Предпочитаете нет столбцов для таблицы фактов?
У меня есть таблица фактов с данными политики, и я хочу добавить детали продуктов политики в хранилище. Одна политика получает разные типы продуктов, а значения также являются динамическими.
Например, у Policy01 может быть два продукта Building & Contents, в которых страховая сумма равна 1000 и 500 соответственно. А Policy02 получит Building только из 750.
Доступно около 30 продуктов, и мне нужно хранить страховую сумму, валовые и чистые премии каждого продукта за полис. Так что, если я добавлю отдельный столбец для каждого типа продукта в таблицу фактов, он добавит еще 120 столбцов (в настоящее время их 23). Также максимум 5 товаров на одну политику, поэтому только 20 столбцов будут содержать значения, а остальные останутся пустыми.
Можно ли иметь более 100 столбцов для таблицы фактов? Можно ли хранить столько пустых значений подряд? Или есть другой подход, который я могу решить?
Я новичок в DWH и надеюсь, что кто-нибудь может пролить свет на то, как добавить их в мою таблицу фактов.
2 ответа
Один из подходов заключается в добавлении измерения продукта: 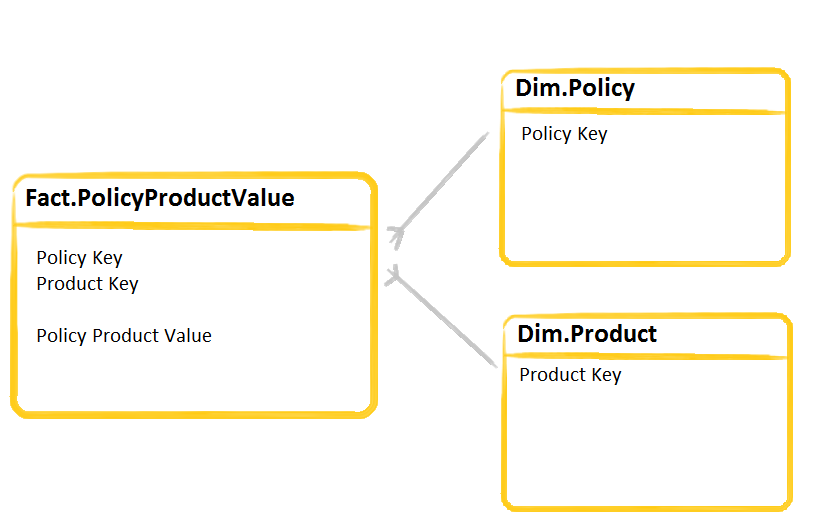
Затем вы можете вернуть итоги по политике:
SELECT
PolicyKey
SUM(PolicyProductValue) AS PolicyValue
FROM
Fact.PolicyProductValue
GROUP BY
PolicyKey
;
Или продукт:
SELECT
ProductKey,
SUM(PolicyProductValue) AS ProductValue
FROM
Fact.PolicyProductValue
GROUP BY
ProductKey
;
Или оба:
SELECT
PolicyKey,
ProductKey,
SUM(PolicyProductValue) AS PolicyProductValue
FROM
Fact.PolicyProductValue
GROUP BY
PolicyKey,
ProductKey
;
Этот подход перемещает продукты из столбцов в строки.
Этот метод предлагает несколько преимуществ:
- Легче добавлять новые строки, чем столбцы.
- Вы можете добавить общие фильтры к
Dim.Product, Dim.Productпредоставляет место для создания иерархий продуктов. Пример:
| Product Key | Product Name | Product Group |
| ----------- | ------------ | --------------------|
| 0 | Building | Building & Contents |
| 1 | Contents | Building & Contents |
Нельзя иметь более 100 столбцов в таблице фактов; это признак неправильной модели данных (то же самое верно для пропущенных значений - хорошо разработанная таблица фактов не должна иметь их).
Логика разработки таблицы фактов следующая: во-первых, выберите для таблицы "гранулярность" - самый атомарный уровень данных, который она будет содержать. В вашем случае гранулярность данных определяется номером политики + продукт. Вместе они однозначно определяют наиболее подробную информацию, доступную для вас.
Затем определите ваши "факты". Как правило, факты представляют собой фрагменты данных, которые вы можете агрегировать (сумма, количество, среднее и т. Д.). В вашем случае это Insured_Value, Gross_Premium, Net_Premium.
Наконец, определите бизнес-контекст для этих фактов (измерений). В вашем случае это политика и продукт (скорее всего, у вас также будет какая-то дата).
Ваша итоговая таблица фактов должна выглядеть примерно так:
- Policy_Date
- Страховой номер
- Код товара
- Insured_Value
- Gross_Premium
- Net_Premium
Policy_Date обеспечит подключение к измерению "Календарь", Product_ID подключится к измерению "Продукт" (таблица, содержащая ваши 30 продуктов и их описания).
Policy_Number - это то, что называется "вырожденным измерением" - это идентификатор, который обычно не связан ни с одним измерением (но может, если вам нужно). Он хранится в таблице фактов просто как ссылка. Некоторые люди добавляют измерение "Политика" в модель, но обычно это ошибка проектирования - такие измерения слишком "высокие", сопоставимые по размеру с таблицей фактов, что может значительно снизить производительность вашей модели. Обычно лучше разделить атрибуты политики на несколько небольших измерений и оставить номер политики в качестве вырожденного измерения.
Таким образом, ваша типичная политика с 5 продуктами будет представлена как 5 записей в таблице фактов, а не как одна запись с 5 полями. Это критическое различие - никогда не храните информацию (продукты в вашем случае) в названии полей таблицы фактов.