Как удалить дубликаты строк из выходной таблицы с помощью Pentaho DI?
Я создаю преобразование, которые принимают входные данные из файла CSV и выводят в таблицу. Это работает правильно, но проблема в том, что если я выполню это преобразование более одного раза. Затем выходная таблица содержит повторяющиеся строки снова и снова.
Теперь я хочу удалить все повторяющиеся строки из выходной таблицы.
И если я запускаю преобразование несколько раз, это не должно влиять на выходную таблицу, пока у нее не будет новой строки.
Как я могу решить это?
3 ответа
Мне приходят на ум два решения:
использование
Insert / Updateшаг вместоTable inputшаг для сохранения данных в выходную таблицу. Он попытается найти в выходной таблице строку, соответствующую строке потока входящей записи в соответствии с ключевыми полями (все поля / столбцы в вашем случае), которые вы определили. Это работает так:- Если строка не может быть найдена, она вставляет строку. Если он может быть найден и поля для обновления совпадают, ничего не делается. Если они не все одинаковые, строка в таблице обновляется.
Используйте следующие параметры:
- Ключи для поиска значений:
tableField1 = streamField1; tableField2 = streamField2; tableField3 = streamField3;и так далее.. - Обновить поля:
tableField1, streamField1, N; tableField2, streamField2, N; tableField3, streamField3, N;и так далее..
После сохранения значений дубликатов в выходной таблице вы можете удалить дубликаты, используя эту концепцию:
- использование
Execute SQL stepгде вы определяете SQL, который удаляет дублирующиеся записи и сохраняет только уникальные строки. Вы можете вдохновить вас на создание такого SQL: Как я могу удалить повторяющиеся строки?
- использование
Другой способ заключается в использовании Merge rows (diff) шаг, за которым следует Synchronize after merge шаг.
Пока количество строк в вашем CSV, которые отличаются от целевой таблицы, составляет менее 20 - 25% от общего числа, это, как правило, наиболее приемлемый для производительности вариант.
Merge rows (diff) берет два входных потока, которые должны быть отсортированы по его ключевым полям (совместимым сопоставлением), и генерирует объединение двух входных данных, где каждая строка помечена как "новая", "измененная", "удаленная" или "идентичная". Это означает, что вам придется поставить Sort rows шаги на вход CSV и, возможно, на вход из целевой таблицы, если вы не можете использовать предложение ORDER BY. Пометьте вход CSV как источник строки "Compare", а таблицу назначения как "Reference".
Synchronize after merge Затем step применяет изменения, отмеченные в строках, к целевой таблице. Обратите внимание, что Synchronize after merge это единственный шаг в PDI (я считаю), который требует ввода данных на вкладке "Дополнительно". Там вы устанавливаете поле флага и значения, которые определяют операцию строки. После применения изменений целевая таблица будет содержать те же данные, что и входной CSV.
Обратите внимание, что вы можете использовать Switch/Case или же Filter Rows шаг, чтобы сделать такие вещи, как удалить, удалить или обновить, если хотите. Я часто стекаю с "одинаковых" строк и записываю остальные в текстовый файл, чтобы я мог проверить только изменения.
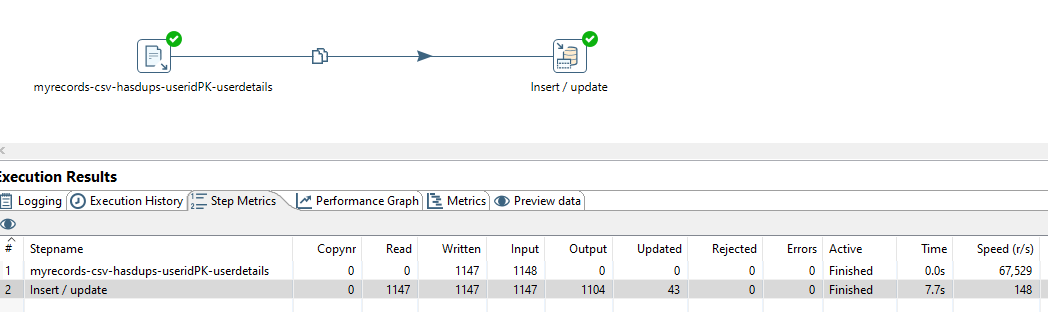
Я искал визуальные ответы, но ответы были текстовыми, поэтому добавляю этот визуальный ответ для любого новичка в чайнике, такого как я.
Кейс
user-updateslog.csv (имеет повторяющиеся значения) ---> users_table , хранит только последние сведения о пользователе.
Решение
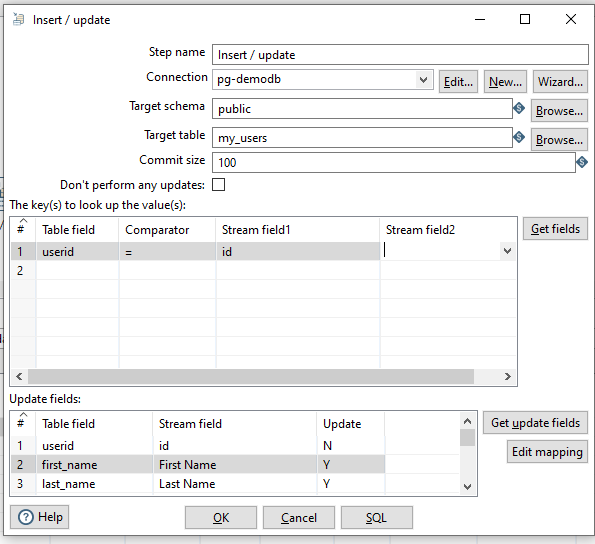
Шаг 1: Подключите csv для вставки/обновления, как показано ниже.
Шаг 2: В меню «Вставка/обновление» добавьте условие для сравнения ключей, чтобы найти строку-кандидата, и выберите поля «Y» для обновления.