Код сборки против машинного кода против объектного кода?
В чем разница между объектным кодом, машинным кодом и кодом сборки?
Можете ли вы привести наглядный пример их различия?
8 ответов
Машинный код - это двоичный код (1 и 0), который может выполняться непосредственно процессором. Если бы вы открыли файл машинного кода в текстовом редакторе, вы бы увидели мусор, включая непечатные символы (нет, не те непечатные символы;)).
Объектный код - это часть машинного кода, которая еще не была связана в законченную программу. Это машинный код для одной конкретной библиотеки или модуля, который будет составлять готовый продукт. Он также может содержать заполнители или смещения, не найденные в машинном коде завершенной программы. Компоновщик будет использовать эти заполнители и смещения, чтобы соединить все вместе.
Код сборки представляет собой простой текстовый и (в некоторой степени) читаемый исходный код, который в основном имеет прямой аналог 1:1 с машинными инструкциями. Это достигается с помощью мнемоники для фактических инструкций, регистров или других ресурсов. Примеры включают JMP а также MULT для команд перехода и умножения процессора. В отличие от машинного кода, процессор не понимает ассемблерный код. Вы преобразуете ассемблерный код в машину с использованием ассемблера или компилятора, хотя мы обычно думаем о компиляторах в сочетании с языком программирования высокого уровня, который абстрагируется дальше от инструкций процессора.
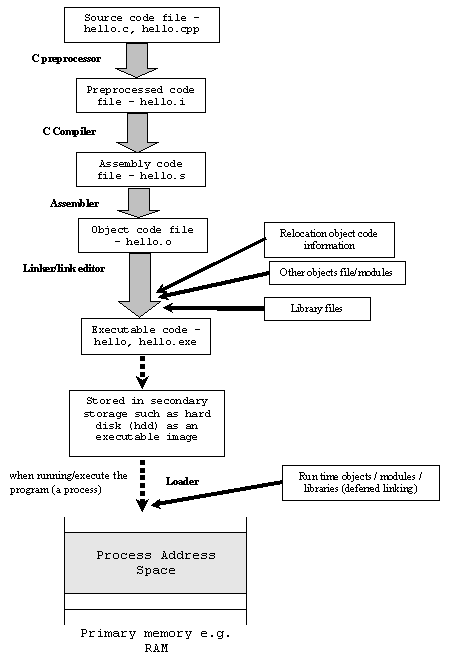
Создание полной программы включает в себя написание исходного кода для программы либо на ассемблере, либо на языке более высокого уровня, например C++. Исходный код собирается (для ассемблерного кода) или компилируется (для языков более высокого уровня) в объектный код, а отдельные модули связываются вместе, чтобы стать машинным кодом для конечной программы. В случае очень простых программ этап связывания может не понадобиться. В других случаях, например, в IDE (интегрированная среда разработки), компоновщик и компилятор могут вызываться вместе. В других случаях может использоваться сложный сценарий make или файл решения, чтобы сообщить среде, как создать окончательное приложение.
Есть также интерпретируемые языки, которые ведут себя по-разному. Интерпретируемые языки полагаются на машинный код специальной программы переводчика. На базовом уровне интерпретатор анализирует исходный код и немедленно преобразует команды в новый машинный код и выполняет их. Современные интерпретаторы, иногда называемые средой выполнения или виртуальной машиной, намного сложнее: оценивать целые разделы исходного кода за раз, кэшировать и оптимизировать, где это возможно, и обрабатывать сложные задачи управления памятью. Интерпретированный язык также может быть предварительно скомпилирован на промежуточный язык или байт-код более низкого уровня, аналогично ассемблерному коду.
Другие ответы дали хорошее описание разницы, но вы также попросили визуальный. Вот диаграмма, показывающая, как они переходят от кода C к исполняемому файлу.
Ассемблерный код представляет собой удобочитаемое представление машинного кода:
mov eax, 77
jmp anywhere
Машинный код - это чистый шестнадцатеричный код:
5F 3A E3 F1
Я предполагаю, что вы имеете в виду объектный код, как в объектном файле. Это вариант машинного кода с той разницей, что переходы параметризованы так, что компоновщик может их заполнить.
Ассемблер используется для преобразования ассемблерного кода в машинный код (объектный код). Линкер связывает несколько файлов объектов (и библиотек) для создания исполняемого файла.
Однажды я написал программу на ассемблере в чистом шестнадцатеричном формате (ассемблер не доступен), к счастью, это было в далеком старом (старом) 6502. Но я рад, что есть ассемблеры для кодов операций Pentium.
8B 5D 32 это машинный код
mov ebx, [ebp+32h] это сборка
lmylib.so содержащий 8B 5D 32 это объектный код
Исходный код, код сборки, машинный код, объектный код, байт-код, исполняемый файл и файл библиотеки.
Все эти термины часто вводят многих людей в заблуждение тем, что они думают, что они взаимоисключающие. Смотрите схему, чтобы понять их отношения. Описание каждого термина приведено ниже.
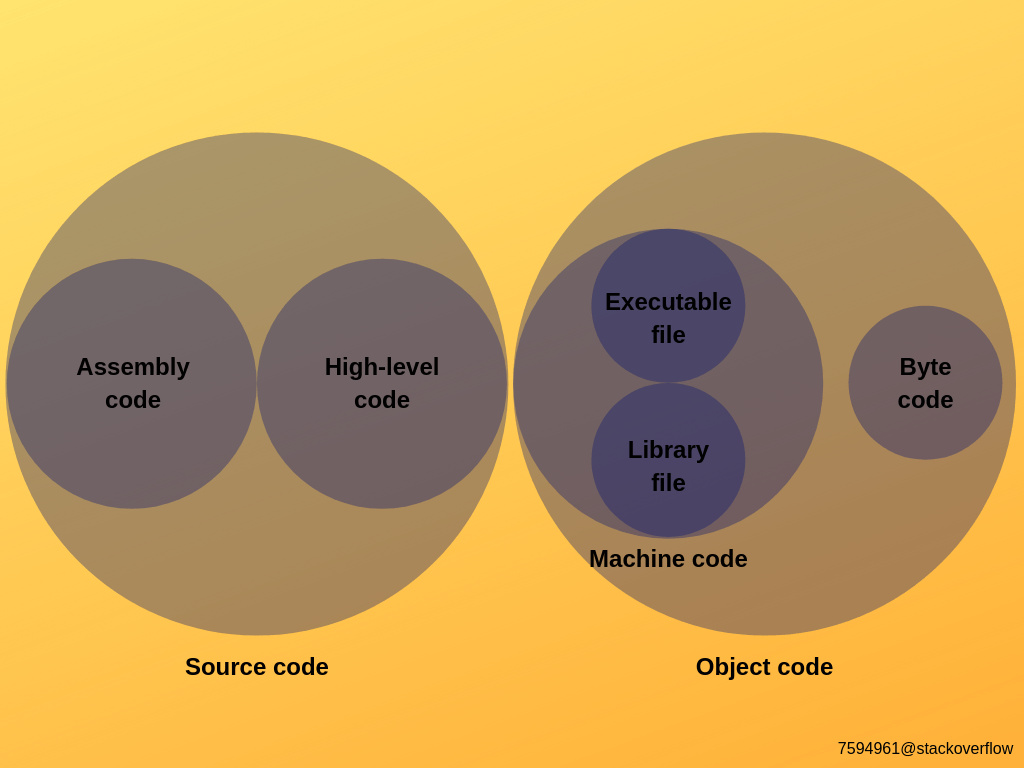
Исходный код
Инструкции на человекочитаемом (программирующем) языке
Код высокого уровня
Инструкции, написанные на языке высокого уровня (программирования)
например, программы на C, C++ и Java
Код сборки
Инструкции написаны на ассемблере (разновидность низкоуровневого языка программирования). В качестве первого шага процесса компиляции высокоуровневый код преобразуется в эту форму. Это код сборки, который затем преобразуется в фактический машинный код. В большинстве систем эти два шага выполняются автоматически как часть процесса компиляции.
например, program.asm
Код объекта
Продукт процесса компиляции. Это может быть в форме машинного кода или байтового кода.
например, file.o
Машинный код
Инструкции на машинном языке.
например,
Байт код
Инструкция в промежуточной форме, которая может быть выполнена таким переводчиком, как JVM.
например, файл класса Java
Запускаемый файл
Продукт связывания процесса. Это машинный код, который может напрямую выполняться процессором.
например, файл.exe.
Обратите внимание, что в некоторых контекстах файл, содержащий байт-код или инструкции языка сценариев, также может считаться исполняемым.
Библиотечный файл
Некоторый код скомпилирован в эту форму по разным причинам, таким как возможность повторного использования и позднее используется исполняемыми файлами.
Еще один момент, о котором не упоминалось, это то, что существует несколько различных типов кода сборки. В самой основной форме все числа, используемые в инструкциях, должны быть указаны как константы. Например:
1902 долл. США: 37 долл. США 14 долл. США: 1437 долл. США, 1905 долл. США: 85 03 долл. США: 03 долл. США 1907 долл. США: 85 09 долл. США: 09 долл. США 1909 долл. США: СА: 190 долл. США ДЕКАБРЯ: 10 долл. США: 1902 долл. США
Приведенный выше фрагмент кода, если он хранится по адресу $1900 в картридже Atari 2600, будет отображать количество строк разного цвета, извлеченных из таблицы, которая начинается по адресу $1437. На некоторых инструментах ввод адреса вместе с крайней правой частью строки выше сохранял бы в памяти значения, показанные в среднем столбце, и начинал следующую строку со следующего адреса. Ввод кода в такой форме был намного удобнее, чем ввод в шестнадцатеричном формате, но нужно было знать точные адреса всего.
Большинство ассемблеров позволяют использовать символические адреса. Приведенный выше код будет написан больше как:
rainbow_lp: lda ColorTbl, x Sta WSYNC Sta COLUBK Dex bpl rainbow_lp
Ассемблер автоматически настроит инструкцию LDA, чтобы она ссылалась на любой адрес, сопоставленный с меткой ColorTbl. Использование этого стиля ассемблера значительно облегчает написание и редактирование кода, чем это было бы возможно, если бы пришлось вручную и вручную поддерживать все адреса.
Сборка - это короткие описательные термины, которые могут понять люди, которые могут быть непосредственно переведены в машинный код, который фактически использует процессор.
Хотя ассемблер несколько понятен людям, он все еще находится на низком уровне. Требуется много кода, чтобы сделать что-нибудь полезное.
Таким образом, вместо этого мы используем языки более высокого уровня, такие как C, BASIC, FORTAN (хорошо, я знаю, что встречался сам). При компиляции они производят объектный код. Ранние языки имели машинный язык в качестве объектного кода.
Сегодня многие языки, такие как JAVA и C#, обычно компилируются в байт-код, который не является машинным кодом, а легко интерпретируется во время выполнения для создания машинного кода.
Код сборки обсуждается здесь.
"Ассемблер является языком низкого уровня для программирования компьютеров. Он реализует символическое представление числовых машинных кодов и других констант, необходимых для программирования конкретной архитектуры ЦП".
Машинный код обсуждается здесь.
"Машинный код или машинный язык - это система инструкций и данных, выполняемых непосредственно центральным процессором компьютера".
По сути, ассемблерный код - это язык, и он транслируется ассемблером (аналогично компилятору) в объектный код (нативный код, выполняемый процессором).
Я думаю, что это основные отличия
- удобочитаемость кода
- контроль над тем, что делает ваш код
С другой стороны, удобочитаемость кода может улучшить или заменить код через 6 месяцев после его создания, с другой стороны, если производительность критична, вы можете использовать язык низкого уровня, чтобы ориентироваться на конкретное аппаратное обеспечение, которое будет у вас на производстве, чтобы получить более быстрое исполнение.
ИМО сегодня компьютеры достаточно быстры, чтобы позволить программисту добиться быстрого выполнения с ООП.
Исходные файлы ваших программ компилируются в объектные файлы, а затем компоновщик связывает эти объектные файлы вместе, создавая исполняемый файл, включающий машинные коды вашей архитектуры.
И объектный файл, и исполняемый файл включают машинный код архитектуры в виде печатаемых и непечатаемых символов, когда он открывается текстовым редактором.
Тем не менее, дихотомия между файлами заключается в том, что объектный файл (ы) может содержать неразрешенные внешние ссылки (например, printf, например). Таким образом, возможно, потребуется связать его с другими объектными файлами. То есть, необходимо разрешить неразрешенные внешние ссылки, чтобы получить достойный исполняемый исполняемый файл путем связывания с другими объектными файлами, такими как библиотека времени выполнения C/C++..