Как я могу получить и разбить на страницы пользовательский фид в IBM Graph (TitanDB), используя Gremlin/Tinkerpop
У меня есть очень простой новостной канал, смоделированный в IBM Graph (TitanDB при поддержке Cassandra), как показано ниже:
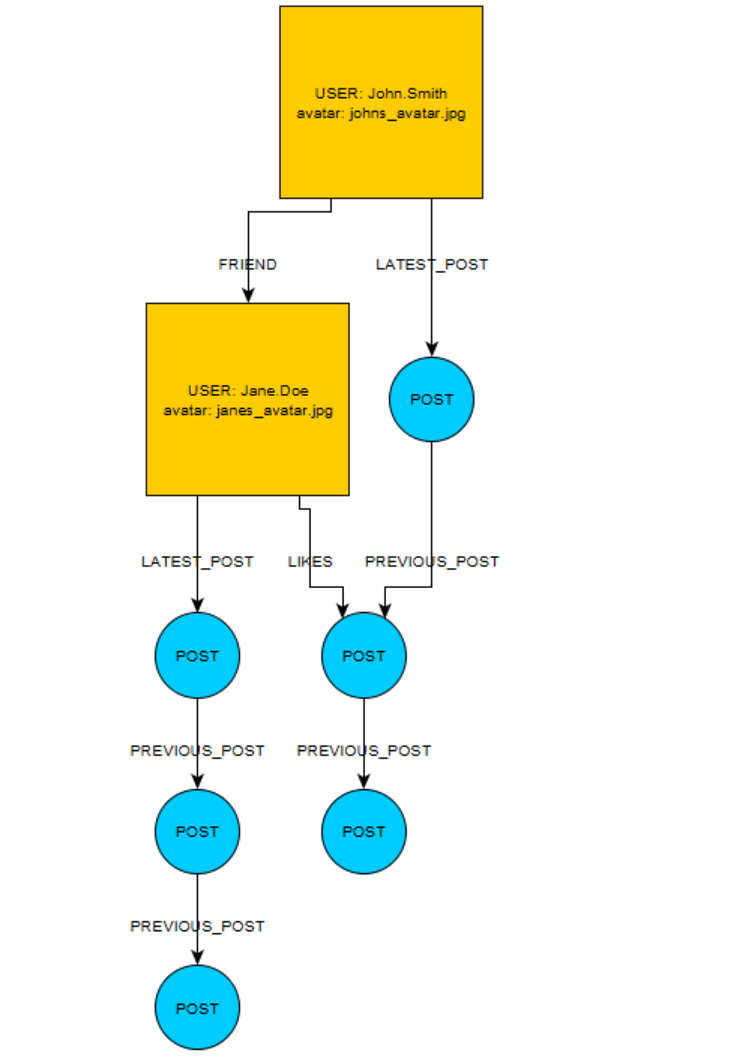
Я пытаюсь написать запрос, который делает следующее:
- Начать с вершины
USER: John.Smith - Получить 15 самых последних сообщений от пользователей
FRIENDSв сочетании с его собственным. - Проверьте, если
USER: John.Smithнравится любой из этих постов и вернуться как простойis_likedлогическое свойство для каждого поста.
Есть несколько предварительных условий для этого запроса:
- В каждом возвращаемом сообщении указаны свойства публикации
USERтакже должны быть возвращены. Ради этого вопроса толькоavatarсобственность обязательна. - Я должен быть в состоянии разбить эти результаты на страницы. т.е. после того, как я получил 15 лучших сообщений, мне нужно иметь возможность вернуть следующие 15, затем следующие и т. д.
У меня нет проблем получить друзей пользователей, и их LATEST_POSTS:
g.V().hasLabel("USER").has("userid", "John.Smith").both("FRIEND").out("LATEST_POST");
Я прочитал документацию Tinkerpop, но все еще теряюсь в том, как начать использовать этот запрос для удовлетворения моих требований.
Кроме того, любые комментарии к этому подходу с точки зрения производительности, моделирования данных, схемы или рекомендаций по индексированию были бы чрезвычайно полезными. т.е. следует ли ожидать, что этот подход сможет извлекать каналы в реальном времени в масштабе?
Заранее спасибо.
2 ответа
Для данной схемы графа запрос будет выглядеть примерно так:
g.V().has("user", "userid", "John.Smith").as("john").
union(identity(), both("FRIEND")).as("user").
out("LATEST_POST").
flatMap(emit().repeat(out("PREVIOUS_POST")).range(page * pageSize, (page + 1) * pageSize)).as("post").
choose(__.in("LIKED").where(eq("john")), constant(true), constant(false)).as("likedByJohn")
select("user", "post", "likedByJohn")
Но Алаа уже указал, что этот подход не будет масштабироваться и как вы могли бы улучшить свою схему графа.
Вы должны проверить рецепт пагинации в http://tinkerpop.apache.org/docs/3.2.3-SNAPSHOT/recipes/. Вот упрощенный способ извлечения одного диапазона / страницы за раз
gremlin> g.V().hasLabel('person').range(0,2)
==>v[1]
==>v[2]
gremlin> g.V().hasLabel('person').range(2,4)
==>v[4]
==>v[6]
Что касается имеющейся у вас модели, я бы не стал использовать ребро LATEST_POST, так как вам нужно будет обновлять это ребро каждый раз, когда у пользователя появляется новое сообщение. Лучше добавить свойство отметки времени к сообщению, и вы всегда можете отсортировать возвращенные результаты по отметке времени, чтобы получить последнее сообщение.