Big O, как вы рассчитываете / приближаете это?
Большинство людей со степенью в CS наверняка знают, что означает Big O. Это помогает нам измерить, насколько (не) эффективен алгоритм на самом деле, и если вы знаете, в какой категории находится проблема, которую вы пытаетесь решить, вы можете выяснить, все еще возможно ли выжать эту небольшую дополнительную производительность. 1
Но мне любопытно, как вы рассчитываете или приближаете сложность ваших алгоритмов?
Но, как говорится, не переусердствуйте, преждевременная оптимизация является корнем всего зла, и оптимизация без уважительной причины должна также заслуживать этого имени.
24 ответа
I'm a professor assistant at my local university on the Data Structures and Algorithms course. I'll do my best to explain it here on simple terms, but be warned that this topic takes my students a couple of months to finally grasp. You can find more information on the Chapter 2 of the Data Structures and Algorithms in Java book.
There is no mechanical procedure that can be used to get the BigOh.
As a "cookbook", to obtain the BigOh from a piece of code you first need to realize that you are creating a math formula to count how many steps of computations get executed given an input of some size.
The purpose is simple: to compare algorithms from a theoretical point of view, without the need to execute the code. The lesser the number of steps, the faster the algorithm.
For example, let's say you have this piece of code:
int sum(int* data, int N) {
int result = 0; // 1
for (int i = 0; i < N; i++) { // 2
result += data[i]; // 3
}
return result; // 4
}
This function returns the sum of all the elements of the array, and we want to create a formula to count the computational complexity of that function:
Number_Of_Steps = f(N)
Итак, мы имеем f(N), a function to count the number of computational steps. The input of the function is the size of the structure to process. It means that this function is called such as:
Number_Of_Steps = f(data.length)
Параметр N принимает data.length значение. Now we need the actual definition of the function f(), This is done from the source code, in which each interesting line is numbered from 1 to 4.
There are many ways to calculate the BigOh. From this point forward we are going to assume that every sentence that doesn't depend on the size of the input data takes a constant C number computational steps.
We are going to add the individual number of steps of the function, and neither the local variable declaration nor the return statement depends on the size of the data массив.
That means that lines 1 and 4 takes C amount of steps each, and the function is somewhat like this:
f(N) = C + ??? + C
The next part is to define the value of the for заявление. Remember that we are counting the number of computational steps, meaning that the body of the for statement gets executed N раз. That's the same as adding C, N раз:
f(N) = C + (C + C + ... + C) + C = C + N * C + C
There is no mechanical rule to count how many times the body of the for gets executed, you need to count it by looking at what does the code do. To simplify the calculations, we are ignoring the variable initialization, condition and increment parts of the for заявление.
To get the actual BigOh we need the Asymptotic analysis of the function. This is roughly done like this:
- Take away all the constants
C, - От
f()get the polynomium in itsstandard form, - Divide the terms of the polynomium and sort them by the rate of growth.
- Keep the one that grows bigger when
Nподходыinfinity,
наш f() has two terms:
f(N) = 2 * C * N ^ 0 + 1 * C * N ^ 1
Taking away all the C constants and redundant parts:
f(N) = 1 + N ^ 1
Since the last term is the one which grows bigger when f() приближается к бесконечности (думайте о границах), это аргумент BigOh, а sum() Функция имеет значение BigOh:
O(N)
Есть несколько хитростей, чтобы решить некоторые хитрые: используйте суммирование, когда можете.
Например, этот код может быть легко решен с помощью суммирования:
for (i = 0; i < 2*n; i += 2) { // 1
for (j=n; j > i; j--) { // 2
foo(); // 3
}
}
Первое, что вам нужно было спросить, это порядок исполнения foo(), В то время как обычное должно быть O(1)Вы должны спросить об этом своих профессоров. O(1) означает (почти, в основном) постоянный Cнезависимо от размера N,
for Заявление по предложению номер один сложно. Пока индекс заканчивается 2 * Nинкремент делается на два. Это означает, что первый for исполняется только N шаги, и нам нужно разделить счет на два.
f(N) = Summation(i from 1 to 2 * N / 2)( ... ) =
= Summation(i from 1 to N)( ... )
Предложение номер два еще сложнее, так как оно зависит от значения i, Посмотрите: индекс i принимает значения: 0, 2, 4, 6, 8, ..., 2 * N и второе for исполняются: N раз первый, N - 2 второй, N - 4 третий... до этапа N / 2, на котором второй for никогда не будет казнен.
По формуле это означает:
f(N) = Summation(i from 1 to N)( Summation(j = ???)( ) )
Опять же, мы рассчитываем количество шагов. И по определению, каждое суммирование всегда должно начинаться с единицы и заканчиваться числом, большим или равным единице.
f(N) = Summation(i from 1 to N)( Summation(j = 1 to (N - (i - 1) * 2)( C ) )
(Мы предполагаем, что foo() является O(1) и берет C шагов.)
У нас тут проблема: когда i принимает значение N / 2 + 1 вверх, внутреннее суммирование заканчивается отрицательным числом! Это невозможно и неправильно. Нам нужно разделить суммирование на две части, являясь поворотным моментом i принимает N / 2 + 1,
f(N) = Summation(i from 1 to N / 2)( Summation(j = 1 to (N - (i - 1) * 2)) * ( C ) ) + Summation(i from 1 to N / 2) * ( C )
С поворотного момента i > N / 2, внутренний for не будет выполнено, и мы предполагаем постоянную сложность выполнения C в его теле.
Теперь суммирования можно упростить, используя некоторые правила идентификации:
- Суммирование (w от 1 до N)( C) = N * C
- Суммирование (w от 1 до N)( A (+/-) B) = Суммирование (w от 1 до N)( A) (+/-) Суммирование (w от 1 до N)( B)
- Суммирование (w от 1 до N)( w * C) = C * Суммирование (w от 1 до N)( w) (C является константой, независимой от
w) - Суммирование (w от 1 до N)( w) = (N * (N + 1)) / 2
Применяя некоторую алгебру:
f(N) = Summation(i from 1 to N / 2)( (N - (i - 1) * 2) * ( C ) ) + (N / 2)( C )
f(N) = C * Summation(i from 1 to N / 2)( (N - (i - 1) * 2)) + (N / 2)( C )
f(N) = C * (Summation(i from 1 to N / 2)( N ) - Summation(i from 1 to N / 2)( (i - 1) * 2)) + (N / 2)( C )
f(N) = C * (( N ^ 2 / 2 ) - 2 * Summation(i from 1 to N / 2)( i - 1 )) + (N / 2)( C )
=> Summation(i from 1 to N / 2)( i - 1 ) = Summation(i from 1 to N / 2 - 1)( i )
f(N) = C * (( N ^ 2 / 2 ) - 2 * Summation(i from 1 to N / 2 - 1)( i )) + (N / 2)( C )
f(N) = C * (( N ^ 2 / 2 ) - 2 * ( (N / 2 - 1) * (N / 2 - 1 + 1) / 2) ) + (N / 2)( C )
=> (N / 2 - 1) * (N / 2 - 1 + 1) / 2 =
(N / 2 - 1) * (N / 2) / 2 =
((N ^ 2 / 4) - (N / 2)) / 2 =
(N ^ 2 / 8) - (N / 4)
f(N) = C * (( N ^ 2 / 2 ) - 2 * ( (N ^ 2 / 8) - (N / 4) )) + (N / 2)( C )
f(N) = C * (( N ^ 2 / 2 ) - ( (N ^ 2 / 4) - (N / 2) )) + (N / 2)( C )
f(N) = C * (( N ^ 2 / 2 ) - (N ^ 2 / 4) + (N / 2)) + (N / 2)( C )
f(N) = C * ( N ^ 2 / 4 ) + C * (N / 2) + C * (N / 2)
f(N) = C * ( N ^ 2 / 4 ) + 2 * C * (N / 2)
f(N) = C * ( N ^ 2 / 4 ) + C * N
f(N) = C * 1/4 * N ^ 2 + C * N
И BigOh это:
O(N²)
Большое О дает верхнюю границу временной сложности алгоритма. Обычно он используется в сочетании с обработкой наборов данных (списков), но может использоваться в другом месте.
Несколько примеров того, как это используется в C-коде.
Скажем, у нас есть массив из n элементов
int array[n];
Если бы мы хотели получить доступ к первому элементу массива, это было бы O(1), поскольку не имеет значения, насколько велик массив, всегда требуется одно и то же постоянное время для получения первого элемента.
x = array[0];
Если мы хотим найти номер в списке:
for(int i = 0; i < n; i++){
if(array[i] == numToFind){ return i; }
}
Это будет O(n), так как в большинстве случаев нам нужно будет просмотреть весь список, чтобы найти наш номер. Big-O по-прежнему равен O(n), хотя мы можем найти наше число с первой попытки и один раз пройти через цикл, потому что Big-O описывает верхнюю границу для алгоритма (омега - для нижней границы, а тета - для жесткой границы),
Когда мы доберемся до вложенных циклов:
for(int i = 0; i < n; i++){
for(int j = i; j < n; j++){
array[j] += 2;
}
}
Это O(n^2), так как для каждого прохода внешнего цикла ( O(n)) мы должны снова пройти весь список, чтобы n умножалось, оставляя нас с n в квадрате.
Это едва царапает поверхность, но когда вы приступаете к анализу более сложных алгоритмов, в игру вступает сложная математика, включающая доказательства. Надеюсь, это хотя бы знакомит вас с основами.
Хотя знание того, как рассчитать время Big O для вашей конкретной проблемы, полезно, знание некоторых общих случаев может иметь большое значение, помогая вам принимать решения в своем алгоритме.
Вот некоторые из наиболее распространенных случаев, взятых из http://en.wikipedia.org/wiki/Big_O_notation:
O (1) - определение, является ли число четным или нечетным; используя таблицу соответствия постоянного размера или хэш-таблицу
O (logn) - поиск элемента в отсортированном массиве с помощью двоичного поиска
O (n) - поиск элемента в несортированном списке; добавление двух n-значных чисел
O (n2) - Умножение двух n-значных чисел простым алгоритмом; добавление двух n×n матриц; пузырьковая сортировка или вставка
O (n3) - Умножение двух матриц n×n простым алгоритмом
O (cn) - поиск (точного) решения задачи коммивояжера с использованием динамического программирования; определение, если два логических утверждения эквивалентны, используя грубую силу
O(n!) - Решение проблемы коммивояжера с помощью перебора
O (nn) - часто используется вместо O (n!) Для получения более простых формул для асимптотической сложности
Небольшое напоминание: big O нотация используется для обозначения асимптотической сложности (то есть, когда размер задачи растет до бесконечности), и она скрывает константу.
Это означает, что между алгоритмом в O(n) и алгоритмом в O (n2) самый быстрый не всегда является первым (хотя всегда существует значение n такое, что для задач размером> n первый алгоритм самый быстрый).
Обратите внимание, что скрытая константа очень сильно зависит от реализации!
Кроме того, в некоторых случаях среда выполнения не является детерминированной функцией размера n входных данных. Возьмем, к примеру, сортировку с использованием быстрой сортировки: время, необходимое для сортировки массива из n элементов, не является константой, а зависит от начальной конфигурации массива.
Есть разные временные сложности:
- Худший случай (обычно самый простой, но не всегда очень значимый)
Средний случай (как правило, гораздо сложнее выяснить...)
...
Хорошим введением является Введение в анализ алгоритмов Р. Седжвика и П. Флайолета.
Как ты говоришь, premature optimisation is the root of all evilи (если возможно) профилирование действительно всегда должно использоваться при оптимизации кода. Это может даже помочь вам определить сложность ваших алгоритмов.
Видя ответы здесь, я думаю, мы можем заключить, что большинство из нас действительно приближают порядок алгоритма, взглянув на него, и используют здравый смысл вместо того, чтобы вычислять его, например, с помощью основного метода, как мы думали в университете. С учетом вышесказанного я должен добавить, что даже профессор побуждал нас (позже) на самом деле думать об этом, а не просто рассчитывать.
Также я хотел бы добавить, как это делается для рекурсивных функций:
Предположим, у нас есть такая функция ( код схемы):
(define (fac n)
(if (= n 0)
1
(* n (fac (- n 1)))))
который рекурсивно вычисляет факториал данного числа.
Первый шаг - попытаться определить характеристику производительности для тела функции, только в этом случае в теле ничего особенного не делается, только умножение (или возвращение значения 1).
Таким образом, производительность для тела: O (1) (постоянная).
Затем попытайтесь определить это для количества рекурсивных вызовов. В этом случае у нас n-1 рекурсивных вызовов.
Таким образом, производительность для рекурсивных вызовов: O (n-1) (порядок равен n, так как мы отбрасываем незначительные части).
Затем сложите их вместе, и вы получите производительность для всей рекурсивной функции:
1 * (n-1) = O (n)
Peteter, чтобы ответить на твои поднятые вопросы; метод, который я здесь описываю, на самом деле хорошо справляется с этим. Но имейте в виду, что это все же приблизительный, а не полный математически правильный ответ. Описанный здесь метод также является одним из методов, которым нас учили в университете, и, если я правильно помню, использовался для гораздо более сложных алгоритмов, чем факториал, который я использовал в этом примере.
Конечно, все зависит от того, насколько хорошо вы сможете оценить время выполнения тела функции и количество рекурсивных вызовов, но это верно и для других методов.
Если ваша стоимость является полиномом, просто оставьте член высшего порядка без его множителя. Например:
O ((n / 2 + 1) * (n / 2)) = O (n 2/4 + n / 2) = O (n 2/4) = O (n 2)
Заметьте, это не работает для бесконечных серий. Единого рецепта для общего случая не существует, хотя для некоторых общих случаев применяются следующие неравенства:
O (log N)
N) N log N) N 2) N k) n) n!)
Я думаю об этом с точки зрения информации. Любая проблема состоит в изучении определенного количества битов.
Ваш основной инструмент - это концепция точек принятия решений и их энтропия. Энтропия точки принятия решения - это усредненная информация, которую она вам даст. Например, если программа содержит точку принятия решения с двумя ветвями, ее энтропия - это сумма вероятностей каждой ветви, умноженная на log2 обратной вероятности этой ветви. Вот как много вы узнаете, выполнив это решение.
Например, if утверждение, имеющее две ветви, одинаково вероятные, имеет энтропию 1/2 * log(2/1) + 1/2 * log(2/1) = 1/2 * 1 + 1/2 * 1 = 1. его энтропия составляет 1 бит.
Предположим, вы ищете таблицу из N элементов, например N=1024. Это 10-битная проблема, потому что log(1024) = 10 бит. Поэтому, если вы можете искать его с помощью утверждений IF, которые имеют одинаково вероятные результаты, необходимо принять 10 решений.
Вот что вы получаете с помощью бинарного поиска.
Предположим, вы делаете линейный поиск. Вы смотрите на первый элемент и спрашиваете, хотите ли вы. Вероятности составляют 1/1024, а 1023/1024 - нет. Энтропия этого решения составляет 1/1024*log(1024/1) + 1023/1024 * log(1024/1023) = 1/1024 * 10 + 1023/1024 * около 0 = около 0,01 бита. Вы узнали очень мало! Второе решение не намного лучше. Вот почему линейный поиск такой медленный. На самом деле это экспоненциальное количество бит, которые вам нужно выучить.
Предположим, вы занимаетесь индексацией. Предположим, что таблица предварительно отсортирована по множеству бинов, и вы используете некоторые из всех битов в ключе для индексации непосредственно к записи таблицы. При наличии 1024 бинов энтропия составляет 1/1024 * log(1024) + 1/1024 * log(1024) + ... для всех 1024 возможных результатов. Это 1/1024 * 10 × 1024 результатов или 10 битов энтропии для этой одной операции индексации. Вот почему поиск по индексу происходит быстро.
Теперь подумайте о сортировке. У вас есть N предметов, и у вас есть список. Для каждого элемента вы должны найти, куда он попадает в список, а затем добавить его в список. Таким образом, сортировка занимает примерно N раз количество шагов основного поиска.
Таким образом, сортировки, основанные на бинарных решениях, имеющих примерно одинаково вероятные результаты, все делают за O(N log N) шагов Алгоритм сортировки O(N) возможен, если он основан на поиске по индексу.
Я обнаружил, что почти все проблемы алгоритмической производительности можно рассматривать таким образом.
Давайте начнем с самого начала.
Прежде всего, примите принцип, что некоторые простые операции с данными могут быть выполнены в O(1) время, то есть время, которое не зависит от размера ввода. Эти примитивные операции в C состоят из
- Арифметические операции (например, + или%).
- Логические операции (например, &&).
- Операции сравнения (например, <=).
- Операции доступа к структуре (например, индексирование массива, например, A[i], или указатель с оператором ->).
- Простое присваивание, такое как копирование значения в переменную.
- Вызовы библиотечных функций (например, scanf, printf).
Обоснование этого принципа требует детального изучения машинных инструкций (примитивных шагов) типичного компьютера. Каждая из описанных операций может быть выполнена с небольшим количеством машинных инструкций; часто требуется только одна или две инструкции. Как следствие, несколько видов операторов в C могут быть выполнены в O(1) время, то есть в некотором постоянном количестве времени, не зависящем от ввода. Эти простые включают
- Операторы присваивания, которые не включают вызовы функций в своих выражениях.
- Читайте заявления.
- Напишите операторы, которые не требуют вызовов функций для оценки аргументов.
- Операторы прыжка break, continue, goto и возвращают выражение, где выражение не содержит вызова функции.
В Си многие циклы for формируются путем инициализации переменной индекса некоторым значением и увеличения этой переменной на 1 каждый раз вокруг цикла. Цикл for заканчивается, когда индекс достигает некоторого предела. Например, цикл for
for (i = 0; i < n-1; i++)
{
small = i;
for (j = i+1; j < n; j++)
if (A[j] < A[small])
small = j;
temp = A[small];
A[small] = A[i];
A[i] = temp;
}
использует индексную переменную i. Он увеличивает i на 1 каждый раз вокруг цикла, и итерации прекращаются, когда i достигает n - 1.
Однако, на данный момент, сосредоточимся на простой форме цикла for, где разница между конечным и начальным значениями, деленная на величину, на которую увеличивается индексная переменная, говорит нам, сколько раз мы обходим цикл. Это количество является точным, если нет способов выйти из цикла с помощью оператора jump; в любом случае это верхняя граница числа итераций.
Например, цикл for повторяется ((n − 1) − 0)/1 = n − 1 timesтак как 0 - начальное значение i, n - 1 - наибольшее значение, достигнутое i (то есть, когда i достигает n − 1, цикл останавливается, и итерация не происходит с i = n−1), и 1 добавляется к я на каждой итерации цикла.
В простейшем случае, когда время, проведенное в теле цикла, одинаково для каждой итерации, мы можем умножить верхнюю границу большого тела для тела на количество раз вокруг цикла. Строго говоря, мы должны затем добавить O(1) время для инициализации индекса цикла и O(1) время для первого сравнения индекса цикла с пределом, потому что мы тестируем еще один раз, чем обходим цикл. Однако, если нет возможности выполнить цикл ноль раз, время инициализации цикла и однократной проверки предела является членом низкого порядка, который может быть отброшен правилом суммирования.
Теперь рассмотрим этот пример:
(1) for (j = 0; j < n; j++)
(2) A[i][j] = 0;
Мы знаем, что строка (1) занимает O(1) время. Ясно, что мы обходим цикл n раз, как мы можем определить, вычитая нижний предел из верхнего предела, найденного в строке (1), и затем добавляя 1. Поскольку тело, строка (2), занимает O(1) времени, мы можем пренебречь временем увеличения j и временем сравнения j с n, оба из которых также являются O(1). Таким образом, время выполнения строк (1) и (2) является произведением n и O(1), которое O(n),
Точно так же мы можем ограничить время выполнения внешнего цикла, состоящего из линий (2) - (4), что
(2) for (i = 0; i < n; i++)
(3) for (j = 0; j < n; j++)
(4) A[i][j] = 0;
Мы уже установили, что цикл линий (3) и (4) занимает O(n) времени. Таким образом, мы можем пренебречь временем O(1), чтобы увеличить i и проверить, является ли i Инициализация i = 0 внешнего цикла и (n + 1) -й тест условия i Более практичный пример.
Если вы хотите оценить порядок вашего кода эмпирически, а не анализировать код, вы можете использовать ряд возрастающих значений n и время вашего кода. Составьте график времени в логарифмическом масштабе. Если код O(x^n), значения должны располагаться на линии наклона n.
Это имеет несколько преимуществ по сравнению с простым изучением кода. Во-первых, вы можете увидеть, находитесь ли вы в диапазоне, когда время выполнения приближается к асимптотическому порядку. Кроме того, вы можете обнаружить, что некоторый код, который, по вашему мнению, был порядка O(x), действительно является порядком O(x^2), например, из-за времени, затрачиваемого на библиотечные вызовы.
В основном, вещь, которая возникает в 90% случаев, это просто анализ циклов. У вас есть одинарные, двойные, тройные вложенные циклы? У вас есть O(n), O(n^2), O(n^3) время выполнения.
Очень редко (если вы не пишете платформу с обширной базовой библиотекой (например,.NET BCL или C++ STL), вы столкнетесь с чем-нибудь более сложным, чем просто просмотр ваших циклов (для операторов while, goto, так далее...)
Я думаю, что в целом он менее полезен, но для полноты картины есть также большая омега Ω, которая определяет нижнюю границу сложности алгоритма, и большая тэта Θ, которая определяет как верхнюю, так и нижнюю границу.
Обозначение Big O полезно, потому что с ним легко работать и оно скрывает ненужные сложности и детали (для некоторого определения ненужных). Один хороший способ выяснить сложность алгоритмов "разделяй и властвуй" - это метод дерева. Допустим, у вас есть версия быстрой сортировки с медианной процедурой, поэтому вы каждый раз разбиваете массив на идеально сбалансированные подмассивы.
Теперь создайте дерево, соответствующее всем массивам, с которыми вы работаете. В корне у вас есть исходный массив, корень имеет двух дочерних элементов, которые являются подмассивами. Повторяйте это до тех пор, пока у вас не будет единственных массивов элементов внизу.
Поскольку мы можем найти медиану за время O(n) и разделить массив на две части за время O(n), работа, выполняемая на каждом узле, - это O (k), где k - это размер массива. Каждый уровень дерева содержит (самое большее) весь массив, поэтому работа на уровень составляет O(n) (размеры подмассивов складываются до n, и, поскольку у нас есть O (k) на уровень, мы можем сложить это), В дереве есть только уровни log (n), так как каждый раз мы вдвое сокращаем ввод.
Поэтому мы можем ограничить объем работы сверху (O * n log (n)).
Однако Big O скрывает некоторые детали, которые мы иногда не можем игнорировать. Рассмотрим вычисление последовательности Фибоначчи с
a=0;
b=1;
for (i = 0; i <n; i++) {
tmp = b;
b = a + b;
a = tmp;
}
и давайте просто предположим, что a и b являются BigIntegers в Java или что-то, что может обрабатывать произвольно большие числа. Большинство людей сказали бы, что это алгоритм O(n) без дрожания. Причина в том, что у вас есть n итераций в цикле for, а O (1) работает в стороне цикла.
Но числа Фибоначчи большие, n-е число Фибоначчи является экспоненциальным по n, поэтому простое его сохранение займет порядка n байтов. Выполнение сложения с большими целыми числами потребует O(n) объема работы. Таким образом, общий объем работы, выполненной в этой процедуре
1 + 2 + 3 + ... + n = n(n-1)/2 = O(n^2)
Так что этот алгоритм работает в квадратичное время!
Я хотел бы объяснить Big-O в несколько ином аспекте.
Big-O просто сравнивает сложность программ, которая показывает, насколько быстро они растут, когда увеличиваются входные данные, а не точное время, затрачиваемое на выполнение действия.
ИМХО в формулах big-O лучше не использовать более сложные уравнения (вы можете просто придерживаться приведенных на следующем графике.) Однако вы все равно можете использовать другие более точные формулы (например, 3^n, n^3, ...) но иногда это может вводить в заблуждение! Так что лучше держать это как можно проще.
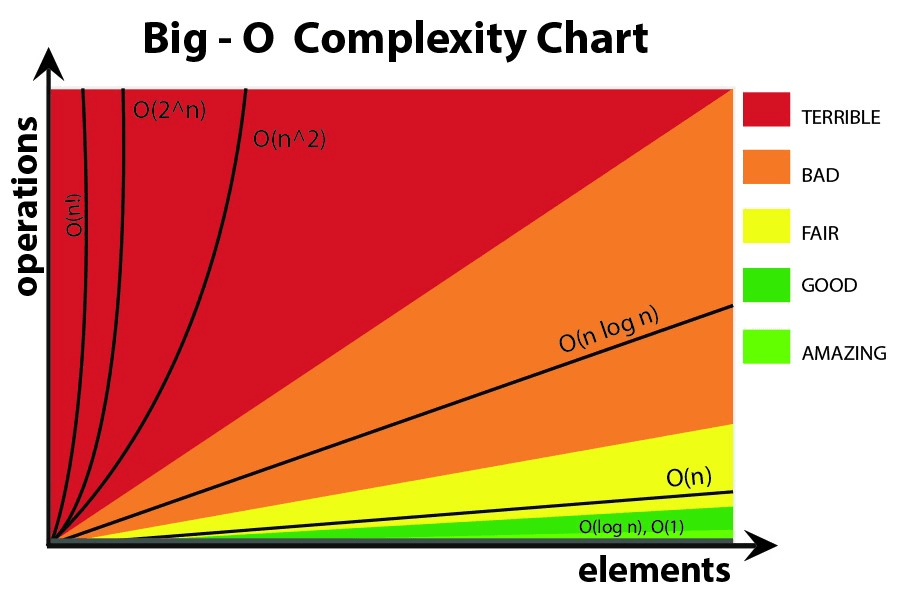
Я хотел бы еще раз подчеркнуть, что здесь мы не хотим получить точную формулу для нашего алгоритма. Мы только хотим показать, как он растет, когда входы растут, и сравнить в этом смысле с другими алгоритмами. В противном случае вам лучше использовать другие методы, такие как бенчмаркинг.
Знакомство с алгоритмами / структурами данных, которые я использую, и / или быстрый анализ вложенности итераций. Сложность заключается в том, что вы вызываете библиотечную функцию, возможно, несколько раз - вы часто можете быть не уверены в том, вызываете ли вы функцию излишне время от времени или какую реализацию они используют. Возможно, библиотечные функции должны иметь меру сложности / эффективности, будь то Big O или какой-либо другой показатель, который доступен в документации или даже IntelliSense.
Разбейте алгоритм на части, для которых вы знаете большие обозначения O, и объедините их с помощью больших операторов O. Это единственный способ, которым я знаю.
Для получения дополнительной информации, проверьте страницу Википедии на эту тему.
Для 1-го случая внутренний цикл выполняется n-i раз, поэтому общее количество казней является суммой i собирается из 0 в n-1 (потому что ниже, не ниже или равно) n-i, Вы получаете наконец n*(n + 1) / 2, так O(n²/2) = O(n²),
Для 2-го цикла i находится между 0 а также n включен для внешней петли; тогда внутренний цикл выполняется, когда j строго больше, чем n, что тогда невозможно.
Что касается того, "как вы рассчитываете" Big O, это часть теории вычислительной сложности. В некоторых (многих) особых случаях вы можете использовать несколько простых эвристических методов (например, подсчет числа циклов для вложенных циклов), особенно. когда все, что вам нужно, это какая-либо верхняя оценка, и вы не возражаете, если она слишком пессимистична - наверное, именно в этом и заключается ваш вопрос.
Если вы действительно хотите ответить на свой вопрос для любого алгоритма, лучшее, что вы можете сделать, это применить теорию. Помимо упрощенного анализа "наихудшего случая" я нашел амортизированный анализ очень полезным на практике.
Не забудьте также учесть космические сложности, которые также могут вызывать беспокойство, если у вас ограниченные ресурсы памяти. Так, например, вы можете услышать, что кто-то хочет использовать алгоритм с постоянным пространством, который, по сути, является способом сказать, что объем пространства, занимаемого алгоритмом, не зависит от каких-либо факторов внутри кода.
Иногда сложность может возникнуть из-за того, сколько раз что-то вызывается, как часто выполняется цикл, как часто выделяется память, и так далее, это еще одна часть ответа на этот вопрос.
Наконец, большой O может использоваться для наихудшего случая, лучшего случая и случаев амортизации, где обычно это наихудший случай, который используется для описания того, насколько плохим может быть алгоритм.
Прежде всего, принятый ответ пытается объяснить красивые причудливые вещи,
но я думаю, что намеренное усложнение Big-Oh - это не то решение,
которое ищут программисты (или, по крайней мере, люди вроде меня).
Big Oh (короче)
function f(text) {
var n = text.length;
for (var i = 0; i < n; i++) {
f(string.slice(0, n-1))
}
// ... other JS logic here, which we can ignore ...
}
Big Oh из вышеизложенного - это f (n) = O (n!), Где n представляет
numberэлементов во входном наборе, а f представляет
operation сделано по пункту.
Обозначение Big-Oh - это асимптотическая верхняя граница сложности алгоритма.
В программировании: предполагаемое время наихудшего случая
или предполагаемое максимальное количество повторений логики для размера входа.
Расчет
Имейте в виду (в смысле сверху), что; Нам просто нужно время наихудшего случая и / или максимальное количество повторов, на которое влияет N (размер ввода).
Затем еще раз взгляните на пример (принятого ответа):
for (i = 0; i < 2*n; i += 2) { // line 123
for (j=n; j > i; j--) { // line 124
foo(); // line 125
}
}
Начните с этого шаблона поиска:
- Найдите первую строку, в которой N вызвало повторяющееся поведение,
- Или вызвало увеличение выполняемой логики,
- Но постоянно или нет, игнорируйте все, что находится перед этой строкой.
Кажется, мы ищем строку сто двадцать три ;-)
- На первый взгляд кажется, что линия имеет
2*nмакс-зацикливание. - Но, посмотрев снова, мы видим
i += 2(и эта половина пропускается). - Итак, максимальное повторение - это просто n , запишите его, например
f(n) = O( nно пока не закрывайте скобки.
- На первый взгляд кажется, что линия имеет
Повторите поиск до конца метода и найдите следующую строку, соответствующую нашему шаблону поиска, вот это строка 124
- Что сложно, потому что странное состояние и обратный цикл.
- Но после того, как мы вспомнили, что нам просто нужно учитывать максимальное количество повторов (или время наихудшего случая).
- Это так же просто, как сказать "обратная петля
jначинается сj=n, я прав? да, n кажется максимально возможным числом повторов ", поэтому добавьтеnдо конца предыдущей записи, но вроде "( n" (вместо+ n, так как это находится внутри предыдущего цикла) и закрывающими скобками, только если мы находим что-то за пределами предыдущего цикла.
Поиск завершен! Зачем? потому что строка 125 (или любая другая более поздняя) не соответствует нашему поисковому шаблону.
Теперь мы можем закрыть любую круглую скобку (оставленную в нашей записи), что приведет к следующему:
f(n) = O( n( n ) )
Попробуйте еще больше сократить "
n( n )"часть, например:
- п (п) = п * п
- = n 2
- Наконец, просто оберните его нотацией Big Oh, например O(n2) или O(n^2), без форматирования.
Помимо использования основного метода (или одной из его специализаций), я тестирую свои алгоритмы экспериментально. Это не может доказать, что какой-либо конкретный класс сложности достигнут, но это может дать уверенность в том, что математический анализ уместен. Чтобы помочь с этим заверением, я использую инструменты покрытия кода в сочетании с моими экспериментами, чтобы гарантировать, что я выполняю все случаи.
В качестве очень простого примера скажем, что вы хотели проверить правильность сортировки списка.NET Framework. Вы можете написать что-то вроде следующего, а затем проанализировать результаты в Excel, чтобы убедиться, что они не превышают кривую n * log (n).
В этом примере я измеряю количество сравнений, но также целесообразно изучить фактическое время, необходимое для каждого размера выборки. Однако тогда вы должны быть еще более осторожны, когда вы просто измеряете алгоритм и не учитываете артефакты из вашей тестовой инфраструктуры.
int nCmp = 0;
System.Random rnd = new System.Random();
// measure the time required to sort a list of n integers
void DoTest(int n)
{
List<int> lst = new List<int>(n);
for( int i=0; i<n; i++ )
lst[i] = rnd.Next(0,1000);
// as we sort, keep track of the number of comparisons performed!
nCmp = 0;
lst.Sort( delegate( int a, int b ) { nCmp++; return (a<b)?-1:((a>b)?1:0)); }
System.Console.Writeline( "{0},{1}", n, nCmp );
}
// Perform measurement for a variety of sample sizes.
// It would be prudent to check multiple random samples of each size, but this is OK for a quick sanity check
for( int n = 0; n<1000; n++ )
DoTest(n);
Что часто упускается из виду, так это ожидаемое поведение ваших алгоритмов. Это не меняет Big-O вашего алгоритма, но относится к утверждению "преждевременная оптимизация. .."
Ожидаемое поведение вашего алгоритма - очень глупо - насколько быстро вы можете ожидать, что ваш алгоритм будет работать с данными, которые вы, скорее всего, увидите.
Например, если вы ищете значение в списке, это O(n), но если вы знаете, что большинство списков, которые вы видите, имеют ваше значение заранее, типичное поведение вашего алгоритма быстрее.
Чтобы по-настоящему закрепить это, вам нужно уметь описать распределение вероятностей вашего "пространства ввода" (если вам нужно отсортировать список, как часто этот список уже будет отсортирован? Как часто он полностью переворачивается? Как часто это в основном отсортировано?) Не всегда возможно, что вы это знаете, но иногда вы знаете.
Отличный вопрос!
Если вы используете Big O, вы говорите о худшем случае (подробнее о том, что это значит позже). Кроме того, есть тэта-столица для среднего случая и большая омега для лучшего случая.
Посетите этот сайт, чтобы получить прекрасное формальное определение Big O: https://xlinux.nist.gov/dads/HTML/bigOnotation.html
f (n) = O (g (n)) означает, что существуют положительные постоянные c и k, такие что 0 ≤ f(n) ≤ cg(n) для всех n ≥ k. Значения c и k должны быть фиксированы для функции f и не должны зависеть от n.
Хорошо, теперь, что мы подразумеваем под сложностями "лучший случай" и "худший случай"?
Это, вероятно, наиболее четко показано на примерах. Например, если мы используем линейный поиск, чтобы найти число в отсортированном массиве, то наихудший случай - это когда мы решаем искать последний элемент массива, поскольку для этого потребуется столько шагов, сколько элементов в массиве. Наилучший случай был бы, когда мы ищем первый элемент, так как мы сделали бы после первой проверки.
Смысл всех этих сложностей прилагательного в том, что мы ищем способ построить график времени, в течение которого гипотетическая программа выполняется до конца, с точки зрения размера определенных переменных. Однако для многих алгоритмов можно утверждать, что не существует единственного времени для определенного размера ввода. Обратите внимание, что это противоречит основному требованию функции, любой вход должен иметь не более одного выхода. Итак, мы придумали несколько функций для описания сложности алгоритма. Теперь, даже если поиск в массиве размера n может занимать различное количество времени в зависимости от того, что вы ищете в массиве и пропорционально n, мы можем создать информативное описание алгоритма, используя лучший случай, средний случай и наихудшие классы.
Извините, это так плохо написано и не хватает технической информации. Но, надеюсь, это облегчит думать о классах сложности времени. Как только вы освоитесь с ними, вам станет просто разбирать вашу программу и искать такие вещи, как циклы for, которые зависят от размеров массива и рассуждений, основанных на ваших структурах данных, какой тип ввода приведет к тривиальным случаям, а какой - к получению. в худших случаях.
Для кода A внешний цикл будет выполняться n+1 раз, время '1' означает процесс, который проверяет, соответствует ли i требованию. И внутренний цикл выполняется n раз, n-2 раза.... Таким образом, 0+2+..+(n-2)+n= (0+n)(n+1)/2= O(n²).
Для кода B, хотя внутренний цикл не вступает и не выполняет foo(), внутренний цикл будет выполняться в течение n раз, в зависимости от времени выполнения внешнего цикла, которое равно O(n)
Я не знаю, как программно решить эту проблему, но первое, что делают люди, это то, что мы выбираем алгоритм для определенных шаблонов по количеству выполненных операций, скажем, 4n^2 + 2n + 1, у нас есть 2 правила:
- Если у нас есть сумма терминов, то термин с наибольшим темпом роста сохраняется, а другие термины опускаются.
- Если мы имеем произведение нескольких факторов, то постоянные факторы не учитываются.
Если мы упростим f(x), где f (x) - формула для числа выполненных операций (4n^2 + 2n + 1, объясненное выше), мы получим значение big-O [O(n^2) в этом дело]. Но это должно было бы учитывать интерполяцию Лагранжа в программе, что может быть трудно реализовать. И что, если реальное значение big-O было O(2^n), и у нас могло бы быть что-то вроде O(x^n), поэтому этот алгоритм, вероятно, не был бы программируемым. Но если кто-то докажет, что я неправ, дайте мне код.,,,