Разделите запятую строки в столбце на отдельные строки
У меня есть фрейм данных, вот так:
data.frame(director = c("Aaron Blaise,Bob Walker", "Akira Kurosawa",
"Alan J. Pakula", "Alan Parker", "Alejandro Amenabar", "Alejandro Gonzalez Inarritu",
"Alejandro Gonzalez Inarritu,Benicio Del Toro", "Alejandro González Iñárritu",
"Alex Proyas", "Alexander Hall", "Alfonso Cuaron", "Alfred Hitchcock",
"Anatole Litvak", "Andrew Adamson,Marilyn Fox", "Andrew Dominik",
"Andrew Stanton", "Andrew Stanton,Lee Unkrich", "Angelina Jolie,John Stevenson",
"Anne Fontaine", "Anthony Harvey"), AB = c('A', 'B', 'A', 'A', 'B', 'B', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'A'))
Как видите, некоторые записи в director столбец - это несколько имен, разделенных запятыми. Я хотел бы разбить эти записи на отдельные строки, сохраняя значения другого столбца. Например, первая строка в приведенном выше фрейме данных должна быть разбита на две строки с одним именем в каждой director столбец и "А" в AB колонка.
4 ответа
Этот старый вопрос часто используется как двойная цель (помечен r-faq). На сегодняшний день на этот вопрос было дано три ответа, предлагая 6 различных подходов, но ему не хватает эталона в качестве руководства, какой из подходов является самым быстрым 1.
Тестовые решения включают в себя
- Базовый подход Мэтью Ландберга, но модифицированный согласно комментарию Рича Скривена,
- Яап два
data.tableметоды и дваdplyr/tidyrподходы, - Ананда
splitstackshapeрешение, - и два дополнительных варианта Jaap's
data.tableметоды.
В целом 8 различных методов были сопоставлены с 6 различными размерами фреймов данных с использованием microbenchmark пакет (см. код ниже).
Типовые данные, предоставленные OP, состоят только из 20 строк. Для создания больших фреймов данных эти 20 строк просто повторяются 1, 10, 100, 1000, 10000 и 100000 раз, что дает размер проблемы до 2 миллионов строк.
Результаты тестов

Результаты тестов показывают, что для достаточно больших фреймов данных все data.table методы быстрее, чем любой другой метод. Для фреймов данных с более чем 5000 строк, Jaap's data.table способ 2 и вариант DT3 являются самыми быстрыми, величины быстрее, чем самые медленные методы.
Примечательно, что время двух tidyverse методы и splistackshape решения настолько похожи, что сложно выделить кривые на графике. Это самый медленный из тестируемых методов для всех размеров фреймов данных.
Для небольших кадров данных решение Matt's base R и data.table метод 4, кажется, имеет меньше накладных расходов, чем другие методы.
Код
director <-
c("Aaron Blaise,Bob Walker", "Akira Kurosawa", "Alan J. Pakula",
"Alan Parker", "Alejandro Amenabar", "Alejandro Gonzalez Inarritu",
"Alejandro Gonzalez Inarritu,Benicio Del Toro", "Alejandro González Iñárritu",
"Alex Proyas", "Alexander Hall", "Alfonso Cuaron", "Alfred Hitchcock",
"Anatole Litvak", "Andrew Adamson,Marilyn Fox", "Andrew Dominik",
"Andrew Stanton", "Andrew Stanton,Lee Unkrich", "Angelina Jolie,John Stevenson",
"Anne Fontaine", "Anthony Harvey")
AB <- c("A", "B", "A", "A", "B", "B", "B", "A", "B", "A", "B", "A",
"A", "B", "B", "B", "B", "B", "B", "A")
library(data.table)
library(magrittr)
Определить функцию для тестов прогонов размера задачи n
run_mb <- function(n) {
# compute number of benchmark runs depending on problem size `n`
mb_times <- scales::squish(10000L / n , c(3L, 100L))
cat(n, " ", mb_times, "\n")
# create data
DF <- data.frame(director = rep(director, n), AB = rep(AB, n))
DT <- as.data.table(DF)
# start benchmarks
microbenchmark::microbenchmark(
matt_mod = {
s <- strsplit(as.character(DF$director), ',')
data.frame(director=unlist(s), AB=rep(DF$AB, lengths(s)))},
jaap_DT1 = {
DT[, lapply(.SD, function(x) unlist(tstrsplit(x, ",", fixed=TRUE))), by = AB
][!is.na(director)]},
jaap_DT2 = {
DT[, strsplit(as.character(director), ",", fixed=TRUE),
by = .(AB, director)][,.(director = V1, AB)]},
jaap_dplyr = {
DF %>%
dplyr::mutate(director = strsplit(as.character(director), ",")) %>%
tidyr::unnest(director)},
jaap_tidyr = {
tidyr::separate_rows(DF, director, sep = ",")},
cSplit = {
splitstackshape::cSplit(DF, "director", ",", direction = "long")},
DT3 = {
DT[, strsplit(as.character(director), ",", fixed=TRUE),
by = .(AB, director)][, director := NULL][
, setnames(.SD, "V1", "director")]},
DT4 = {
DT[, .(director = unlist(strsplit(as.character(director), ",", fixed = TRUE))),
by = .(AB)]},
times = mb_times
)
}
Запустите бенчмарк для разных задач
# define vector of problem sizes
n_rep <- 10L^(0:5)
# run benchmark for different problem sizes
mb <- lapply(n_rep, run_mb)
Подготовить данные для построения
mbl <- rbindlist(mb, idcol = "N")
mbl[, n_row := NROW(director) * n_rep[N]]
mba <- mbl[, .(median_time = median(time), N = .N), by = .(n_row, expr)]
mba[, expr := forcats::fct_reorder(expr, -median_time)]
Создать диаграмму
library(ggplot2)
ggplot(mba, aes(n_row, median_time*1e-6, group = expr, colour = expr)) +
geom_point() + geom_smooth(se = FALSE) +
scale_x_log10(breaks = NROW(director) * n_rep) + scale_y_log10() +
xlab("number of rows") + ylab("median of execution time [ms]") +
ggtitle("microbenchmark results") + theme_bw()
Информация о сеансе и версии пакета (отрывок)
devtools::session_info()
#Session info
# version R version 3.3.2 (2016-10-31)
# system x86_64, mingw32
#Packages
# data.table * 1.10.4 2017-02-01 CRAN (R 3.3.2)
# dplyr 0.5.0 2016-06-24 CRAN (R 3.3.1)
# forcats 0.2.0 2017-01-23 CRAN (R 3.3.2)
# ggplot2 * 2.2.1 2016-12-30 CRAN (R 3.3.2)
# magrittr * 1.5 2014-11-22 CRAN (R 3.3.0)
# microbenchmark 1.4-2.1 2015-11-25 CRAN (R 3.3.3)
# scales 0.4.1 2016-11-09 CRAN (R 3.3.2)
# splitstackshape 1.4.2 2014-10-23 CRAN (R 3.3.3)
# tidyr 0.6.1 2017-01-10 CRAN (R 3.3.2)
1 Мое любопытство было подкреплено этим обильным комментарием Brilliant! На порядок быстрее! к tidyverse ответ на вопрос, который был закрыт как дубликат этого вопроса.
Несколько альтернатив:
1) два пути с data.table :
library(data.table)
# method 1 (preferred)
setDT(v)[, lapply(.SD, function(x) unlist(tstrsplit(x, ",", fixed=TRUE))), by = AB
][!is.na(director)]
# method 2
setDT(v)[, strsplit(as.character(director), ",", fixed=TRUE), by = .(AB, director)
][,.(director = V1, AB)]
2) dplyr / tidyr комбинация: в качестве альтернативы, вы также можете использовать dplyr / tidyr сочетание:
library(dplyr)
library(tidyr)
v %>%
mutate(director = strsplit(as.character(director), ",")) %>%
unnest(director)
3) с tidyr только: с tidyr 0.5.0 (и позже), вы также можете просто использовать separate_rows:
separate_rows(v, director, sep = ",")
Вы можете использовать convert = TRUE параметр для автоматического преобразования чисел в числовые столбцы.
4) с основанием R:
# if 'director' is a character-column:
stack(setNames(strsplit(df$director,','), df$AB))
# if 'director' is a factor-column:
stack(setNames(strsplit(as.character(df$director),','), df$AB))
Называя ваш оригинальный data.frame vу нас есть это:
> s <- strsplit(as.character(v$director), ',')
> data.frame(director=unlist(s), AB=rep(v$AB, sapply(s, FUN=length)))
director AB
1 Aaron Blaise A
2 Bob Walker A
3 Akira Kurosawa B
4 Alan J. Pakula A
5 Alan Parker A
6 Alejandro Amenabar B
7 Alejandro Gonzalez Inarritu B
8 Alejandro Gonzalez Inarritu B
9 Benicio Del Toro B
10 Alejandro González Iñárritu A
11 Alex Proyas B
12 Alexander Hall A
13 Alfonso Cuaron B
14 Alfred Hitchcock A
15 Anatole Litvak A
16 Andrew Adamson B
17 Marilyn Fox B
18 Andrew Dominik B
19 Andrew Stanton B
20 Andrew Stanton B
21 Lee Unkrich B
22 Angelina Jolie B
23 John Stevenson B
24 Anne Fontaine B
25 Anthony Harvey A
Обратите внимание на использование rep построить новую колонку AB. Вот, sapply возвращает количество имен в каждой из исходных строк.
Поздно к вечеринке, но другой обобщенной альтернативой является использование cSplit из моего пакета "splitstackshape", который имеет direction аргумент. Установите это в "long" чтобы получить указанный вами результат:
library(splitstackshape)
head(cSplit(mydf, "director", ",", direction = "long"))
# director AB
# 1: Aaron Blaise A
# 2: Bob Walker A
# 3: Akira Kurosawa B
# 4: Alan J. Pakula A
# 5: Alan Parker A
# 6: Alejandro Amenabar B
devtools::install_github("yikeshu0611/onetree")
library(onetree)
dd=spread_byonecolumn(data=mydata,bycolumn="director",joint=",")
head(dd)
director AB
1 Aaron Blaise A
2 Bob Walker A
3 Akira Kurosawa B
4 Alan J. Pakula A
5 Alan Parker A
6 Alejandro Amenabar B
Другой тест, полученный с использованием strsplitfrom base в настоящее время можно рекомендовать разделить строки, разделенные запятыми, в столбце на отдельные строки, так как это было самым быстрым в широком диапазоне размеров:
s <- strsplit(v$director, ",", fixed=TRUE)
s <- data.frame(director=unlist(s), AB=rep(v$AB, lengths(s)))
Обратите внимание, что использование fixed=TRUE оказывает значительное влияние на тайминги.
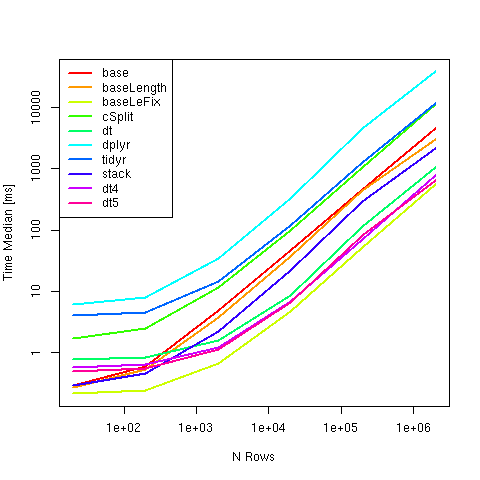
Сравниваемые методы:
met <- alist(base = {s <- strsplit(v$director, ",") #Matthew Lundberg
s <- data.frame(director=unlist(s), AB=rep(v$AB, sapply(s, FUN=length)))}
, baseLength = {s <- strsplit(v$director, ",") #Rich Scriven
s <- data.frame(director=unlist(s), AB=rep(v$AB, lengths(s)))}
, baseLeFix = {s <- strsplit(v$director, ",", fixed=TRUE)
s <- data.frame(director=unlist(s), AB=rep(v$AB, lengths(s)))}
, cSplit = s <- cSplit(v, "director", ",", direction = "long") #A5C1D2H2I1M1N2O1R2T1
, dt = s <- setDT(v)[, lapply(.SD, function(x) unlist(tstrsplit(x, "," #Jaap
, fixed=TRUE))), by = AB][!is.na(director)]
#, dt2 = s <- setDT(v)[, strsplit(director, "," #Jaap #Only Unique
# , fixed=TRUE), by = .(AB, director)][,.(director = V1, AB)]
, dplyr = {s <- v %>% #Jaap
mutate(director = strsplit(director, ",", fixed=TRUE)) %>%
unnest(director)}
, tidyr = s <- separate_rows(v, director, sep = ",") #Jaap
, stack = s <- stack(setNames(strsplit(v$director, ",", fixed=TRUE), v$AB)) #Jaap
#, dt3 = {s <- setDT(v)[, strsplit(director, ",", fixed=TRUE), #Uwe #Only Unique
# by = .(AB, director)][, director := NULL][, setnames(.SD, "V1", "director")]}
, dt4 = {s <- setDT(v)[, .(director = unlist(strsplit(director, "," #Uwe
, fixed = TRUE))), by = .(AB)]}
, dt5 = {s <- vT[, .(director = unlist(strsplit(director, "," #Uwe
, fixed = TRUE))), by = .(AB)]}
)
Библиотеки:
library(microbenchmark)
library(splitstackshape) #cSplit
library(data.table) #dt, dt2, dt3, dt4
#setDTthreads(1) #Looks like it has here minor effect
library(dplyr) #dplyr
library(tidyr) #dplyr, tidyr
Данные:
v0 <- data.frame(director = c("Aaron Blaise,Bob Walker", "Akira Kurosawa",
"Alan J. Pakula", "Alan Parker", "Alejandro Amenabar", "Alejandro Gonzalez Inarritu",
"Alejandro Gonzalez Inarritu,Benicio Del Toro", "Alejandro González Iñárritu",
"Alex Proyas", "Alexander Hall", "Alfonso Cuaron", "Alfred Hitchcock",
"Anatole Litvak", "Andrew Adamson,Marilyn Fox", "Andrew Dominik",
"Andrew Stanton", "Andrew Stanton,Lee Unkrich", "Angelina Jolie,John Stevenson",
"Anne Fontaine", "Anthony Harvey"), AB = c('A', 'B', 'A', 'A', 'B', 'B', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'A'))
Результаты вычислений и хронометража:
n <- 10^(0:5)
x <- lapply(n, function(n) {v <- v0[rep(seq_len(nrow(v0)), n),]
vT <- setDT(v)
ti <- min(100, max(3, 1e4/n))
microbenchmark(list = met, times = ti, control=list(order="block"))})
y <- do.call(cbind, lapply(x, function(y) aggregate(time ~ expr, y, median)))
y <- cbind(y[1], y[-1][c(TRUE, FALSE)])
y[-1] <- y[-1] / 1e6 #ms
names(y)[-1] <- paste("n:", n * nrow(v0))
y #Time in ms
# expr n: 20 n: 200 n: 2000 n: 20000 n: 2e+05 n: 2e+06
#1 base 0.2989945 0.6002820 4.8751170 46.270246 455.89578 4508.1646
#2 baseLength 0.2754675 0.5278900 3.8066300 37.131410 442.96475 3066.8275
#3 baseLeFix 0.2160340 0.2424550 0.6674545 4.745179 52.11997 555.8610
#4 cSplit 1.7350820 2.5329525 11.6978975 99.060448 1053.53698 11338.9942
#5 dt 0.7777790 0.8420540 1.6112620 8.724586 114.22840 1037.9405
#6 dplyr 6.2425970 7.9942780 35.1920280 334.924354 4589.99796 38187.5967
#7 tidyr 4.0323765 4.5933730 14.7568235 119.790239 1294.26959 11764.1592
#8 stack 0.2931135 0.4672095 2.2264155 22.426373 289.44488 2145.8174
#9 dt4 0.5822910 0.6414900 1.2214470 6.816942 70.20041 787.9639
#10 dt5 0.5015235 0.5621240 1.1329110 6.625901 82.80803 636.1899
Обратите внимание, такие методы, как
(v <- rbind(v0[1:2,], v0[1,]))
# director AB
#1 Aaron Blaise,Bob Walker A
#2 Akira Kurosawa B
#3 Aaron Blaise,Bob Walker A
setDT(v)[, strsplit(director, "," #Jaap #Only Unique
, fixed=TRUE), by = .(AB, director)][,.(director = V1, AB)]
# director AB
#1: Aaron Blaise A
#2: Bob Walker A
#3: Akira Kurosawa B
вернуть strsplit за unique директор и может быть сравним с
tmp <- unique(v)
s <- strsplit(tmp$director, ",", fixed=TRUE)
s <- data.frame(director=unlist(s), AB=rep(tmp$AB, lengths(s)))
но, насколько я понимаю, об этом не спрашивали.