Почему есть разные результаты для getizeof между list() и []
Во время работы я заметил странную вещь:
from sys import getsizeof as gs
list1=[1]
list2=list([1])
list1==list2 #true
gs(list1) #80. (I guess 72 overhead +8 of the int)
gs(list2) #104. (I guess 72 + 8 as above + 24 of...?)
list3=[1,2,3,4,5]
list4=list(list3)
gs(list3) #112
gs(list4) #136
Так что всегда есть разница в 24 байта, и я не могу понять, откуда они берутся.
Конечно, это что-то связано с внутренностями, но кто-нибудь может объяснить мне, что происходит под капотом?
1 ответ
TL;DR: списки перераспределяют, чтобы они могли обеспечить амортизированное постоянное время (O(1)) добавить операции. Объем перераспределения зависит от того, как создается список, и от истории добавления / удаления экземпляра. Список-литерал всегда знает размер заранее и просто не перераспределяет (или только немного). list Функция не всегда знает длину результата, потому что она должна перебирать аргумент, поэтому окончательное перераспределение зависит от используемой (зависящей от реализации) схемы перераспределения.
Чтобы понять, на что мы смотрим, важно знать, что sys.getsizeof сообщает только размер экземпляра. Он не смотрит на содержимое экземпляра. Так что размер содержимого (в данном случае int s) не учитывается
Что на самом деле влияет на размер списка (предполагается 64-битная система):
- 8 байт: количество ссылок.
- 8 байт: указатель на класс.
- 8 байт: хранит количество элементов в списке (эквивалентно
len(your_list)). - 8 байт: хранит размер массива, который содержит элементы в списке (это
len(your_list) + over_allocation) - 8 байт: указатель на массив, в котором хранятся указатели на содержимое.
8 байтов на слот списка: для хранения указателей (или NULL) на каждый элемент в списке.
24 байта: нужны для других вещей (я думаю, что сборщик мусора)
Это объяснение, вероятно, немного сложно понять, поэтому, возможно, оно станет более понятным, если я добавлю несколько изображений (не учитывая дополнительные 24 байта, которые используются для сбора мусора). Я создал их, основываясь на своих выводах на CPython 3.7.2 Windows 64bit, Python 64bit от Anaconda.
Нет перераспределения, например, для mylist = [1,2,3]:
С перераспределением, например, для mylist = list([1,2,3]):
Или для ручного appends:
mylist = []
mylist.append(1)
mylist.append(2)
mylist.append(3)
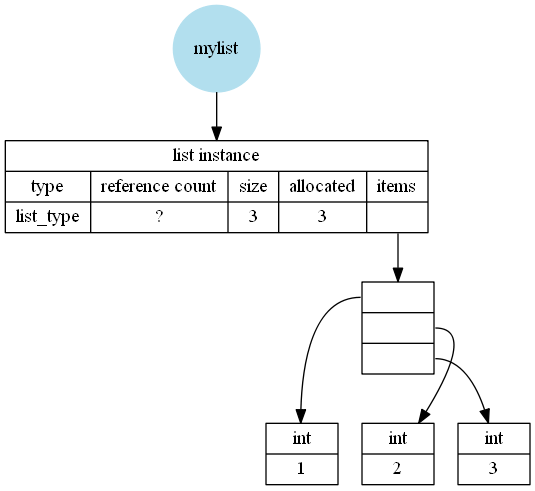
Это означает, что пустой список уже занимает 64 байта, при условии, что пустые списки не имеют перераспределения. Для каждого добавляемого элемента необходимо добавить еще одну ссылку на объект Python (указатель составляет 8 байт).
Таким образом, минимальный размер list является:
size_min = 64 + 8 * n_items
Списки Python имеют переменный размер, и если он будет выделять столько места, сколько нужно для хранения текущего количества элементов, вам придется копировать весь массив всякий раз, когда добавляется новый элемент (делая его O(n)). Однако, если вы перераспределяете, то есть фактически занимает больше памяти, чем нужно для хранения элементов, вы можете поддерживать амортизированные O(1) добавляет, потому что это нужно только изменить размер иногда. Смотрите, например, Википедию "Амортизированный анализ".
Следующий бит в том, что литерал всегда знает его размер, вы кладете x элементы в литерале и во время разбора исходного кода уже известно, насколько большим должен быть список. Таким образом, вы можете просто выделить необходимую память для чего-то вроде этого:
l = [1, 2, 3]
Однако так как list является вызываемым, и Python не оптимизирует этот вызов, даже если аргумент является просто литералом (я имею в виду, вы можете присвоить что-то другое имени list), это должно действительно позвонить list,
list Сам по себе просто перебирает аргумент и добавляет элементы в свой внутренний массив, изменяя размер при необходимости и перераспределяя его для амортизации. O(1), list Можно проверить, какой размер имеет входные данные, но, поскольку (теоретически) во время итерации объекта может произойти все что угодно, эта оценка длины будет принята в качестве приблизительного ориентира, а не гарантии. Поэтому, хотя он избегает перераспределения, если он может предсказать количество элементов в аргументе, он все равно перераспределяет (на всякий случай).
Обратите внимание, что все это детали реализации, они могут быть совершенно другими в других реализациях Python, даже в разных версиях CPython. Единственное, что Python гарантирует (я думаю, что да, я не уверен на 100%), что append амортизируется O(1) а не как это достигается и сколько памяти требуется экземпляру списка.