Regex, чтобы изменить на случай предложения
Я использую Notepad++ для замены текста в языковом файле из 5453 строк. Формат строк файла:
variable.name = Variable Value Over Here, that''s for sure, Really
Двойной апостроф является намеренным.
Мне нужно преобразовать значение в регистр предложений, за исключением слов "Здесь" и "Действительно", которые являются правильными и должны оставаться заглавными. Как вы можете видеть, регистр внутри значения обычно смешан для начала.
Я немного поработал над этим. Все, что у меня есть, это:
(. )([A-Z])(.+)
который, кажется, по крайней мере, выбрать правильные строки. Часть замены - то, где я борюсь.
4 ответа
Замена регулярных выражений не может выполнять функцию (например, использование заглавных букв) для совпадений. Вы должны будете написать это, например, на PHP или JavaScript.
Обновление: см. Ответ Джонаса.
Я создал веб-страницу под названием Text Utilities, чтобы делать такие вещи:
- вставьте свой текст
- перейдите в "Найти, регулярное выражение и заменить" (или нажмите Ctrl+Shift+F)
- введите свое регулярное выражение (мой будет
^(.*?\=\s*\w)(.*)$) - отметьте опцию "^$ match limit"
- выберите "Применить функцию JS к совпадениям"
- добавьте аргументы (сначала совпадение, затем подчиненные шаблоны), здесь
s, start, rest - изменить оператор возврата на
return start + rest.toLowerCase();
Последняя функция в текстовой области выглядит следующим образом:
return function (s, start, rest) {
return start + rest.toLowerCase();
};
Может быть, добавить код для заглавных букв некоторых слов, таких как "Действительно" и "Здесь".
Find: (. )([A-Z])(.+)
Replace: \1\U\2\L\3
В Notepad++ 6.0 или выше (который поставляется со встроенной поддержкой PCRE).
В Notepad++ вы можете использовать плагин PythonScript для выполнения этой работы. Если вы устанавливаете плагин, создайте новый скрипт следующим образом:
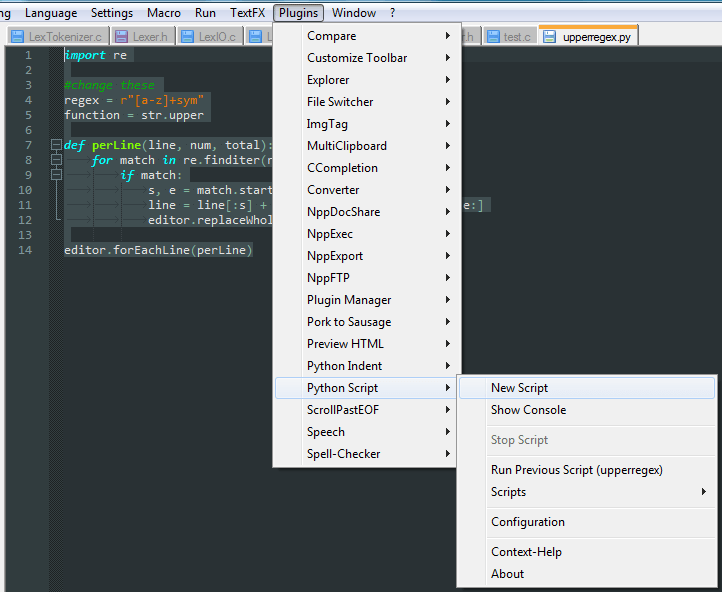
Затем вы можете использовать следующий скрипт, заменив переменные регулярного выражения и функции по своему усмотрению:
import re
#change these
regex = r"[a-z]+sym"
function = str.upper
def perLine(line, num, total):
for match in re.finditer(regex, line):
if match:
s, e = match.start(), match.end()
line = line[:s] + function(line[s:e]) + line[e:]
editor.replaceWholeLine(num, line)
editor.forEachLine(perLine)
Этот конкретный пример работает, находя все совпадения в определенной строке, затем применяя функцию каждое совпадение. Если вам нужна многострочная поддержка, сценарий Python "Conext-Help" объясняет все предлагаемые функции, включая функции pymlsearch / pymlreplace, определенные в объекте editor.
Когда вы будете готовы запустить ваш скрипт, сначала перейдите к файлу, который вы хотите запустить, затем перейдите к "Scripts >" в меню Python Script и запустите свой.
Примечание: хотя вы, вероятно, сможете использовать функцию отмены notepad++, если запутаетесь, было бы неплохо сначала поместить текст в другой файл, чтобы убедиться, что он работает.
PS Вы можете "найти" и "пометить" каждое вхождение регулярного выражения, используя встроенный диалог поиска notepad++, и, если бы вы могли выбрать их все, вы могли бы использовать функциональность TextFX "Characters->UPPER CASE" для этой конкретной проблемы, но я Я не уверен, как перейти от отмеченного или найденного текста к выделенному тексту. Но я думал, что опубликую это, если кто-нибудь сделает...
Изменить: В Notepad++ 6.0 или более поздней версии вы можете использовать "Поиск / замена регулярных выражений, совместимых с Perl) (источник: http://sourceforge.net/apps/mediawiki/notepad-plus/?title=Regular_Expressions). были решены с помощью регулярных выражений, таких как (. )([A-z])(.+) с аргументом замены, как \1\U\2\3,
Спрашивающий имел в виду очень конкретный случай. Как общее "изменение в предложении" в notepad++, первое предложение регулярного выражения не сработало для меня должным образом. хотя и не идеальный, вот измененная версия, которая стала большим улучшением оригинала для моих целей:
find: ([\.\r\n][ ]*)([A-Za-z\r])([^\.^\r^\n]+)
replace: \1\U\2\L\3
У вас все еще есть проблема с существительными в нижнем регистре, именами, датами, странами и т. Д., Но хорошая проверка орфографии может помочь с этим.