Извлечение адреса из строки в PHP с помощью RegEx
Моя проблема
Я пытаюсь просканировать отдельные ссылки на сайте Палаты представителей США, чтобы найти адреса Вашингтона для всех перечисленных лиц. Проблема в том, что формат вашингтонского адреса время от времени меняется. Иногда встречаются пули, трубы, новые линии и метки, которые затрудняют поиск.
Я пытаюсь сканировать много страниц, чтобы получить адреса, которые в значительной степени похожи:
игнорировать своеобразный пробел. Это просто, чтобы показать сходство строк
1433, Лонгворт Хаус, Офисное здание, Вашингтон, округ Колумбия, 20515
332 Cannon HOB Вашингтон, округ Колумбия 20515
1641 LONGWORTH HOUSE OFFICE BUILDING WASHINGTON, DC 20515
1238 Cannon HOB (возврат строки)
Вашингтон, округ Колумбия, 20515
8293 Longworth House Офисное здание • Вашингтон, округ Колумбия • 20515
8293 Longworth House Офисное здание | Вашингтон, округ Колумбия | 20515
Каждый из них будет возвращаться индивидуально в окружении множества других текстовых и HTML-тегов. Адреса могут даже содержать
или
внутри самого адреса.
То, что я хотел бы сделать, это захватить первое совпадение из исходной строки и установить его в качестве значения переменной. Насколько я понимаю, к этому лучше всего подходить с регулярным выражением.
Обновить:
Узнав больше о различных способах появления этих дней, я решил, что лучше использовать менее строгое выражение. Эти адреса были обнаружены с пулями, трубами и символами новой строки. Возможно, было бы лучше использовать выражение, которое сообщает следующее:
[числа][что угодно]["вашингтон"][что угодно][DC|DC][что угодно][пять чисел]
Видимо, это слишком свободно. Блоки " что-нибудь" содержали абзацы, когда я просто хотел разрешить несколько символов чего-либо.
До сих пор мне не удалось сопоставить адреса, найденные на следующих (это лишь некоторые из многих)
5 ответов
РЕДАКТИРОВАТЬ: Кажется, что данные [что-нибудь] между первым набором чисел и "вашингтон" должен быть немного более ограничительным для правильной работы. Раздел [что-нибудь] не должен содержать никаких чисел, так как числа - это то, что мы используем для определения начала одного из адресов. Это работает для трех сайтов, которые вы нам дали.
Я бы сказал, что лучшим первым шагом было бы удалить все HTML-теги и заменить символьную сущность '':
$input = strip_tags($input);
$input = preg_replace("/ /"," ",$input);
затем, если адреса соответствуют (близко к) указанному вами формату, выполните:
$results= array();
preg_match("/[0-9]+\s+[^0-9]*?\s+washington,?\s*D\.?C\.?[^0-9]+[0-9]{5}/si",$input,$results);
foreach($result[0] as $addr){
echo "$addr<br/>";
}
Это работает для трех примеров, которые вы предоставили, и $results[0] должен содержать каждый из найденных адресов.
Однако, это не сработает, например, если в адресе есть "Квартира № 2" или что-то подобное, потому что предполагается, что числа, самые близкие к "Вашингтону", обозначают начало адреса.
Следующий скрипт соответствует каждому из тестовых случаев:
<?php
$input = "
1433 Longworth House Office Building Washington, D.C. 20515
332 Cannon HOB Washington DC 20515
1641 LONGWORTH HOUSE OFFICE BUILDING WASHINGTON, DC 20515
1238 Cannon H.O.B.
Washington, DC 20515
8293 Longworth House Office Building • Washington DC • 20515
8293 Longworth House Office Building | Washington DC | 20515
";
$input = strip_tags($input);
$input = preg_replace("/ /"," ",$input);
$results= array();
preg_match_all("/[0-9]+\s+[^0-9]*?washington,?\s*D\.?C\.?[^0-9]*?[0-9]{5}/si",$input,$results);
foreach($results[0] as $addr){
echo "$addr<br/>";
}
Это регулярное выражение использует более гибкий подход к содержанию входной строки. Часть "Вашингтон, округ Колумбия" не была жестко закодирована в этом. Различные части адресов записываются отдельно, весь адрес будет записан в $matches[0],
$input = strip_tags($input);
preg_match('/
(\d++) # Number (one or more digits) -> $matches[1]
\s++ # Whitespace
([^,]++), # Building + City (everything up until a comma) -> $matches[2]
\s++ # Whitespace
(\S++) # "DC" part (anything but whitespace) -> $matches[3]
\s++ # Whitespace
(\d++) # Number (one or more digits) -> $matches[4]
/x', $input, $matches);
Есть инструменты и API, которые созданы для этого. Например, очень хорошо работает LiveAddress от SmartyStreets. Я помог в его разработке, и поэтому я чувствую некоторую вашу боль... Вот результат из примера, который вы предоставили в своем вопросе:
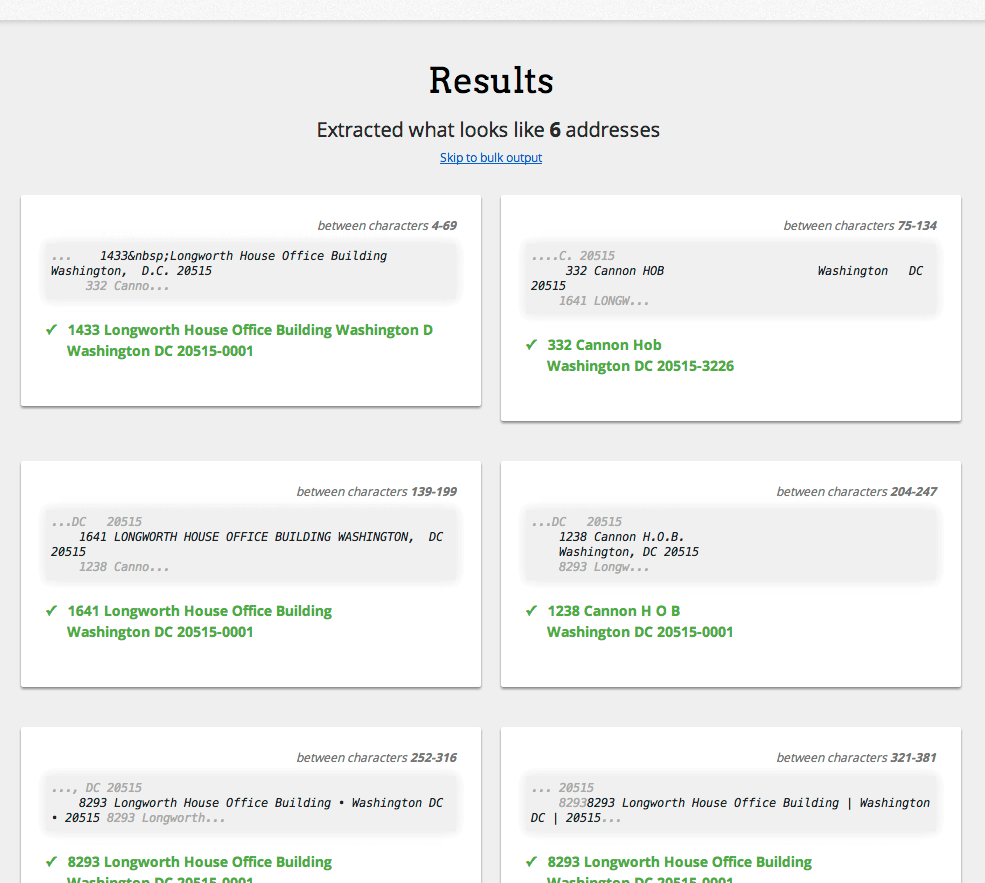
Вот вывод CSV:
ID,Start,End,Segment,Verified,Candidate,Firm,FirstLine,SecondLine,LastLine,City,State,ZIPCode,County,DpvFootnotes,DeliveryPointBarcode,Active,Vacant,CMRA,MatchCode,Latitude,Longitude,Precision,RDI,RecordType,BuildingDefaultIndicator,CongressionalDistrict,Footnotes
1,4,69,"1433 Longworth House Office Building Washington, D.C. 20515",Y,0,,1433 Longworth House Office Building Washington D,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001330,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
2,75,134,332 Cannon HOB Washington DC 20515,Y,0,,332 Cannon Hob,,Washington DC 20515-3226,Washington,DC,20515,District of Columbia,AAU1,205153226996,,,,Y,38.89106,-77.01132,Zip5,Residential,H,Y,AL,H#Q#
3,139,199,"1641 LONGWORTH HOUSE OFFICE BUILDING WASHINGTON, DC 20515",Y,0,,1641 Longworth House Office Building,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001411,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
4,204,247,"1238 Cannon H.O.B.
Washington, DC 20515",Y,0,,1238 Cannon H O B,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001385,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
5,252,316,8293 Longworth House Office Building • Washington DC • 20515,Y,0,,8293 Longworth House Office Building,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001934,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
6,321,381,8293 Longworth House Office Building | Washington DC | 20515,Y,0,,8293 Longworth House Office Building,,Washington DC 20515-0001,Washington,DC,20515,District of Columbia,AAU1,205150001934,,,,Y,38.89106,-77.01132,Zip5,Residential,S,,AL,Q#X#
Прошло около 2 секунд. Этот API бесплатный для использования до определенного момента, и могут быть другие, как это; Я рекомендую вам немного осмотреться, чтобы найти оптимальный вариант для вас... Я гарантирую, что это будет лучше, чем написание собственного регулярного выражения (подсказка: код этого не основан на регулярных выражениях).
РЕДАКТИРОВАТЬ:
Посмотрев на сайты, которые вы упомянули, я думаю, что следующее должно работать. Предполагая, что у вас есть содержимое страницы, которую вы сканировали в переменной с именем $pageтогда вы могли бы использовать
$subject = strip_tags($page)
удалить всю HTML-разметку со страницы; затем примените регулярное выражение
(\d+)\s*(.*?)\s*washington.{0,5}(DC|D.C.).{0,5}(\d{5})
RegexBuddy генерирует следующий код для этого (я не знаю PHP):
if (preg_match('/(\d+)\s*(.*?)\s*washington.{0,5}(DC|D.C.).{0,5}(\d{5})/si', $subject, $regs)) {
$result = $regs[0];
} else {
$result = "";
}
$regs[1] будет содержать содержимое первых захватных паренов (чисел) и так далее.
Обратите внимание на использование /si модификаторы, чтобы точка соответствовала символам новой строки, и чтобы регулярное выражение не чувствительно к регистру.
Ваш вопрос мне не очень понятен, но если я вас правильно понял, я думаю, вы могли бы использовать DOM-парсер для сопоставления с тегами p, а затем проверить, есть ли у любого из них слово "Вашингтон" или номер телефона соответствует Вашингтону площадь.