Производительность моей программы на Python падает при использовании многопроцессорности
Я пытаюсь ускорить выполнение следующей программы, поэтому я использовал многопроцессорность, как было предложено в ответах на последний заданный вопрос, а также по связанному вопросу. Итак, у меня есть следующая программа, которая работает очень медленно, чем раньше:
import threading
from threading import Thread
from multiprocessing import Process
def sim_QxD_word(query, document, model, alpha, outOfVocab, lock):
#word_level
sim_w = {}
for q in set(query.split()):
sim_w[q] = {}
qE = []
if q in model.vocab:
qE = model[q]
elif q in outOfVocab:
qE = outOfVocab[q]
else:
qE = numpy.random.rand(model.layer1_size) # random vector
lock.acquire()
outOfVocab[q] = qE
lock.release()
for d in set(document.split()):
dE = []
if d in model.vocab:
dE = model[d]
elif d in outOfVocab:
dE = outOfVocab[d]
else:
dE = numpy.random.rand(model.layer1_size) # random vector
lock.acquire()
outOfVocab[d] = dE
lock.release()
sim_w[q][d] = sim(qE,dE,alpha)
return (sim_w, outOfVocab)
def sim_QxD_sequences(query, document, model, outOfVocab, alpha, lock): #sequence_level
# 1. extract document sequences
document_sequences = []
for i in range(len(document.split())-len(query.split())):
document_sequences.append(" ".join(document.split()[i:i+len(query.split())]))
# 2. compute similarities with a query sentence
lock.acquire()
query_vec, outOfVocab = avg_sequenceToVec(query, model, outOfVocab, lock)
lock.release()
sim_QxD = {}
for s in document_sequences:
lock.acquire()
s_vec, outOfVocab = avg_sequenceToVec(s, model, outOfVocab, lock)
lock.release()
sim_QxD[s] = sim(query_vec, s_vec, alpha)
return (sim_QxD, outOfVocab)
def word_level(q_clean, d_text, model, alpha, outOfVocab, out_w, q, ext_id, lock):
print("in word_level")
sim_w, outOfVocab = sim_QxD_word(q_clean, d_text, model, alpha, outOfVocab, lock)
numpy.save(join(out_w, str(q)+ext_id+"word_interactions.npy"), sim_w)
def sequence_level(q_clean, d_text, model, outOfVocab, alpha, out_s, q, ext_id, lock):
print("in sequence_level")
sim_s, outOfVocab = sim_QxD_sequences(q_clean, d_text, model, outOfVocab, alpha, lock)
numpy.save(join(out_s, str(q)+ext_id+"sequence_interactions.npy"), sim_s)
def extract_AllFeatures_parall(q_clean, d_text, model, alpha, outOfVocab, out_w, q, ext_id, out_s, lock):
print("in extract_AllFeatures")
thW=Process(target = word_level, args=(q_clean, d_text, model, alpha, outOfVocab, out_w, q, ext_id, lock,))
thS=Process(target = sequence_level, args=(q_clean, d_text, model, outOfVocab, alpha, out_s, q, ext_id, lock,))
thW.start()
thS.start()
thW.join()
thS.join()
def process_documents(documents, index, model, alpha, outOfVocab, out_w, out_s, queries, stemming, stoplist, q):
print("in process_documents")
q_clean = clean(queries[q],stemming, stoplist)
lock = threading.Lock()
for d in documents:
ext_id, d_text = reaDoc(d, index)
extract_AllFeatures_parall(q_clean, d_text, model, alpha, outOfVocab, out_w, q, ext_id, out_s, lock)
outOfVocab={} # shared variable over all threads queries = {"1":"first query", ...} # can contain 200 elements
....
threadsList = []
for q in queries.keys():
thread = Process(target = process_documents, args=(documents, index, model, alpha, outOfVocab, out_w, out_s, queries, stemming, stoplist, q,))
thread.start()
threadsList.append(thread):
for th in threadsList:
th.join()
Но кажется, что все процессы выполняются на одном узле или только один. У меня нет большого опыта в многопроцессорной обработке с python, возможно, проблема в использовании общей блокировки, потому что после нескольких секунд работы программы я получаю этот экран с помощью команды "htop":
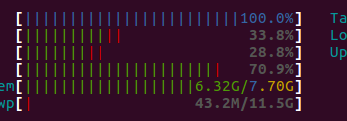
После этого работает только один узел, и вот что напечатано на консоли:
in process_documents
in process_documents
in extract_AllFeatures
in extract_AllFeatures
in word_level
in word_level
in sequence_level
in sequence_level
Это означает, что функции работают, но это очень медленно.