ggplot: отображение% вместо количества в диаграммах категориальных переменных с несколькими уровнями
Я хотел бы создать барплот как это:
library(ggplot2)
# Dodged bar charts
ggplot(diamonds, aes(clarity, fill=cut)) + geom_bar(position="dodge")
Однако вместо подсчетов я хочу, чтобы процент наблюдений попадал в каждую категорию "ясности" по категориям ("удовлетворительно", "хорошо", "очень хорошо"...).
С этим...
# Dodged bar charts
ggplot(diamonds, aes(clarity, fill=cut)) +
geom_bar(aes(y = (..count..)/sum(..count..)), position="dodge")
Я получаю проценты по оси Y, но эти проценты игнорируют коэффициент сокращения. Я хочу, чтобы все красные столбцы суммировались до 1, все желтые столбцы - до 1 и т. Д.
Есть ли простой способ сделать это без необходимости подготовки данных вручную?
Спасибо!
PS: это продолжение этого вопроса переполнения стека
1 ответ
Вы могли бы использовать sjp.xtab из пакета sjPlot для этого:
sjp.xtab(diamonds$clarity,
diamonds$cut,
showValueLabels = F,
tableIndex = "row",
barPosition = "stack")
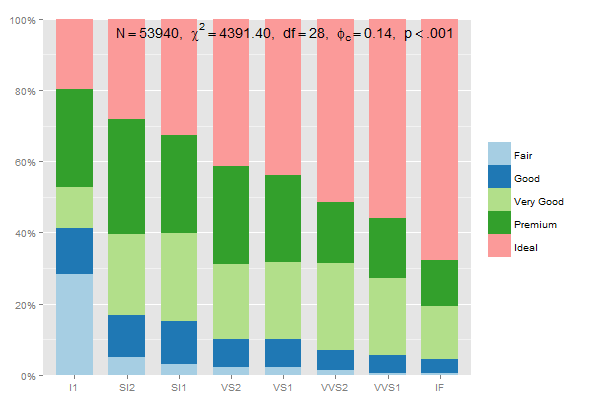
Подготовка данных для суммированных групповых процентов, которые составляют до 100%, должны быть:
data.frame(prop.table(table(diamonds$clarity, diamonds$cut),1))
Таким образом, вы могли бы написать
mydf <- data.frame(prop.table(table(diamonds$clarity, diamonds$cut),1))
ggplot(mydf, aes(Var1, Freq, fill = Var2)) +
geom_bar(position = "stack", stat = "identity") +
scale_y_continuous(labels=scales::percent)
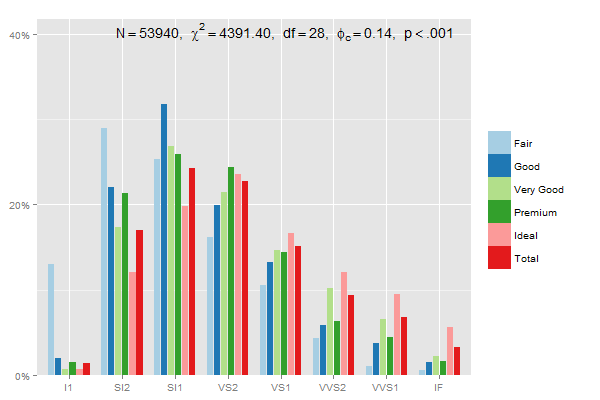
Изменить: этот добавляет каждую категорию (Fair, Good...) до 100%, используя 2 в prop.table а также position = "dodge":
mydf <- data.frame(prop.table(table(diamonds$clarity, diamonds$cut),2))
ggplot(mydf, aes(Var1, Freq, fill = Var2)) +
geom_bar(position = "dodge", stat = "identity") +
scale_y_continuous(labels=scales::percent)
или же
sjp.xtab(diamonds$clarity,
diamonds$cut,
showValueLabels = F,
tableIndex = "col")
Проверяем последний пример с помощью dplyr, суммируя проценты внутри каждой группы:
library(dplyr)
mydf %>% group_by(Var2) %>% summarise(percsum = sum(Freq))
> Var2 percsum
> 1 Fair 1
> 2 Good 1
> 3 Very Good 1
> 4 Premium 1
> 5 Ideal 1
(см. эту страницу для дальнейших вариантов заговора и примеров от sjp.xtab...)