Как получить P и R матрицы для марковского процесса принятия решений в мире сетки?
Возьмите пример канонического мира сетки 3х4 ниже. Как бы выглядели матрицы P и R для этой проблемы? Я знаю, что P будет AxSxS, а R будет AxS, но у меня много проблем с размышлениями о том, как именно это работает.
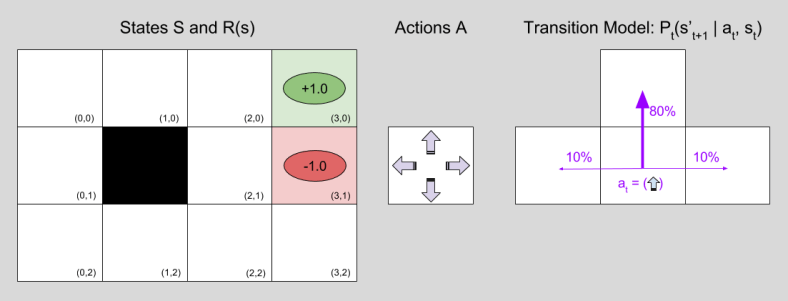
P должно быть 4 матрицы 12x12, если я не ошибаюсь, по одному на каждое действие (вверх, вниз, влево, вправо). R должен быть матрицей 4x12, но я не совсем уверен, почему... разве нет только 12 возможных ячеек, за которые есть награда?
Я пробовал множество разных значений, пытаясь выяснить это с помощью MDPToolbox, но я продолжаю сталкиваться с исключениями или математическими ошибками, поэтому я явно чего-то не понимаю.
Вот пример кода:
# P = 4 12x12 matrices where each row's sum is 1.0
# R = 4x12 matrix where one cell has a reward of 1.0 and one a reward of -1.0
pi = mdptoolbox.PolicyIteration(P ,R, 0.9)
pi.run()
print(pi.policy)
Это дает мне математическую ошибку домена, поэтому что-то не так.
Как именно должны выглядеть матрицы P и R для этой проблемы мира сетки?
ПРИМЕЧАНИЕ: я опубликовал это в Cross Validated, но не получил ответа - думал, что это может быть лучший форум, но не уверен, как на самом деле перенести вопрос.