Экстраполировать схожесть предложений с учетом сходства слов
Предполагая, что у меня есть оценка сходства слов для каждой пары слов в двух предложениях, каков достойный подход к определению общего сходства предложений по этим оценкам?
Оценка слов рассчитывается с использованием косинусного сходства из векторов, представляющих каждое слово.
Теперь, когда у меня есть отдельные оценки слов, слишком ли наивно суммировать отдельные оценки слов и делить их на общее количество слов в обоих предложениях, чтобы получить оценку для двух предложений?
Я читал о дальнейшем построении векторов для представления предложений, используя оценки слов, а затем снова использовал косинусное сходство для сравнения предложений. Но я не знаком с тем, как построить векторы предложений из существующих оценок слов. Также я не знаю, какие компромиссы сравниваются с наивным подходом, описанным выше, который, по крайней мере, я легко могу понять.:).
Любые идеи с благодарностью.
Благодарю.
2 ответа
В итоге я взял среднее значение каждого набора векторов, а затем применил косинусное сходство к двум средним значениям, в результате чего получил оценку за предложения.
Я не уверен, насколько математически звучит этот подход, но я видел, как это делалось в других местах (например, в gensim Python).
Лучше использовать контекстные вложения слов (векторные представления) для слов.
Вот подход к схожести предложений с помощью попарного сходства слов: BERTScore.
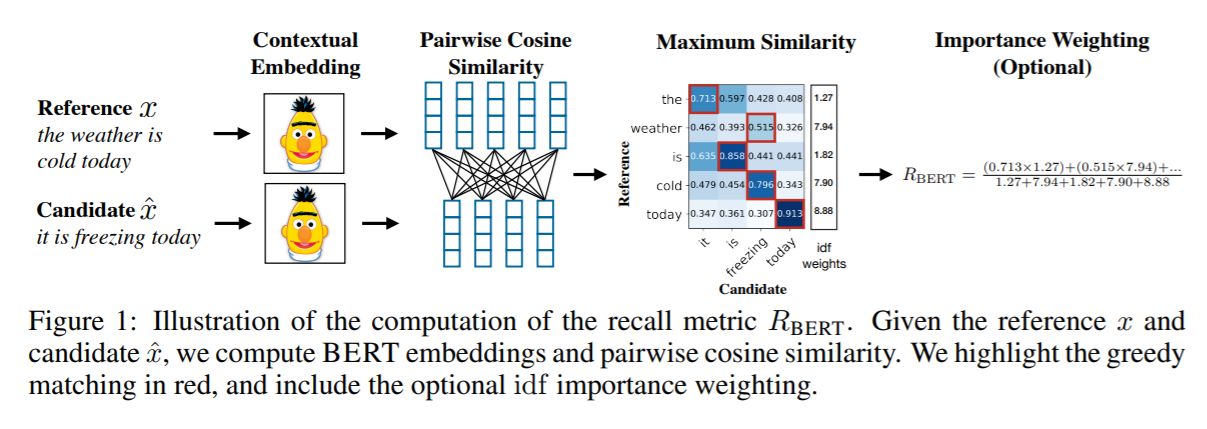
Вы можете проверить математику здесь .