Укрепление обучения, где каждый штат является конечным
Мой вопрос не связан с реализацией обучения подкреплению, но должен понять концепцию RL, когда каждое состояние является конечным состоянием.
Я приведу пример: робот учится играть в футбол, просто стреляя. Награда - это расстояние между мячом и стойкой ворот после того, как он пробил по воротам. Состояние - это массив из множества объектов, а действие - это массив с трехмерной силой.
Если бы мы рассматривали эпизодические RL, я чувствую, что подход не имеет смысла. Действительно, робот стреляет, и выдается награда: каждый эпизод является последним эпизодом. Не имеет смысла передавать следующее состояние в систему, так как алгоритм не заботится об этом, чтобы оптимизировать вознаграждение - в этом случае я бы использовал подход Actor-Critic для обработки непрерывного состояния и пространства действий. Кто-то может возразить, что другой контролируемый подход к обучению, такой как глубокая нейронная сеть, может работать лучше. Но я не уверен, так как в этом случае алгоритм не сможет достичь хороших результатов с вводом, далеким от тренировочного набора. Насколько я видел, RL может лучше обобщать для этого контекста.
Вопрос состоит в том, является ли RL допустимой методологией для этой проблемы, и как в этом случае управляются состояния терминала? Вам известны подобные примеры в литературе?
2 ответа
Если я правильно понял ваш вопрос, описываемая вами проблема известна в литературе как контекстуальные бандиты. В таком случае у вас есть набор состояний, и агент получает вознаграждение после выполнения одного действия. Эти проблемы тесно связаны с Reinforcement Learning, но у них есть некоторые особенности, которые используются для разработки конкретных алгоритмов.
На следующем рисунке, извлеченном из поста Артура Джулиани, показано основное различие между проблемами "Многорукий бандит", "Контекстный бандит" и "Укрепление":
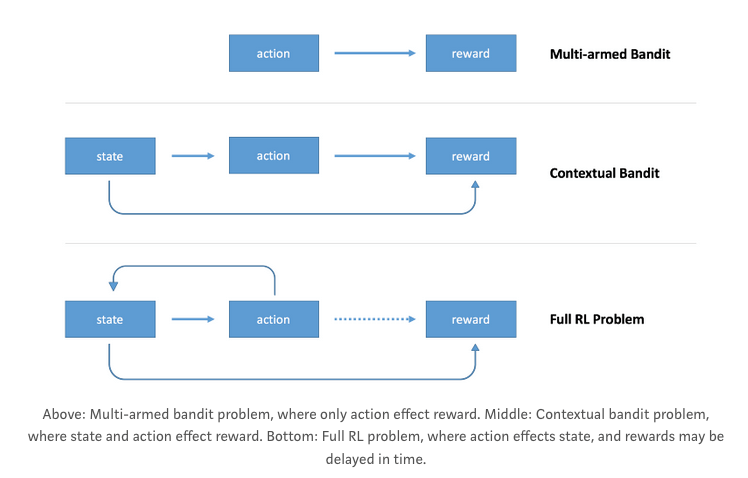
Усиленное обучение решает проблему, которой у вас нет
Основная трудность, на которую нацелены подходы RL, связана с приписыванием вознаграждения намного более ранним действиям, выяснением способов, как справиться с (распространенным) осложнением, когда нет явного отзыва о том, что (и когда) вы сделали правильно или неправильно. У вас нет этой проблемы - у вас есть немедленная награда, которая напрямую связана с действием.
Базовые подходы к обучению под наблюдением хорошо бы с этим работали, и нет никаких причин использовать "механизм" обучения с подкреплением.
В эпизодической RL следующего состояния нет, это просто оптимизация черного ящика (BB). Ваш случай является контекстным BB, поскольку у вас также есть состояние (я думаю, позиция мяча). Вы можете использовать градиент политики (например, NES или PGPE), поиск политики ( здесь хороший обзор), эволюционный ( CMA-ES) или гибридный. Они отличаются тем, как выполняется обновление, но все они не зависят от награды, то есть они не знают функцию вознаграждения, а просто получают значения вознаграждения.
Все они разделяют один и тот же подход:
- У вас есть начальная политика (так называемый поиск),
- Просматривайте функции и вводите их в политику, которая даст вам "действие" (в вашем случае: нарисуйте параметры управления роботом, затем снимайте),
- Увидеть награду,
- Повторите и соберите данные
(features, action, reward), - Обновляйте политику, пока не изучите контроллер робота, который всегда может ударить по мячу в любой позиции.
РЕДАКТИРОВАТЬ
Поскольку у вас нет следующего состояния, ваша проблема - это проблема регрессии, но вы не знаете оптимальную цель (оптимальное действие = оптимальный контроллер робота). Вместо этого вы рисуете какую-то цель и медленно подходите к лучшим (медленно, как с градиентным спуском, потому что могут быть лучшие, которые вам еще предстоит исследовать).