Категоризация коротких аудиосэмплов
У меня есть небольшое количество похожих типов звуков (я буду называть их DB_sounds), которым нужно сопоставить запись (Rec_sounds). Каждый Rec_sound является коротким и уникальным и должен соответствовать его соответствующему DB_sound. Как мне их сопоставить?
Чтобы проиллюстрировать мою проблему, рассмотрим следующее:
Боб, с глубоким голосом в комнате А (с некоторым фоновым шумом) говорит Ма
Алиса, с высоким голосом в комнате B говорит Э
Ребенок учится говорить. Его первое слово Эх
Ma и Eh - два разных типа DB_sounds, поэтому я должен вернуть два разных результата. У меня есть несколько образцов DB_sound разных людей, говорящих Ma и Eh, чтобы сравнить Rec_sounds с
Звуки, с которыми я имею дело, - это голосовые записи отдельных слогов, такие как la, ba, ne, eh, ma и т. Д.
Как я должен заняться этим?
Я не думаю, что аудио-дактилоскопия будет работать (см. Спектрограмму), и существующее программное обеспечение для распознавания голоса, такое как эта интеграция google api в python, не работает, так как я не пытаюсь распознавать человеческий язык, а просто звучит.
Я не против построить что-то с нуля, просто укажите мне направление, которое, по вашему мнению, будет работать, и, пожалуйста, добавьте множество обоснований, почему вы так думаете.
Спектрограммы 8 образцов детской поговорки Э.Х.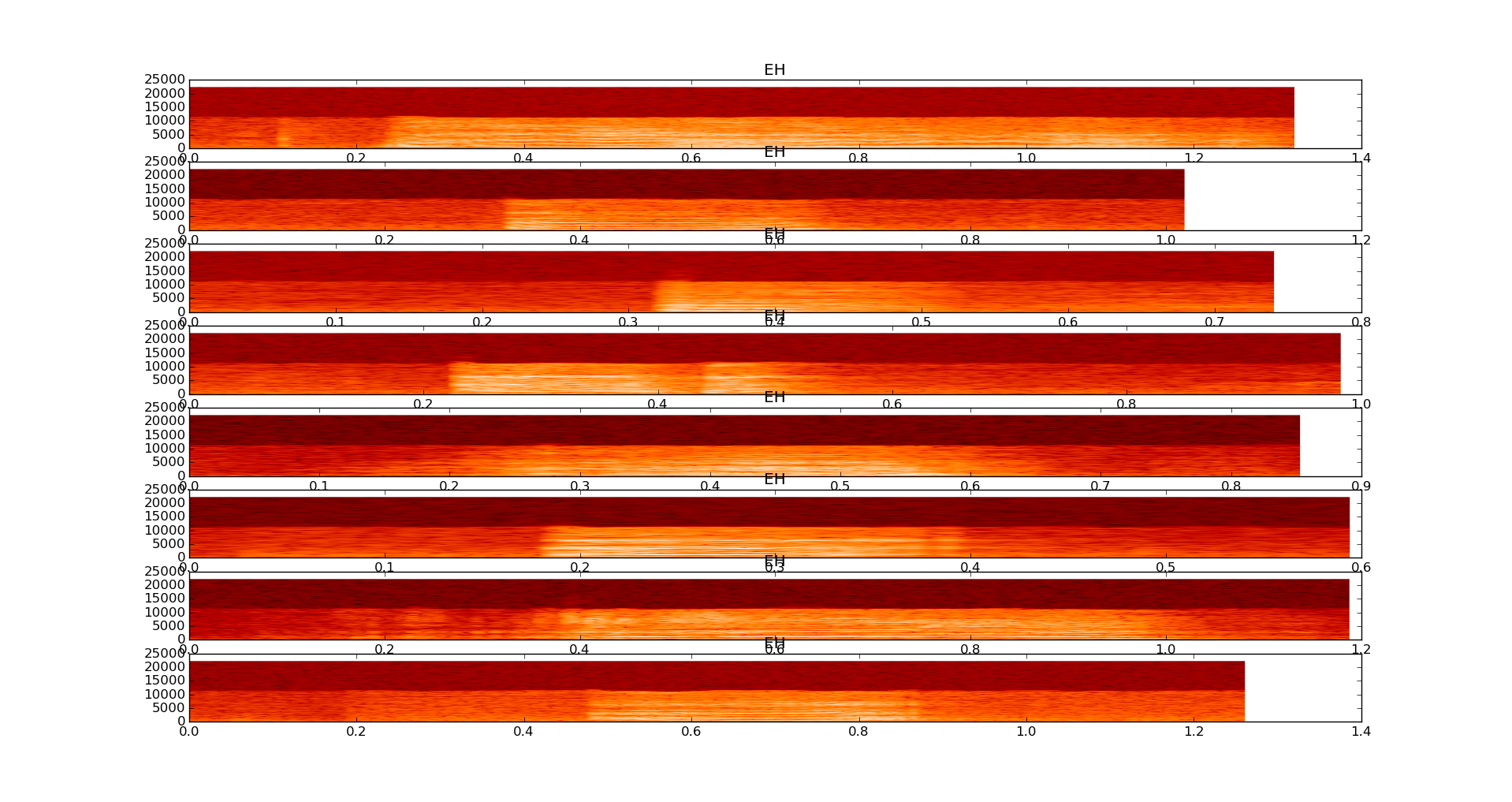
Графики временной области 8 образцов детской поговорки EH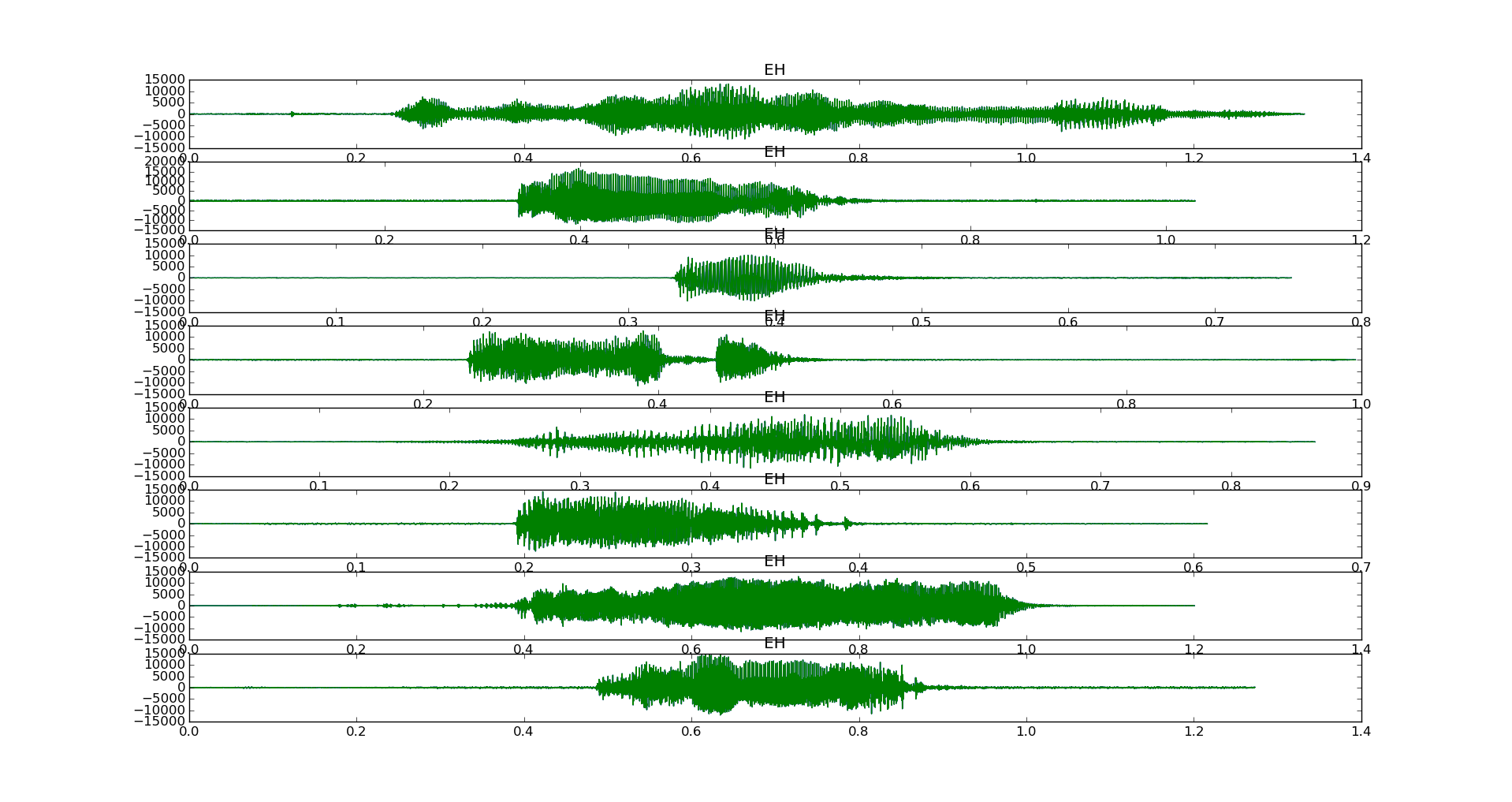
1 ответ
Если вы просто хотите распознать звуки, я бы начал с простой процедуры:
- Обрезка тишины от каждого образца звука (простой энергетический порог).
- Вычислить аудио функции для каждого образца вашей базы данных (например, MFCC).
- Выполните перекрестную проверку процедуры классификации, чтобы сопоставить аудиофункции с категорией звука, которую вы хотите распознать.
Полезные Python Libs: scipy для чтения wav-файлов, основы для извлечения аудио функций, scikit-learn для классификации и другого машинного обучения.