Почему eclipse считает df.as[CaseClass] ошибкой в программе Scala Spark?
Я пытаюсь преобразовать массив данных в набор данных, используя синтаксис
case class Schema(...)
val ds = df.as[Schema]
Итак, мой код выглядит
case class Rule(rule_on: String, rule_operator: String, rule_value: Int, rule_name: String)
val rules_ds = rules_df
.select("rule_on", "rule_operator", "rule_value", "rule_name")
.as[Rule]
Но затмение выделяет .as[Rule] как ошибка. Снимки экрана такие же, как ниже.
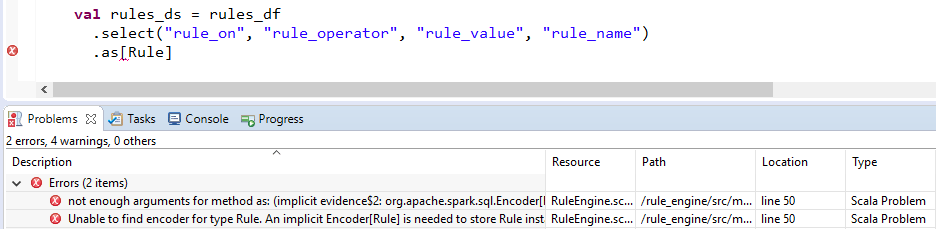
Как решить эту проблему? Я знаю, что это не проблема Scala, так как он работает в командной строке.
Окружение (как в Eclipse):
- Скала - 2.11.11
- Искра - 2.4.0
- JRE - 1,8
1 ответ
По предложению Raphael Roth (в комментариях) я определил класс case вне метода main, и он работает как шарм.
Также другое решение (без использования класса case) состоит в том, чтобы привести тип данных в набор данных, как показано ниже
import org.apache.spark.sql._
val ds: Dataset[Row] = df
Вышеупомянутое решение было взято отсюда