Сравнение изображений - быстрый алгоритм
Я пытаюсь создать базовую таблицу изображений, а затем сравнить любые новые изображения с ней, чтобы определить, является ли новое изображение точной (или близкой) копией базы.
Например: если вы хотите сократить объем хранения одного и того же изображения в 100 раз, вы можете сохранить одну его копию и предоставить ссылки на нее. Когда вводится новое изображение, вы хотите сравнить его с существующим изображением, чтобы убедиться, что оно не является дубликатом... идеи?
Одна из моих идей заключалась в том, чтобы уменьшить размер миниатюры, а затем случайным образом выбрать 100 пикселей и сравнить их.
12 ответов
Ниже приведены три подхода к решению этой проблемы (и есть много других).
Первый - это стандартный подход в компьютерном зрении, подбор ключевых точек. Это может потребовать некоторых базовых знаний для реализации и может быть медленным.
Второй метод использует только элементарную обработку изображений и потенциально быстрее, чем первый, и его легко реализовать. Однако, что он приобретает в понятности, ему не хватает надежности - сопоставление не выполняется на масштабированных, повернутых или обесцвеченных изображениях.
Третий метод является одновременно быстрым и надежным, но его труднее всего реализовать.
Соответствие ключевых точек
Лучше, чем набрать 100 случайных очков, это собрать 100 важных очков. Некоторые части изображения содержат больше информации, чем другие (особенно по краям и углам), и именно эти вы хотите использовать для интеллектуального сопоставления изображений. Google " извлечение ключевых точек" и " сопоставление ключевых точек", и вы найдете немало научных работ по этому вопросу. В наши дни ключевые точки SIFT являются, пожалуй, самыми популярными, поскольку они могут сопоставлять изображения в различных масштабах, поворотах и освещении. Некоторые реализации SIFT можно найти здесь.
Одним из недостатков сопоставления ключевых точек является время выполнения наивной реализации: O(n^2m), где n - количество ключевых точек в каждом изображении, а m - количество изображений в базе данных. Некоторые умные алгоритмы могут находить ближайшее совпадение быстрее, например, квадродерево или разбиение двоичного пространства.
Альтернативное решение: метод гистограммы
Другое менее надежное, но потенциально более быстрое решение состоит в том, чтобы создавать гистограммы объектов для каждого изображения и выбирать изображение с гистограммой, ближайшей к гистограмме входного изображения. Я реализовал это как старшекурсник, и мы использовали 3 цветовые гистограммы (красная, зеленая и синяя) и две текстурные гистограммы, направление и масштаб. Я приведу подробности ниже, но я должен отметить, что это хорошо работает только для сопоставления изображений, ОЧЕНЬ похожих на изображения из базы данных. Повторно масштабированные, повернутые или обесцвеченные изображения могут потерпеть неудачу с этим методом, но небольшие изменения, такие как обрезка, не нарушат алгоритм
Вычислить цветовые гистограммы несложно - просто выберите диапазон для ваших групп гистограмм и для каждого диапазона подсчитайте количество пикселей с цветом в этом диапазоне. Например, рассмотрим "зеленую" гистограмму и предположим, что мы выбрали 4 сегмента для нашей гистограммы: 0-63, 64-127, 128-191 и 192-255. Затем для каждого пикселя мы смотрим на значение зеленого и добавляем подсчет в соответствующий сегмент. Когда мы закончим подсчет, мы делим каждое общее количество сегментов на количество пикселей во всем изображении, чтобы получить нормализованную гистограмму для зеленого канала.
Для гистограммы направления текстуры мы начали с определения края изображения. Каждая точка ребра имеет нормальный вектор, указывающий в направлении, перпендикулярном ребру. Мы квантовали угол вектора нормали в один из 6 сегментов между 0 и PI (поскольку ребра имеют 180-градусную симметрию, мы конвертировали углы между -PI и 0, чтобы они были между 0 и PI). После подсчета количества краевых точек в каждом направлении мы имеем ненормализованную гистограмму, представляющую направление текстуры, которую мы нормализовали путем деления каждого сегмента на общее количество краевых точек в изображении.
Чтобы вычислить гистограмму масштаба текстуры, для каждой точки края мы измерили расстояние до следующей ближайшей точки края в том же направлении. Например, если точка края A имеет направление 45 градусов, алгоритм идет в этом направлении, пока не найдет другую точку края с направлением 45 градусов (или в пределах разумного отклонения). После вычисления этого расстояния для каждой граничной точки мы помещаем эти значения в гистограмму и нормализуем ее путем деления на общее количество граничных точек.
Теперь у вас есть 5 гистограмм для каждого изображения. Чтобы сравнить два изображения, вы берете абсолютное значение разности между каждым сегментом гистограммы, а затем суммируете эти значения. Например, для сравнения изображений A и B мы бы вычислили
|A.green_histogram.bucket_1 - B.green_histogram.bucket_1|
для каждого сегмента в зеленой гистограмме, и повторите для других гистограмм, а затем суммируйте все результаты. Чем меньше результат, тем лучше матч. Повторите для всех изображений в базе данных, и победит совпадение с наименьшим результатом. Возможно, вы захотите иметь порог, выше которого алгоритм приходит к выводу, что совпадение не найдено.
Третий выбор - ключевые точки + деревья решений
Третий подход, который, вероятно, намного быстрее, чем два других, использует семантические текстовые леса (PDF). Это включает в себя извлечение простых ключевых точек и использование деревьев решений коллекции для классификации изображения. Это быстрее, чем простое сопоставление ключевых точек SIFT, поскольку позволяет избежать дорогостоящего процесса сопоставления, а ключевые точки намного проще, чем SIFT, поэтому извлечение ключевых точек происходит намного быстрее. Тем не менее, он сохраняет неизменность метода SIFT к вращению, масштабированию и освещению, что является важным свойством, отсутствующим в методе гистограммы.
Обновление:
Моя ошибка - статья Semantic Texton Forests не связана с подбором изображений, а скорее с маркировкой региона. Вот оригинальная статья, которая выполняет сопоставление: Распознавание ключевых точек с использованием рандомизированных деревьев. Кроме того, документы ниже продолжают развивать идеи и представляют современное состояние (c. 2010):
- Быстрое распознавание ключевых точек с использованием случайных папоротников - быстрее и более масштабируемо, чем Lepetit 06
-
КРАТКОЕ ОПИСАНИЕ: бинарные надежные независимые элементарные функции- менее надежные, но очень быстрые - я думаю, что цель здесь - сопоставление в реальном времени на смартфонах и других портативных устройствах
Лучший из известных мне методов - это использовать перцептуальный хэш. Кажется, есть хорошая реализация такого хэша с открытым исходным кодом, доступная по адресу:
Основная идея заключается в том, что каждое изображение сокращается до небольшого хэш-кода или "отпечатка пальца" за счет определения характерных особенностей в исходном файле изображения и хэширования компактного представления этих функций (вместо непосредственного хеширования данных изображения). Это означает, что уровень ложных срабатываний значительно уменьшается по сравнению с упрощенным подходом, таким как уменьшение изображений до изображения размером с крошечный отпечаток и сравнение отпечатков пальцев.
phash предлагает несколько типов хэшей и может использоваться для изображений, аудио или видео.
Этот пост послужил отправной точкой моего решения, здесь было много хороших идей, поэтому я хотел бы поделиться своими результатами. Основная идея заключается в том, что я нашел способ обойти медленность сопоставления изображений на основе ключевых точек, используя скорость фашинга.
Для общего решения лучше всего использовать несколько стратегий. Каждый алгоритм лучше всего подходит для определенных типов преобразований изображений, и вы можете воспользоваться этим.
Вверху самые быстрые алгоритмы; внизу самый медленный (хотя и более точный). Вы можете пропустить медленные, если хорошее совпадение будет найдено на более быстром уровне.
- основанный на хэше файла (md5,sha1 и т. д.) для точных дубликатов
- перцептивное хэширование (phash) для измененных изображений
- на основе признаков (SIFT) для измененных изображений
У меня очень хорошие результаты с phash. Точность хороша для измененных изображений. Это не подходит для (воспринимаемых) модифицированных изображений (обрезанных, повернутых, зеркальных и т. Д.). Чтобы справиться со скоростью хэширования, мы должны использовать дисковый кеш / базу данных для поддержки хэшей для стога сена.
Что действительно хорошо в phash, так это то, что когда вы создаете свою хеш-базу данных (которая для меня составляет около 1000 изображений в секунду), поиск может быть очень и очень быстрым, особенно когда вы можете хранить всю хеш-базу данных в памяти. Это довольно практично, поскольку хеш составляет всего 8 байтов.
Например, если у вас есть 1 миллион изображений, потребуется массив из 1 миллиона 64-битных значений хеш-функции (8 МБ). На некоторых процессорах это помещается в кэш L2/L3! В практическом использовании я видел сравнение corei7 со скоростью более 1 Гига-хамм / с, это только вопрос пропускной способности памяти для процессора. База данных с 1 миллиардом изображений практична на 64-битном процессоре (требуется 8 ГБ ОЗУ), а поиск не будет превышать 1 секунды!
Для модифицированных / обрезанных изображений может показаться, что инвариантный к трансформации объект / детектор ключевых точек, такой как SIFT, - это путь. SIFT будет производить хорошие ключевые точки, которые будут обнаруживать кадрирование / поворот / зеркальное отражение и т. Д. Однако сравнение дескриптора очень медленное по сравнению с расстоянием Хэмминга, используемым phash. Это серьезное ограничение. Есть много сравнений, которые нужно выполнить, так как максимальное количество дескрипторов IxJxK сравнивается с поиском одного изображения (I= количество изображений стога сена, J= целевые ключевые точки на изображение стога сена, K= целевые ключевые точки на изображение иглы).
Чтобы обойти проблему скорости, я попытался использовать phash вокруг каждой найденной ключевой точки, используя размер / радиус элемента для определения под прямоугольника. Хитрость в том, чтобы заставить это работать хорошо, состоит в том, чтобы увеличить / уменьшить радиус, чтобы генерировать различные подчиненные уровни (на изображении иглы). Обычно первый уровень (немасштабированный) будет соответствовать, однако часто требуется еще несколько. Я не уверен на 100%, почему это работает, но я могу представить, что это позволяет функциям, которые слишком малы для работы phash (phash масштабирует изображения до 32x32).
Другая проблема заключается в том, что SIFT не будет оптимально распределять ключевые точки. Если есть участок изображения с большим количеством краев, ключевые точки будут сгруппированы там, и вы не получите ничего в другой области. Я использую GridAdaptedFeatureDetector в OpenCV для улучшения распределения. Не уверен, какой размер сетки лучше, я использую маленькую сетку (1x3 или 3x1 в зависимости от ориентации изображения).
Возможно, вы захотите масштабировать все изображения стога сена (и иголки) до меньшего размера до обнаружения объектов (я использую 210px вдоль максимального размера). Это уменьшит шум на изображении (всегда проблема для алгоритмов компьютерного зрения), а также сосредоточит детектор на более заметных особенностях.
Для изображений людей вы можете попробовать распознавание лиц и использовать его, чтобы определить размер изображения для масштабирования и размер сетки (например, самое большое лицо, масштабированное до 100 пикселей). Детектор функций учитывает несколько уровней масштаба (с использованием пирамид), но существует ограничение на количество уровней, которые он будет использовать (это, конечно, настраивается).
Детектор ключевых точек, вероятно, работает лучше всего, когда он возвращает меньше, чем количество функций, которые вы хотели. Например, если вы просите 400 и получаете 300 обратно, это хорошо. Если вы получаете 400 обратно каждый раз, вероятно, некоторые хорошие функции должны были быть пропущены.
Изображение иглы может иметь меньше ключевых точек, чем изображения стога сена, и при этом получать хорошие результаты. Добавление большего количества данных не обязательно принесет вам огромный выигрыш, например, при J=400 и K=40 мой коэффициент попадания составляет около 92%. При J=400 и K=400 частота попаданий увеличивается только до 96%.
Мы можем использовать предельную скорость функции Хэмминга для решения задач масштабирования, вращения, зеркального отображения и т. Д. Можно использовать многоходовую технику. На каждой итерации преобразуйте вложенные прямоугольники, перефразируйте и снова запустите функцию поиска.
В мою компанию ежемесячно поступает около 24 миллионов изображений от производителей. Я искал быстрое решение, чтобы изображения, которые мы загружаем в наш каталог, были новыми.
Я хочу сказать, что я искал в интернете повсюду, чтобы попытаться найти идеальное решение. Я даже разработал свой собственный алгоритм обнаружения краев.
Я оценил скорость и точность нескольких моделей. Мои изображения с белым фоном очень хорошо работают с фишингом. Как сказал redcalx, я рекомендую phash или ahash. НЕ используйте хеширование MD5 или другие криптографические хеши. Если только вам не нужны ТОЧНЫЕ совпадения изображений. Любое изменение размера или манипуляция между изображениями приведет к другому хешу.
Для phash/ahash, проверьте это: imagehash
Я хотел расширить пост *redcalx *, опубликовав свой код и мою точность.
Что я делаю:
from PIL import Image
from PIL import ImageFilter
import imagehash
img1=Image.open(r"C:\yourlocation")
img2=Image.open(r"C:\yourlocation")
if img1.width<img2.width:
img2=img2.resize((img1.width,img1.height))
else:
img1=img1.resize((img2.width,img2.height))
img1=img1.filter(ImageFilter.BoxBlur(radius=3))
img2=img2.filter(ImageFilter.BoxBlur(radius=3))
phashvalue=imagehash.phash(img1)-imagehash.phash(img2)
ahashvalue=imagehash.average_hash(img1)-imagehash.average_hash(img2)
totalaccuracy=phashvalue+ahashvalue
Вот некоторые из моих результатов:
item1 item2 totalaccuracy
desk1 desk2 3
desk2 phone1 22
chair1 desk1 17
phone1 chair1 34
где элемент представляет фактический предмет изображения, а число представляет масштаб ориентации.
Надеюсь это поможет!
Как указал Картман, вы можете использовать любой тип хеш-значения для поиска точных дубликатов.
Одна отправная точка для поиска близких изображений может быть здесь. Это инструмент, используемый компаниями компьютерной графики для проверки того, что обновленные изображения все еще показывают ту же сцену.
У меня есть идея, которая может работать, и она, скорее всего, будет очень быстрой. Вы можете выполнить выборку изображения с разрешением 80x60 или сравнимым с ним и преобразовать его в шкалу серого (после дополнительной выборки это будет быстрее). Обработайте оба изображения, которые вы хотите сравнить. Затем запустите нормализованную сумму квадратов разностей между двумя изображениями (изображение запроса и каждое из БД) или, что еще лучше, нормализованную перекрестную корреляцию, которая дает ответ ближе к 1, если оба изображения похожи. Затем, если изображения похожи, вы можете перейти к более сложным методам, чтобы убедиться, что это те же изображения. Очевидно, что этот алгоритм является линейным с точки зрения количества изображений в вашей базе данных, поэтому, несмотря на то, что он будет очень быстрым - до 10000 изображений в секунду на современном оборудовании. Если вам нужна инвариантность к вращению, то для этого небольшого изображения можно вычислить доминирующий градиент, а затем всю систему координат можно повернуть в каноническую ориентацию, хотя это будет медленнее. И нет, здесь нет неизменности для масштабирования.
Если вы хотите что-то более общее или использовать большие базы данных (миллион изображений), то вам нужно взглянуть на теорию извлечения изображений (за последние 5 лет появилось множество статей). В других ответах есть несколько указателей. Но это может быть излишним, и предложенный гистограммный подход сделает эту работу. Хотя я думаю, что сочетание множества разных быстрых подходов будет еще лучше.
Я считаю, что уменьшение размера изображения до размера почти иконки, скажем, 48x48, затем преобразование в оттенки серого, а затем с учетом разницы между пикселями или Delta, должно работать хорошо. Поскольку мы сравниваем изменение цвета пикселя, а не фактический цвет пикселя, не имеет значения, будет ли изображение немного светлее или темнее. Значительные изменения будут иметь значение, поскольку пиксели, становящиеся слишком светлыми / темными, будут потеряны. Вы можете применить это к одному ряду или к любым другим, чтобы повысить точность. Самое большее, вы должны сделать 47x47=2,209 вычитаний, чтобы сформировать сопоставимый ключ.
То, что мы вольно называем дубликатами, может быть трудно распознать алгоритмам. Ваши дубликаты могут быть:
- Точные дубликаты
- Почти точные дубликаты. (мелкие правки изображения и т. д.)
- Дубликаты восприятия (тот же контент, но другой вид, камера и т. д.)
№1 и 2 решить проще. № 3. очень субъективен и все еще является предметом исследования. Я могу предложить решение для №1 и 2. Оба решения используют отличную библиотеку хеширования изображений: https://github.com/JohannesBuchner/imagehash
- Точные дубликаты Точные дубликаты можно найти с помощью перцепционной меры хеширования. Библиотека phash неплохо справляется с этим. Я регулярно использую его для очистки данных обучения. Использование (с сайта github) очень простое:
from PIL import Image
import imagehash
# image_fns : List of training image files
img_hashes = {}
for img_fn in sorted(image_fns):
hash = imagehash.average_hash(Image.open(image_fn))
if hash in img_hashes:
print( '{} duplicate of {}'.format(image_fn, img_hashes[hash]) )
else:
img_hashes[hash] = image_fn
- Почти точные дубликаты В этом случае вам нужно будет установить порог и сравнить значения хеш-функции на их расстоянии друг от друга. Это должно быть сделано методом проб и ошибок для содержания вашего изображения.
from PIL import Image
import imagehash
# image_fns : List of training image files
img_hashes = {}
epsilon = 50
for img_fn1, img_fn2 in zip(image_fns, image_fns[::-1]):
if image_fn1 == image_fn2:
continue
hash1 = imagehash.average_hash(Image.open(image_fn1))
hash2 = imagehash.average_hash(Image.open(image_fn2))
if hash1 - hash2 < epsilon:
print( '{} is near duplicate of {}'.format(image_fn1, image_fn2) )
Выбор 100 случайных точек может означать, что похожие (или иногда даже разнородные) изображения будут помечены как одинаковые, что, я полагаю, не то, что вам нужно. Хеши MD5 не будут работать, если изображения были разных форматов (png, jpeg и т. Д.), Имели разные размеры или имели разные метаданные. Хорошим выбором будет уменьшение всех изображений до меньшего размера, сравнение по пикселям не должно занимать слишком много времени, если вы используете хорошую библиотеку изображений / быстрый язык, а размер достаточно мал.
Вы можете попробовать сделать их крошечными, тогда, если они одинаковые, проведите другое сравнение с большим размером - может быть хорошим сочетанием скорости и точности...
Если у вас есть большое количество изображений, посмотрите на фильтр Блума, который использует несколько хешей для вероятностного, но эффективного результата. Если количество изображений невелико, то достаточно криптографического хэша, такого как md5.
Я думаю, что стоит добавить к этому созданное мной phash-решение, которое мы используем уже некоторое время: Image::PHash. Это модуль Perl, но основные части написаны на C. Он в несколько раз быстрее, чем phash.org, и имеет несколько дополнительных функций для фазирования на основе DCT.
У нас были десятки миллионов изображений, уже проиндексированных в базе данных MySQL, поэтому мне нужно было что-то быстрое, а также способ использовать индексы MySQL (которые не работают с расстоянием Хэмминга), что привело меня к использованию «уменьшенных» хэшей для прямых совпадений. , документ модуля обсуждает это.
Это довольно просто использовать:
use Image::PHash;
my $iph1 = Image::PHash->new('file1.jpg');
my $p1 = $iph1->pHash();
my $iph2 = Image::PHash->new('file2.jpg');
my $p2 = $iph2->pHash();
my $diff = Image::PHash::diff($p1, $p2);
Я сделал очень простое решение на PHP для сравнения изображений несколько лет назад. Он вычисляет простой хэш для каждого изображения, а затем находит разницу. Это очень хорошо работает для обрезанных или обрезанных с переводом версий одного и того же изображения.
Сначала я уменьшаю размер изображения, например, 24x24 или 36x36. Затем я беру каждый столбец пикселей и нахожу средние значения R, G, B для этого столбца.
После того, как у каждого столбца есть свои три числа, я делаю два прохода: первый по нечетным столбцам, второй по четным. Первый проход суммирует все обработанные столбцы, а затем делит на их количество ([1] + [2] + [5] + [N-1] / (N/2)). Второй проход работает по-другому :([3] - [4] + [6] - [8] ... / (N/2)).
Итак, теперь у меня есть два номера. Как я выяснил в ходе экспериментов, первое из них является основным: если оно далеко от значений другого изображения, то с человеческой точки зрения они вообще не похожи.
Итак, первый представляет собой среднюю яркость изображения (опять же, вы можете уделять больше внимания зеленому каналу, затем красному и т. д., но порядок по умолчанию R->G->B работает нормально). Второе число можно сравнить, если первые два очень близки, и оно фактически представляет собой общий контраст изображения: если у нас есть какой-то черно-белый узор или какая-либо контрастная сцена (например, освещенные здания в городе ночью) и если нам повезет, мы получим здесь огромные числа, если наши положительные члены суммы в основном будут светлыми, а отрицательные — в основном темными, или наоборот. Поскольку я хочу, чтобы мои значения всегда были положительными, я делю на 2 и сдвигаю на 127 здесь.
Я написал код на PHP в 2017 году и, похоже, потерял код. Но у меня все еще есть скриншоты:
То же изображение: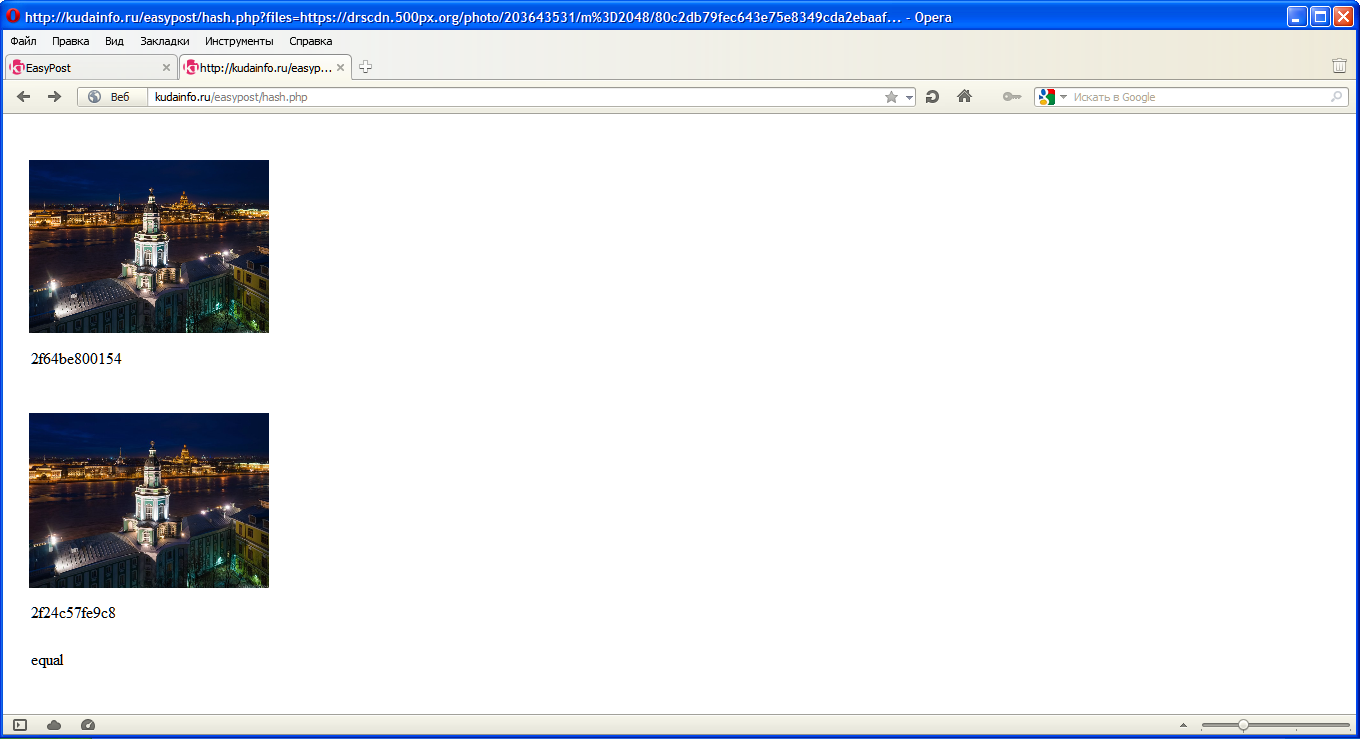
Черно-белая версия:
Обрезанная версия: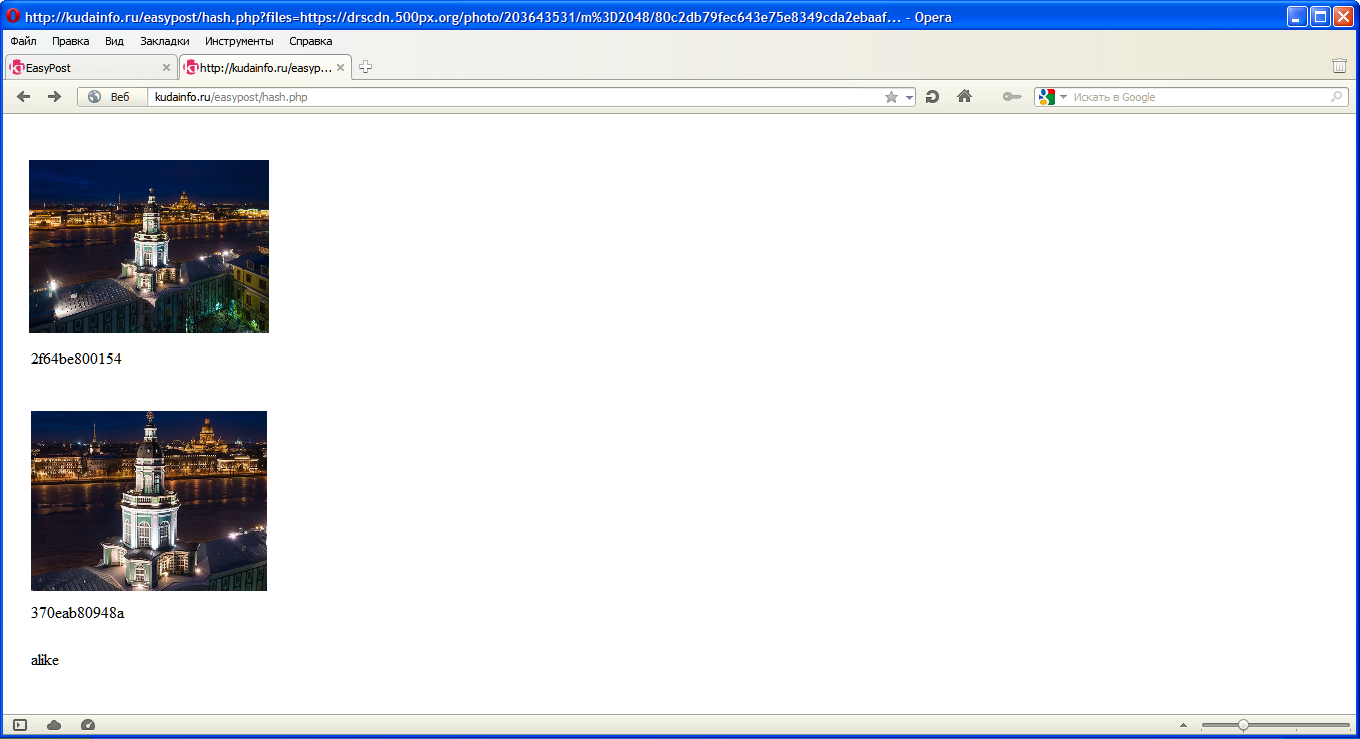
Другое изображение, переведенная версия: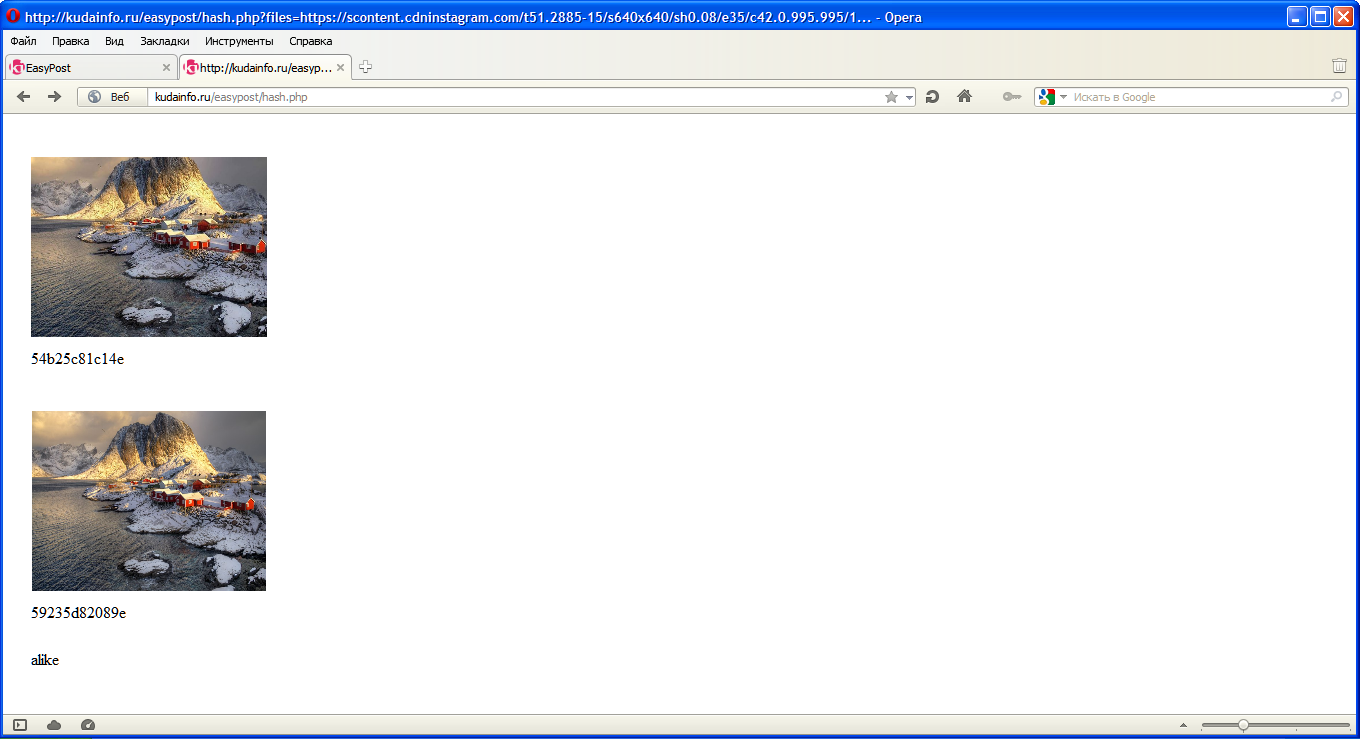
Та же цветовая гамма, что и у 4-го, но другая сцена: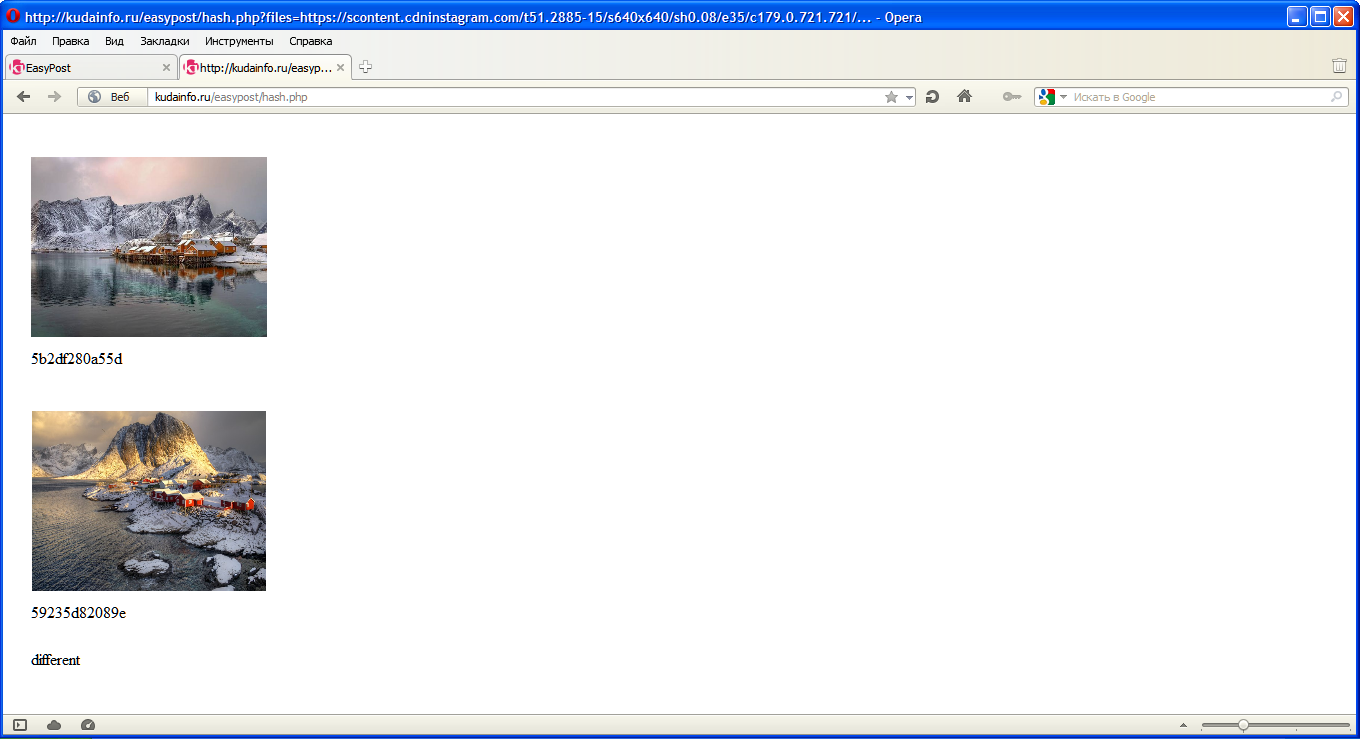
Я настроил пороги разности так, чтобы результаты были действительно хорошими. Но, как видите, этот простой алгоритм не может сделать ничего хорошего с простыми переводами сцен.
На заметку могу заметить, что модификация может быть написана, чтобы делать обрезанные копии с каждого из двух изображений на 75-80 процентов, 4 по углам или 8 по углам и серединам краев, а потом путем сравнения обрезанных вариантов точно так же с другим целым изображением; и если один из них получает значительно лучшую оценку сходства, то использовать его значение вместо значения по умолчанию).