1 3 1 ... 6 7 0 9 9 5 2 8 2 2
3 1 8 7 1 4 5 5 8 8 3 ... 3 6 5 7 1 0 8 1 4 0
4 7 5 6 2 4 9 7 9 0 5 ... 6 8 1 6 3 5 4 2 3 2
Как уже отмечали другие, сама Панда здесь, кажется, прослушивается или плохо спроектирована, поэтому требуется обходной путь.
В большинстве случаев эта проблема возникает с числовыми столбцами, так как числа относительно короткие. Pandas разделит заголовок столбца на несколько строк, если в нем есть пробелы, поэтому вы можете "взломать" правильное поведение, вставляя пробелы в заголовки столбцов для числовых столбцов при отображении кадра данных. У меня есть один вкладыш, чтобы сделать это:
def colfix(df, L=5): return df.rename(columns=lambda x: ' '.join(x.replace('_', ' ')[i:i+L] for i in range(0,len(x),L)) if df[x].dtype in ['float64','int64'] else x )
отображать свой фрейм данных, просто наберите
colfix(your_df)
обратите внимание, что переименование не приведет к постоянному изменению кадра данных, оно только добавит пробелы к именам для целей его отображения один раз.
Результаты (в тетради Jupyter):
С colfix:

Без:
