Как сделать плоский список из списка списков?
Интересно, есть ли ярлык для создания простого списка из списка списков в Python.
Я могу сделать это в цикле for, но, может быть, есть какой-нибудь крутой "однострочный"? Я пробовал с помощью Reduce, но я получаю ошибку.
Код
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
reduce(lambda x, y: x.extend(y), l)
Сообщение об ошибке
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
AttributeError: 'NoneType' object has no attribute 'extend'
88 ответов
Приведен список списков l,
flat_list = [item for sublist in l for item in sublist]
что значит:
for sublist in l:
for item in sublist:
flat_list.append(item)
быстрее, чем ярлыки, опубликованные до сих пор. (l это список, чтобы сгладить.)
Вот соответствующая функция:
flatten = lambda l: [item for sublist in l for item in sublist]
В качестве доказательства вы можете использовать timeit Модуль в стандартной библиотеке:
$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' '[item for sublist in l for item in sublist]'
10000 loops, best of 3: 143 usec per loop
$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'sum(l, [])'
1000 loops, best of 3: 969 usec per loop
$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'reduce(lambda x,y: x+y,l)'
1000 loops, best of 3: 1.1 msec per loop
Пояснение: ярлыки на основе + (включая подразумеваемое использование в sum) по необходимости, O(L**2) когда есть L подсписков - поскольку список промежуточных результатов становится длиннее, на каждом шаге выделяется новый объект списка промежуточных результатов, и все элементы в предыдущем промежуточном результате должны быть скопированы (а также добавлено несколько новых). в конце). Итак, для простоты и без фактической потери общности, скажем, у вас есть L подсписков из I элементов каждый: первые I элементы копируются туда и обратно L-1 раз, вторые I элементы L-2 раза и т. Д.; общее количество копий равно I умноженной на сумму x для x от 1 до L, т.е. I * (L**2)/2,
Понимание списка только генерирует один список, один раз, и копирует каждый элемент (из его первоначального места жительства в список результатов) также ровно один раз.
Ты можешь использовать itertools.chain():
>>> import itertools
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> merged = list(itertools.chain(*list2d))
или, на Python >=2.6, используйте itertools.chain.from_iterable() который не требует распаковки списка:
>>> import itertools
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> merged = list(itertools.chain.from_iterable(list2d))
Этот подход, возможно, более читабелен, чем [item for sublist in l for item in sublist] и, кажется, тоже быстрее:
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99;import itertools' 'list(itertools.chain.from_iterable(l))'
10000 loops, best of 3: 24.2 usec per loop
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' '[item for sublist in l for item in sublist]'
10000 loops, best of 3: 45.2 usec per loop
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'sum(l, [])'
1000 loops, best of 3: 488 usec per loop
[me@home]$ python -mtimeit -s'l=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'reduce(lambda x,y: x+y,l)'
1000 loops, best of 3: 522 usec per loop
[me@home]$ python --version
Python 2.7.3
Примечание автора: это неэффективно. Но весело, потому что моноиды потрясающие. Это не подходит для производственного кода Python.
>>> sum(l, [])
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Это просто суммирует элементы итерируемого, переданного в первом аргументе, рассматривая второй аргумент как начальное значение суммы (если не задано, 0 используется вместо этого, и этот случай даст вам ошибку).
Поскольку вы суммируете вложенные списки, вы на самом деле получаете [1,3]+[2,4] как результат sum([[1,3],[2,4]],[]), который равен [1,3,2,4],
Обратите внимание, что работает только со списками списков. Для списков списков списков вам понадобится другое решение.
Я тестировал большинство предлагаемых решений с помощью perfplot ( мой любимый проект, по сути, обертка вокруг timeit), и нашел
functools.reduce(operator.iconcat, a, [])
быть самым быстрым решением. (operator.iadd одинаково быстро.)
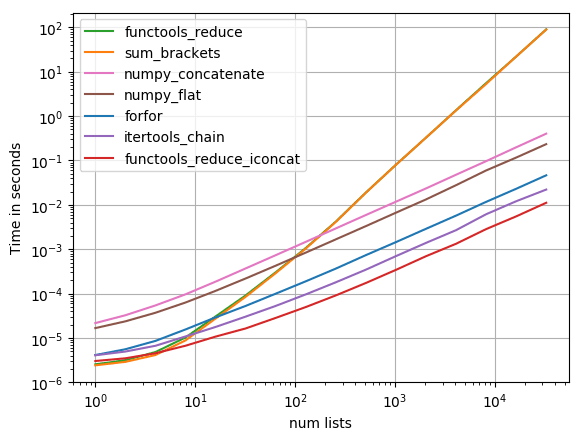
Код для воспроизведения сюжета:
import functools
import itertools
import numpy
import operator
import perfplot
def forfor(a):
return [item for sublist in a for item in sublist]
def sum_brackets(a):
return sum(a, [])
def functools_reduce(a):
return functools.reduce(operator.concat, a)
def functools_reduce_iconcat(a):
return functools.reduce(operator.iconcat, a, [])
def itertools_chain(a):
return list(itertools.chain.from_iterable(a))
def numpy_flat(a):
return list(numpy.array(a).flat)
def numpy_concatenate(a):
return list(numpy.concatenate(a))
perfplot.show(
setup=lambda n: [list(range(10))] * n,
kernels=[
forfor, sum_brackets, functools_reduce, functools_reduce_iconcat,
itertools_chain, numpy_flat, numpy_concatenate
],
n_range=[2**k for k in range(16)],
logx=True,
logy=True,
xlabel='num lists'
)
from functools import reduce #python 3
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(lambda x,y: x+y,l)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
extend() метод в вашем примере изменяет x вместо возврата полезного значения (которое reduce() надеется).
Более быстрый способ сделать reduce версия будет
>>> import operator
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, l)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Не изобретайте велосипед, если вы используете Django:
>>> from django.contrib.admin.utils import flatten
>>> l = [[1,2,3], [4,5], [6]]
>>> flatten(l)
>>> [1, 2, 3, 4, 5, 6]
...Панды:
>>> from pandas.core.common import flatten
>>> list(flatten(l))
...Itertools:
>>> import itertools
>>> flatten = itertools.chain.from_iterable
>>> list(flatten(l))
...Матплотлиб
>>> from matplotlib.cbook import flatten
>>> list(flatten(l))
...Unipath:
>>> from unipath.path import flatten
>>> list(flatten(l))
...Setuptools:
>>> from setuptools.namespaces import flatten
>>> list(flatten(l))
Вот общий подход, который применяется к числам, строкам, вложенным спискам и смешанным контейнерам.
Код
from collections import Iterable
def flatten(items):
"""Yield items from any nested iterable; see Reference."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
for sub_x in flatten(x):
yield sub_x
else:
yield x
Примечание: в Python 3 yield from flatten(x) может заменить for sub_x in flatten(x): yield sub_x
демонстрация
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(flatten(lst)) # nested lists
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
mixed = [[1, [2]], (3, 4, {5, 6}, 7), 8, "9"] # numbers, strs, nested & mixed
list(flatten(mixed))
# [1, 2, 3, 4, 5, 6, 7, 8, '9']
Ссылка
- Это решение модифицировано по рецепту Бизли, Д. и Б. Джонса. Рецепт 4.14, поваренная книга Python, 3-е издание, O'Reilly Media Inc., Севастополь, Калифорния: 2013.
- Нашел более ранний пост SO, возможно, оригинальную демонстрацию.
Если вы хотите сгладить структуру данных, в которой вы не знаете, как глубоко она вложена, вы можете использовать iteration_utilities.deepflatten 1
>>> from iteration_utilities import deepflatten
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> list(deepflatten(l, depth=1))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l = [[1, 2, 3], [4, [5, 6]], 7, [8, 9]]
>>> list(deepflatten(l))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Это генератор, поэтому вам нужно привести результат к list или явно перебрать его.
Чтобы сгладить только один уровень, и если каждый из элементов сам по себе итеративен, вы также можете использовать iteration_utilities.flatten которая сама по себе является просто тонкой оберткой вокруг itertools.chain.from_iterable:
>>> from iteration_utilities import flatten
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> list(flatten(l))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Просто добавим немного времени (на основе ответа Нико Шлёмера, который не включает функцию, представленную в этом ответе):
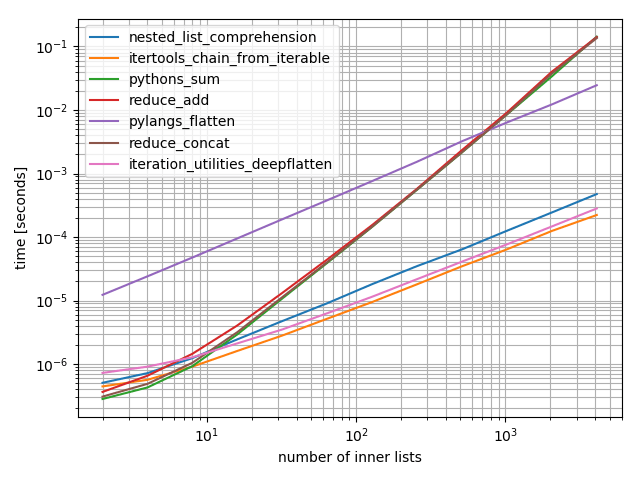
Это логарифмический сюжет для огромного диапазона значений. Для качественного рассуждения: чем ниже, тем лучше.
Результаты показывают, что если итерируемый содержит только несколько внутренних итераций, то sum будет самым быстрым, однако для длинных итераций только itertools.chain.from_iterable, iteration_utilities.deepflatten или вложенное понимание имеет разумную производительность с itertools.chain.from_iterable Быть самым быстрым (как уже заметил Нико Шлёмер).
from itertools import chain
from functools import reduce
from collections import Iterable # or from collections.abc import Iterable
import operator
from iteration_utilities import deepflatten
def nested_list_comprehension(lsts):
return [item for sublist in lsts for item in sublist]
def itertools_chain_from_iterable(lsts):
return list(chain.from_iterable(lsts))
def pythons_sum(lsts):
return sum(lsts, [])
def reduce_add(lsts):
return reduce(lambda x, y: x + y, lsts)
def pylangs_flatten(lsts):
return list(flatten(lsts))
def flatten(items):
"""Yield items from any nested iterable; see REF."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
yield from flatten(x)
else:
yield x
def reduce_concat(lsts):
return reduce(operator.concat, lsts)
def iteration_utilities_deepflatten(lsts):
return list(deepflatten(lsts, depth=1))
from simple_benchmark import benchmark
b = benchmark(
[nested_list_comprehension, itertools_chain_from_iterable, pythons_sum, reduce_add,
pylangs_flatten, reduce_concat, iteration_utilities_deepflatten],
arguments={2**i: [[0]*5]*(2**i) for i in range(1, 13)},
argument_name='number of inner lists'
)
b.plot()
1 Отказ от ответственности: я автор этой библиотеки
Следующее кажется мне самым простым:
>>> import numpy as np
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> print (np.concatenate(l))
[1 2 3 4 5 6 7 8 9]
Рассмотрите возможность установки more_itertools пакет.
> pip install more_itertools
Он поставляется с реализацией для flatten( источник, из рецептов itertools):
import more_itertools
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(more_itertools.flatten(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Начиная с версии 2.4, вы можете выровнять более сложные вложенные итерации с помощью more_itertools.collapse ( источник предоставлен abarnet).
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(more_itertools.collapse(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
lst = [[1, 2, 3], [[4, 5, 6]], [[[7]]], 8, 9] # complex nesting
list(more_itertools.collapse(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Я забираю свое заявление обратно. сумма не победитель. Хотя это быстрее, когда список маленький. Но производительность значительно ухудшается с большими списками.
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10000'
).timeit(100)
2.0440959930419922
Суммарная версия все еще работает более минуты, и она еще не обработана!
Для средних списков:
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
20.126545906066895
>>> timeit.Timer(
'reduce(lambda x,y: x+y,l)',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
22.242258071899414
>>> timeit.Timer(
'sum(l, [])',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
16.449732065200806
Используя маленькие списки и timeit: number=1000000
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
2.4598159790039062
>>> timeit.Timer(
'reduce(lambda x,y: x+y,l)',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
1.5289170742034912
>>> timeit.Timer(
'sum(l, [])',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
1.0598428249359131
Там, кажется, путаница с operator.add! Когда вы добавляете два списка вместе, правильный термин для этого concat, не добавить. operator.concat это то, что вам нужно использовать.
Если вы думаете, функционально, это так просто, как это:
>>> list2d = ((1, 2, 3), (4, 5, 6), (7,), (8, 9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
Вы видите, что Reduced уважает тип последовательности, поэтому, когда вы предоставляете кортеж, вы получаете обратно кортеж. давайте попробуем со списком::
>>> list2d = [[1, 2, 3],[4, 5, 6], [7], [8, 9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Ага, вы получите список обратно.
Как насчет производительности::
>>> list2d = [[1, 2, 3],[4, 5, 6], [7], [8, 9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable довольно быстрый! Но это не сравнить, чтобы уменьшить с Конкат.
>>> list2d = ((1, 2, 3),(4, 5, 6), (7,), (8, 9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
Почему вы используете расширение?
reduce(lambda x, y: x+y, l)
Это должно работать нормально.
Причина, по которой ваша функция не сработала: расширение расширяет массив на месте и не возвращает его. Вы все еще можете вернуть x из лямбды, используя некоторые хитрости:
reduce(lambda x,y: x.extend(y) or x, l)
Примечание: расширение более эффективно, чем + в списках.
По вашему списку
[[1, 2, 3], [4, 5, 6], [7], [8, 9]]который является 1 уровнем списка, мы можем просто использовать
sum(list,[])без использования каких-либо библиотек
sum([[1, 2, 3], [4, 5, 6], [7], [8, 9]],[])
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
matplotlib.cbook.flatten() будет работать для вложенных списков, даже если они вложены глубже, чем в примере.
import matplotlib
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
print(list(matplotlib.cbook.flatten(l)))
l2 = [[1, 2, 3], [4, 5, 6], [7], [8, [9, 10, [11, 12, [13]]]]]
print list(matplotlib.cbook.flatten(l2))
Результат:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
Это в 18 раз быстрее, чем подчеркивание._. Flatten:
Average time over 1000 trials of matplotlib.cbook.flatten: 2.55e-05 sec
Average time over 1000 trials of underscore._.flatten: 4.63e-04 sec
(time for underscore._)/(time for matplotlib.cbook) = 18.1233394636
Рекурсивная версия
x = [1,2,[3,4],[5,[6,[7]]],8,9,[10]]
def flatten_list(k):
result = list()
for i in k:
if isinstance(i,list):
#The isinstance() function checks if the object (first argument) is an
#instance or subclass of classinfo class (second argument)
result.extend(flatten_list(i)) #Recursive call
else:
result.append(i)
return result
flatten_list(x)
#result = [1,2,3,4,5,6,7,8,9,10]
def flatten(l, a):
for i in l:
if isinstance(i, list):
flatten(i, a)
else:
a.append(i)
return a
print(flatten([[[1, [1,1, [3, [4,5,]]]], 2, 3], [4, 5],6], []))
# [1, 1, 1, 3, 4, 5, 2, 3, 4, 5, 6]
Принятый ответ не работал для меня при работе с текстовыми списками переменной длины. Вот альтернативный подход, который работал для меня.
l = ['aaa', 'bb', 'cccccc', ['xx', 'yyyyyyy']]
Принимается ответ, который не сработал:
flat_list = [item for sublist in l for item in sublist]
print(flat_list)
['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c', 'xx', 'yyyyyyy']
Новое предлагаемое решение, которое сработало для меня:
flat_list = []
_ = [flat_list.extend(item) if isinstance(item, list) else flat_list.append(item) for item in l if item]
print(flat_list)
['aaa', 'bb', 'cccccc', 'xx', 'yyyyyyy']
Можно также использовать квартиру NumPy:
import numpy as np
list(np.array(l).flat)
Редактировать 02.11.2016: Работает только в том случае, если подсписки имеют одинаковые размеры.
Плохая особенность функции Anil, описанной выше, состоит в том, что она требует, чтобы пользователь всегда вручную указывал второй аргумент, чтобы он был пустым списком. [], Вместо этого это должно быть по умолчанию. Из-за того, как работают объекты Python, они должны быть установлены внутри функции, а не в аргументах.
Вот рабочая функция:
def list_flatten(l, a=None):
#check a
if a is None:
#initialize with empty list
a = []
for i in l:
if isinstance(i, list):
list_flatten(i, a)
else:
a.append(i)
return a
Тестирование:
In [2]: lst = [1, 2, [3], [[4]],[5,[6]]]
In [3]: lst
Out[3]: [1, 2, [3], [[4]], [5, [6]]]
In [11]: list_flatten(lst)
Out[11]: [1, 2, 3, 4, 5, 6]
Вы можете использовать list extend метод, он оказывается самым быстрым:
flat_list = []
for sublist in l:
flat_list.extend(sublist)
спектакль:
import functools
import itertools
import numpy
import operator
import perfplot
def functools_reduce_iconcat(a):
return functools.reduce(operator.iconcat, a, [])
def itertools_chain(a):
return list(itertools.chain.from_iterable(a))
def numpy_flat(a):
return list(numpy.array(a).flat)
def extend(a):
n = []
list(map(n.extend, a))
return n
perfplot.show(
setup=lambda n: [list(range(10))] * n,
kernels=[
functools_reduce_iconcat, extend,itertools_chain, numpy_flat
],
n_range=[2**k for k in range(16)],
xlabel='num lists',
)
выход:

Используйте два
forв понимании списка:
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
flat_l = [e for v in l for e in v]
print(flat_l)
Есть несколько ответов с такой же схемой рекурсивного добавления, как показано ниже, но ни один из них не использует try, что делает решение более надежным и питоническим. Другие преимущества этого решения:
- работает с любыми итерациями (даже с будущими)
- работает с любым сочетанием и глубиной вложенности
- нет зависимостей
~
def flatten(itr):
t = tuple()
for e in itr:
try:
t += flatten(e)
except:
t += (e,)
return t
Мне лично сложно запомнить все модули, которые нужно было импортировать. Поэтому я предпочитаю использовать простой метод, хотя я не знаю, как его производительность сравнивается с другими ответами.
from collections.abc import Iterable
def flatten(lst):
for item in lst:
if isinstance(item, Iterable) and not isinstance(item, str):
yield from flatten(item)
else:
yield item
test case:
a =[0, [], "fun", [1, 2, 3], [4, 5, 6], 3, [7], [8, 9]]
list(flatten(a))
output
[0, 'fun', 1, 2, 3, 4, 5, 6, 3, 7, 8, 9]
Примечание: ниже относится к Python 3.3+, потому что он использует yield_from, six это также сторонний пакет, хотя и стабильный. Вы также можете использовать sys.version,
В случае obj = [[1, 2,], [3, 4], [5, 6]] все решения здесь хороши, включая понимание списка и itertools.chain.from_iterable,
Однако рассмотрим этот чуть более сложный случай:
>>> obj = [[1, 2, 3], [4, 5], 6, 'abc', [7], [8, [9, 10]]]
Здесь есть несколько проблем:
- Один элемент,
6, это просто скаляр; это не повторяется, поэтому приведенные выше маршруты потерпят неудачу. - Один элемент,
'abc', технически повторяем (всеstrс). Однако, читая немного между строк, вы не хотите рассматривать это как таковое - вы хотите рассматривать это как отдельный элемент. - Последний элемент,
[8, [9, 10]]само по себе является вложенным итеративным. Базовое понимание списка иchain.from_iterableтолько извлечь "1 уровень вниз".
Вы можете исправить это следующим образом:
>>> from collections import Iterable
>>> from six import string_types
>>> def flatten(obj):
... for i in obj:
... if isinstance(i, Iterable) and not isinstance(i, string_types):
... yield from flatten(i)
... else:
... yield i
>>> list(flatten(obj))
[1, 2, 3, 4, 5, 6, 'abc', 7, 8, 9, 10]
Здесь вы проверяете, что подэлемент (1) итерируется с Iterable Азбука от itertools, но также хочу убедиться, что (2) элемент не является "строковым".
Если вы готовы отказаться от небольшого количества скорости для более чистого вида, то вы можете использовать numpy.concatenate().tolist() или же numpy.concatenate().ravel().tolist():
import numpy
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]] * 99
%timeit numpy.concatenate(l).ravel().tolist()
1000 loops, best of 3: 313 µs per loop
%timeit numpy.concatenate(l).tolist()
1000 loops, best of 3: 312 µs per loop
%timeit [item for sublist in l for item in sublist]
1000 loops, best of 3: 31.5 µs per loop
Вы можете узнать больше здесь в документах numpy.concatenate и numpy.ravel
Это игра с исходным кодом плаката. (Он был не за горами)
f = []
list(map(f.extend, l))
from nltk import flatten
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
flatten(l)
Преимущество этого решения перед большинством других здесь заключается в том, что если у вас есть список вроде:
l = [1, [2, 3], [4, 5, 6], [7], [8, 9]]
в то время как большинство других решений выдают ошибку, это решение их обрабатывает.
Вы можете использовать NumPy:flat_list = list(np.concatenate(list_of_list))