Программа C для определения уровней и размера кэша
Полная перезапись / обновление для ясности (и ваше здравомыслие, его abit слишком долго)... ( Old Post)
Для назначения мне нужно найти уровни (L1,L2,...) и размер каждого кэша. Учитывая подсказки и то, что я нашел до сих пор: я думаю, что идея состоит в том, чтобы создавать массивы разных размеров и читать их. Сроки этих операций:
sizes = [1k, 4k, 256K, ...]
foreach size in sizes
create array of `size`
start timer
for i = 0 to n // just keep accessing array
arr[(i * 16) % arr.length]++ // i * 16 supposed to modify every cache line ... see link
record/print time
ОБНОВЛЕНО (28 сентября 18:57 UTC+8)
Смотрите также полный источник
Хорошо, теперь, следуя совету @ mah, возможно, я исправил проблему отношения SNR... а также нашел способ синхронизации моего кода (wall_clock_time из лабораторного примера кода)
Тем не менее, я, кажется, получаю неправильные результаты: я на Intel Core i3 2100: [ SPECS]
- L1: 2 x 32K
- L2: 2 x 256K
- L3: 3 МБ
Результаты, которые я получил, на графике:
длинаМод: от 1КБ до 512К

Основание 1-го пика - 32K ... разумно... 2-е - 384K ... почему? Я ожидаю 256?
lengthMod: от 512 КБ до 4 МБ
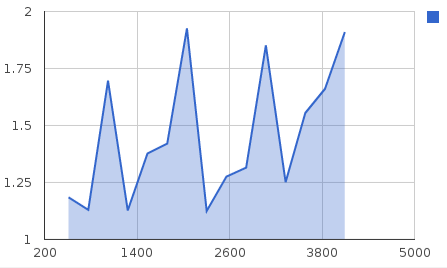
Тогда почему этот диапазон может быть в беспорядке?
Я также читал о предварительной загрузке или вмешательстве из других приложений, поэтому я закрыл как можно больше вещей во время работы скрипта, и последовательно (через многократные прогоны) кажется, что данные размером 1 МБ и выше всегда такие грязные?
6 ответов
Время, необходимое для измерения вашего времени (то есть время только для вызова функции clock()) во много раз (много много много....) раз больше времени, которое требуется для выполнения arr[(i*16)&lengthMod]++, Это чрезвычайно низкое отношение сигнал / шум (среди других вероятных ошибок) делает ваш план неосуществимым. Большая часть проблемы заключается в том, что вы пытаетесь измерить одну итерацию цикла; пример кода, который вы связали, пытается измерить полный набор итераций (считайте часы перед началом цикла; прочитайте его снова после выхода из цикла; не используйте printf() внутри цикла).
Если ваша петля достаточно велика, вы можете решить проблему отношения сигнал / шум.
Что касается того, "какой элемент увеличивается"; arr адрес буфера в 1 МБ; arr[(i * 16) & lengthMod]++; причины (i * 16) * lengthMod генерировать смещение от этого адреса; это смещение является адресом int, который увеличивается. Вы выполняете сдвиг (i * 16 превратится в i << 4), логическое и, дополнительно, затем либо чтение / добавление / запись, либо единичное увеличение, в зависимости от вашего процессора).
Редактирование: Как описано, ваш код страдает от плохого SNR (отношение сигнал / шум) из-за относительной скорости доступа к памяти (кеш или нет кеша) и вызова функций просто для измерения времени. Чтобы получить время, которое вы получаете в настоящее время, я предполагаю, что вы изменили код, чтобы он выглядел примерно так:
int main() {
int steps = 64 * 1024 * 1024;
int arr[1024 * 1024];
int lengthMod = (1024 * 1024) - 1;
int i;
double timeTaken;
clock_t start;
start = clock();
for (i = 0; i < steps; i++) {
arr[(i * 16) & lengthMod]++;
}
timeTaken = (double)(clock() - start)/CLOCKS_PER_SEC;
printf("Time for %d: %.12f \n", i, timeTaken);
}
Это перемещает измерение за пределы цикла, поэтому вы измеряете не один доступ (что на самом деле было бы невозможно), а измеряете steps доступ.
Вы можете увеличить steps по мере необходимости, и это будет иметь прямое влияние на ваши сроки. Поскольку время, которое вы получаете, слишком близко друг к другу, а в некоторых случаях даже инвертировано (ваше время колеблется между размерами, что, скорее всего, не связано с кэшем), вы можете попробовать изменить значение steps в 256 * 1024 * 1024 или даже больше.
ПРИМЕЧАНИЕ: вы можете сделать steps настолько большой, насколько вы можете вписать в int со знаком (который должен быть достаточно большим), так как логично и гарантирует, что вы обернетесь в своем буфере.
После 10 минут поиска инструкции по эксплуатации Intel и еще 10 минут кодирования я придумал это (для процессоров Intel):
void i386_cpuid_caches () {
int i;
for (i = 0; i < 32; i++) {
// Variables to hold the contents of the 4 i386 legacy registers
uint32_t eax, ebx, ecx, edx;
eax = 4; // get cache info
ecx = i; // cache id
__asm__ (
"cpuid" // call i386 cpuid instruction
: "+a" (eax) // contains the cpuid command code, 4 for cache query
, "=b" (ebx)
, "+c" (ecx) // contains the cache id
, "=d" (edx)
); // generates output in 4 registers eax, ebx, ecx and edx
// taken from http://download.intel.com/products/processor/manual/325462.pdf Vol. 2A 3-149
int cache_type = eax & 0x1F;
if (cache_type == 0) // end of valid cache identifiers
break;
char * cache_type_string;
switch (cache_type) {
case 1: cache_type_string = "Data Cache"; break;
case 2: cache_type_string = "Instruction Cache"; break;
case 3: cache_type_string = "Unified Cache"; break;
default: cache_type_string = "Unknown Type Cache"; break;
}
int cache_level = (eax >>= 5) & 0x7;
int cache_is_self_initializing = (eax >>= 3) & 0x1; // does not need SW initialization
int cache_is_fully_associative = (eax >>= 1) & 0x1;
// taken from http://download.intel.com/products/processor/manual/325462.pdf 3-166 Vol. 2A
// ebx contains 3 integers of 10, 10 and 12 bits respectively
unsigned int cache_sets = ecx + 1;
unsigned int cache_coherency_line_size = (ebx & 0xFFF) + 1;
unsigned int cache_physical_line_partitions = ((ebx >>= 12) & 0x3FF) + 1;
unsigned int cache_ways_of_associativity = ((ebx >>= 10) & 0x3FF) + 1;
// Total cache size is the product
size_t cache_total_size = cache_ways_of_associativity * cache_physical_line_partitions * cache_coherency_line_size * cache_sets;
printf(
"Cache ID %d:\n"
"- Level: %d\n"
"- Type: %s\n"
"- Sets: %d\n"
"- System Coherency Line Size: %d bytes\n"
"- Physical Line partitions: %d\n"
"- Ways of associativity: %d\n"
"- Total Size: %zu bytes (%zu kb)\n"
"- Is fully associative: %s\n"
"- Is Self Initializing: %s\n"
"\n"
, i
, cache_level
, cache_type_string
, cache_sets
, cache_coherency_line_size
, cache_physical_line_partitions
, cache_ways_of_associativity
, cache_total_size, cache_total_size >> 10
, cache_is_fully_associative ? "true" : "false"
, cache_is_self_initializing ? "true" : "false"
);
}
}
Ссылка: http://download.intel.com/products/processor/manual/325462.pdf 3-166 Том. 2A
Это гораздо более надежно, чем измерение задержек кэша, поскольку практически невозможно отключить предварительную выборку кэша на современном процессоре. Если вам требуется аналогичная информация для другой архитектуры процессора, вам следует обратиться к соответствующему руководству.
Редактировать: Добавлен дескриптор типа кэша. Edit2: добавлен индикатор уровня кэша. Edit3: добавлено больше документации.
Я знаю это! (На самом деле это очень сложно из-за предварительной выборки)
for (times = 0; times < Max; time++) /* many times*/
for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
Изменение шага позволяет проверить свойства кешей. Глядя на график, вы получите ответы.
Посмотрите на слайды 35-42 http://www.it.uu.se/edu/course/homepage/avdark/ht11/slides/11_Memory_and_optimization-1.pdf
Эрик Хагерстен - действительно хороший учитель (и также очень компетентный, когда-то он был ведущим архитектором на солнце), так что посмотрите на остальные его слайды, чтобы получить более интересные объяснения!
Чтобы ответить на ваш вопрос о странных цифрах выше 1 МБ, это довольно просто; политики вытеснения кеша, связанные с предсказанием ветвлений и тем фактом, что кеш L3 распределяется между ядрами.
Ядро i3 имеет очень интересную структуру кэша. Фактически любой современный процессор делает. Вы должны прочитать о них в Википедии; есть множество способов решить: "ну, я, вероятно, не буду нуждаться в этом...", тогда он может сказать: "Я положу это в кэш жертвы" или любое другое. Время кэширования L1-2-3 может быть очень сложным из-за большого количества факторов и индивидуальных решений, принятых при проектировании.
Кроме того, все эти решения и многое другое (см. Статьи Википедии на эту тему) должны быть синхронизированы между кешами двух ядер. Методы синхронизации общего кэша L3 с отдельными кэшами L1 и L2 могут быть уродливыми, они могут включать в себя обратное отслеживание и повторные вычисления или другие методы. Маловероятно, что у вас когда-либо будет полностью бесплатное второе ядро, и ничто не будет конкурировать за пространство кэш-памяти L3 и, таким образом, вызывать странности синхронизации.
В общем, если вы работаете с данными, скажем, свертываете ядро, вы хотите убедиться, что оно вписывается в кэш L1, и сформировать свой алгоритм вокруг этого. Кэш L3 на самом деле не предназначен для работы с набором данных так, как вы это делаете (хотя он лучше основной памяти!)
Клянусь, если бы мне пришлось реализовывать алгоритмы кэширования, я бы сошел с ума.
Для бенчмаркинга с различными шагами вы можете попробовать lat_mem_rd из пакета lmbench, он с открытым исходным кодом: http://www.bitmover.com/lmbench/lat_mem_rd.8.html
Я разместил свой порт для Windows на http://habrahabr.ru/post/111876/ - это довольно долго, чтобы быть скопированным здесь. Это два года назад, я не тестировал его с современными процессорами.
Для окон вы можете использовать метод GetLogicalProcessorInformation.
Для Linux вы можете использовать sysconf(), Вы можете найти действительные аргументы для sysconf в /usr/include/unistd.h или же /usr/include/bits/confname.h