Опция nvprof для пропускной способности
Как правильно выбрать измерение полосы пропускания с помощью nvprof --metrics из командной строки? Я использую flop_dp_efficiency для получения процента пиковых значений FLOPS, но в руководстве, похоже, есть много вариантов измерения пропускной способности, которые я не совсем понимаю, что я измеряю. Например, dram_read, dram_write, gld_read, gld_write выглядят одинаково для меня. Кроме того, я должен сообщить о пропускной способности как сумма пропускной способности чтения + записи, предполагая, что оба происходят одновременно?
Редактировать:
Основываясь на превосходном ответе на диаграмме, какова будет пропускная способность, идущая от памяти устройства к ядру? Я думаю взять минимальную пропускную способность (чтение + запись) на пути от ядра к памяти устройства, которая, вероятно, перетаскивается в кэш L2.
Я пытаюсь определить, привязано ли ядро к вычислениям или памяти, измеряя FLOPS и пропускную способность.
1 ответ
Чтобы понять метрики профилировщика в этой области, необходимо иметь представление о модели памяти в графическом процессоре. Я считаю полезной диаграмму, опубликованную в документации по выпуску Nsight Visual Studio. Я разметил диаграмму с помощью пронумерованных стрелок, которые относятся к пронумерованным метрикам (и направлению передачи), которые я перечислил ниже:
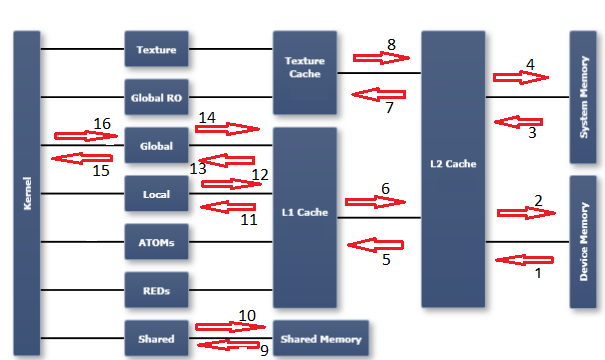
Пожалуйста, обратитесь к справочнику метрик CUDA для описания каждой метрики:
- dram_read_throughput, dram_read_transactions
- dram_write_throughput, dram_write_transactions
- sysmem_read_throughput, sysmem_read_transactions
- sysmem_write_throughput, sysmem_write_transactions
- l2_l1_read_transactions, l2_l1_read_throughput
- l2_l1_write_transactions, l2_l1_write_throughput
- l2_tex_read_transactions, l2_texture_read_throughput
- текстура доступна только для чтения, по этому пути транзакции невозможны
- shared_load_throughput, shared_load_transactions
- shared_store_throughput, shared_store_transactions
- l1_cache_local_hit_rate
- l1 - сквозной кэш, поэтому для этого пути нет (независимых) метрик - обратитесь к другим локальным метрикам
- l1_cache_global_hit_rate
- см. примечание о 12
- gld_efficiency, gld_throughput, gld_transactions
- gst_efficiency, gst_throughput, gst_transactions
Заметки:
- Стрелка справа налево указывает на активность чтения. Стрелка слева направо указывает на активность записи.
- "глобальный" - это логическое пространство. Это относится к логическому адресному пространству с точки зрения программистов. Транзакции, направленные на "глобальное" пространство, могут оказаться в одном из кешей, в системном хранилище или в памяти устройства (драм). "Драм", с другой стороны, является физическим объектом (как, например, кэши L1 и L2). "Логические пространства" все изображены в первом столбце диаграммы непосредственно справа от столбца "ядра". Остальные столбцы справа - это физические объекты или ресурсы.
- Я не пытался пометить каждую возможную метрику памяти местоположением на графике. Надеюсь, эта таблица будет поучительной, если вам нужно выяснить другие.
С приведенным выше описанием, возможно, ваш вопрос все еще не может быть дан ответ. Тогда вам необходимо уточнить ваш запрос - "что вы хотите точно измерить?" Однако, исходя из написанного вопроса, вы, вероятно, захотите взглянуть на показатели dram_xxx, если вас интересует фактическая пропускная способность используемой памяти.
Кроме того, если вы просто пытаетесь получить оценку максимальной доступной пропускной способности памяти, используя пример кода CUDA bandwidthTest это, вероятно, самый простой способ получить измерение прокси для этого. Просто используйте указанное число устройств для определения пропускной способности устройства, чтобы оценить максимальную пропускную способность памяти, доступную для вашего кода.
Объединяя вышеприведенные идеи, метрика dram_utilization дает масштабированный результат, который представляет часть (от 0 до 10) общей доступной пропускной способности памяти, которая была фактически использована.