Разбор MathML операторов с использованием ANTLR
Я пытаюсь разобрать Presentation MathML и построить AST с помощью ANTLR. У меня есть большинство поддерживаемых тегов, и я могу создавать узлы для конкретных конструкций.
У меня проблемы с операторами. На этой странице;
http://www.w3.org/TR/MathML3/appendixc.html
Существует список операторов, форма, в которой они отображаются по умолчанию (префикс, инфикс или postifx) и значение приоритета, которое дает приоритет оператору.
Я мог бы взять каждый код оператора и добавить его в свой лексер, а затем написать правила для унарных, двоичных и постфиксных выражений, основанные на приоритете, точно так же, как я написал бы выражения для C или некоторого другого языка программирования.
Проблема заключается в том, что теги оператора могут содержать атрибут "form", который может принимать значения "prefix", "infix" и "postfix", которые изменяют древовидную структуру. Я не могу видеть атрибуты до стадии парсера.
Кроме того, тег оператора может содержать естественный язык, чтобы действовать как оператор, поэтому я не могу определить приоритет и, таким образом, построить правильное дерево.
Можно ли было игнорировать приоритет оператора на этапе синтаксического анализа, просто загрузить выражения в виде списка узлов и затем переписать дерево на семантической стадии, используя обходчик дерева? На этом этапе у меня были бы значения атрибутов, и я держу словарь известных операторов и их приоритет / приоритет.
Это важная веха в моем прогрессе, потому что я должен решить, что мне делать, прежде чем продолжить.
РЕДАКТИРОВАТЬ
У меня есть следующее выражение MathML...
<math>
<mrow>
<mi>a</mi>
<mo>+</mo>
<mi>b</mi>
<mo>+</mo>
<mi>c</mi>
</mrow>
</math>
Я могу построить два разных дерева...

или же...
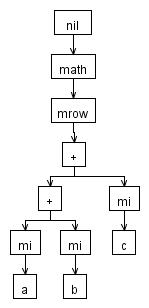
Второй кодирует ассоциативность оператора "+" в дереве, и это то, что мы обычно делаем для языков программирования.
Но в спецификации есть сотни операторов, и поэтому у меня будет очень большая грамматика и множество альтернатив в моих правилах производства.
Естественный язык также может быть использован (хотя на самом деле не должен) для операторов...
<math>
<mrow>
<mo>there exists</mo>
<mi>x</mi>
<mo>in</mo>
<mi>S</mi>
</mrow>
</math>
Итак, я спрашиваю, как лучше всего кодировать операторы в дереве. Я пытаюсь преобразовать презентацию MathML в Content MathML, поэтому мне нужно проанализировать семантику презентации, чтобы иметь возможность решить, что это означает математически.
Есть ли способ преобразовать первое дерево во второе в фазе древовидной грамматики?
РЕДАКТИРОВАТЬ
У меня есть следующий MathML и сгенерированное дерево...
<math>
<mrow>
<mi>a</mi>
<mo>+</mo>
<mi>b</mi>
<mo>+</mo>
<mi>c</mi>
</mrow>
</math>
Вот простая грамматика дерева, которую я хочу использовать, чтобы найти любую MO узлы, которые находятся между другими узлами, например MI...
tree grammar SimpleReWriter;
options
{
tokenVocab = MathML;
ASTLabelType = CommonTree;
output = AST;
backtrack = true;
language = CSharp3;
filter = true; // use pattern matching
rewrite = true;
}
topdown: findInfix; // look for infix operators
findInfix : ^(MROW left=.+ MO right=.+) -> ^(MROW ^(MO $left $right));
Моя программа вылетает внутри SimpleReWriter класс, с сообщением об ошибке: Operation is not valid due to the current state of the object.
Моя грамматика дерева работает, если был только один + между узлами, но при наличии последовательности из более чем одного происходит сбой.