Лучший способ конвертировать текстовые файлы между наборами символов?
Какой самый быстрый и простой инструмент или метод для преобразования текстовых файлов между наборами символов?
В частности, мне нужно конвертировать из UTF-8 в ISO-8859-15 и наоборот.
Все идет: одна строка на вашем любимом языке сценариев, инструменты командной строки или другие утилиты для ОС, веб-сайтов и т. Д.
Лучшие решения на данный момент:
В Linux / UNIX / OS X / cygwin:
Gnu iconv, предложенный Troels Arvin, лучше всего использовать в качестве фильтра. Кажется, это универсально доступно. Пример:
$ iconv -f UTF-8 -t ISO-8859-15 in.txt > out.txtКак отметил Бен, есть онлайн-конвертер, использующий iconv.
Реконструкция Gnu ( руководство), предложенная Cheekysoft, преобразует один или несколько файлов на месте. Пример:
$ recode UTF8..ISO-8859-15 in.txtЭтот использует более короткие псевдонимы:
$ recode utf8..l9 in.txtRecode также поддерживает поверхности, которые можно использовать для преобразования между различными типами окончания строки и кодированием:
Преобразовать переводы строк из LF (Unix) в CR-LF (DOS):
$ recode ../CR-LF in.txtФайл кодирования Base64:
$ recode ../Base64 in.txtВы также можете комбинировать их.
Преобразуйте файл UTF8 в кодировке Base64 с окончаниями строк Unix в файл Latin 1 в кодировке Base64 с окончаниями строк Dos:
$ recode utf8/Base64..l1/CR-LF/Base64 file.txt
В Windows с Powershell ( Джей Базузи):
PS C:\> gc -en utf8 in.txt | Out-File -en ascii out.txt(Однако поддержка ISO-8859-15 не поддерживается; в нем говорится, что поддерживаются кодировки unicode, utf7, utf8, utf32, ascii, bigendianunicode, default и oem.)
редактировать
Вы имеете в виду поддержку iso-8859-1? Использование "String" делает это, например, для наоборот
gc -en string in.txt | Out-File -en utf8 out.txt
Примечание. Возможные значения перечисления: "Неизвестно, Строка, Юникод, Байт, BigEndianUnicode, UTF8, UTF7, Ascii".
- CsCvt - Конвертер наборов символов Kalytta - еще один замечательный инструмент для Windows, основанный на командной строке
23 ответа
Автономный сервисный подход
iconv -f ISO-8859-1 -t UTF-8 in.txt > out.txt
-f ENCODING the encoding of the input
-t ENCODING the encoding of the output
Вам не нужно указывать ни один из этих аргументов. По умолчанию они будут соответствовать вашей текущей локали (обычно это UTF-8).
Попробуйте VIM
Если у вас есть vim Вы можете использовать это:
Не проверено для каждой кодировки.
Самое интересное в этом то, что вам не нужно знать кодировку источника
vim +"set nobomb | set fenc=utf8 | x" filename.txt
Имейте в виду, что эта команда изменяет непосредственно файл
Пояснительная часть!
+: Используется vim для непосредственного ввода команды при открытии файла. Обычно используется для открытия файла в определенной строке:vim +14 file.txt|: Разделитель нескольких команд (например,;в баш)set nobomb: нет utf-8 спецификацияset fenc=utf8: Установить новую кодировку для ссылки на документацию utf-8x: Сохранить и закрыть файлfilename.txt: путь к файлу": цитаты здесь из-за труб. (иначе bash будет использовать их как трубу bash)
В Linux вы можете использовать очень мощную команду recode, чтобы попытаться преобразовать различные кодировки, а также любые проблемы с окончанием строки. recode -l покажет вам все форматы и кодировки, между которыми инструмент может конвертироваться. Вероятно, это будет ОЧЕНЬ длинный список.
Get-Content -Encoding UTF8 FILE-UTF8.TXT | Out-File -Encoding UTF7 FILE-UTF7.TXT
Кратчайшая версия, если вы можете предположить, что входная спецификация верна:
gc FILE.TXT | Out-File -en utf7 file-utf7.txt
iconv -f FROM-ENCODING -t TO-ENCODING file.txt
Также есть инструменты на основе iconv на многих языках.
Попробуйте функцию iconv Bash
Я положил это в .bashrc:
utf8()
{
iconv -f ISO-8859-1 -t UTF-8 $1 > $1.tmp
rm $1
mv $1.tmp $1
}
... чтобы иметь возможность конвертировать файлы так:
utf8 MyClass.java
Попробуйте Notepad++
В Windows я смог использовать Notepad++ для преобразования из ISO-8859-1 в UTF-8. Нажмите "Encoding" а потом "Convert to UTF-8",
Oneliner с использованием find, с автоматическим обнаружением
Кодировка символов всех соответствующих текстовых файлов определяется автоматически, и все соответствующие текстовые файлы преобразуются в utf-8 кодирование:
$ find . -type f -iname *.txt -exec sh -c 'iconv -f $(file -bi "$1" |sed -e "s/.*[ ]charset=//") -t utf-8 -o converted "$1" && mv converted "$1"' -- {} \;
Чтобы выполнить эти шаги, вложенная оболочка sh используется с -execработает на одну строчку с -c флаг и передача имени файла в качестве позиционного аргумента "$1" с -- {}, Между utf-8 выходной файл временно назван converted,
согласно которому file -biсредства:
-б, кратко
Не добавляйте имена файлов в выходные строки (краткий режим).-i, --mime
Заставляет команду file выводить строки типа mime, а не более традиционные для человека. Таким образом, он может сказать "текст / обычный; charset=us-ascii ', а не “ASCII text”.
findКоманда очень полезна для такой автоматизации управления файлами.
Нажмите здесь для болееfind в изобилии.
Предполагая, что вы не знаете кодировку ввода и все же хотите автоматизировать большую часть преобразования, я завершил этот лайнер, суммируя предыдущие ответы.
iconv -f $(chardetect input.text | awk '{print $2}') -t utf-8 -o output.text
DOS/Windows: используйте кодовую страницу
chcp 65001>NUL
type ascii.txt > unicode.txt
команда chcp может быть использован для изменения кодовой страницы. Кодовая страница 65001 является именем Microsoft для UTF-8. После установки кодовой страницы выходные данные, генерируемые следующими командами, будут иметь установленную кодовую страницу.
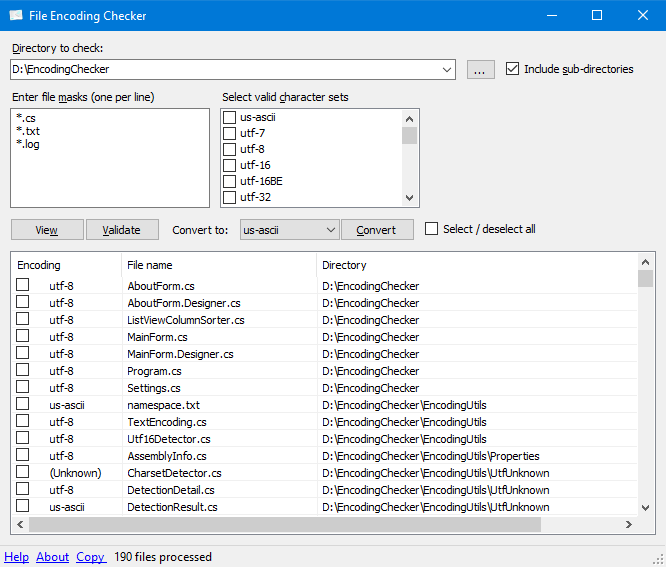
Попробуйте EncodingChecker
Средство проверки кодировки файлов - это инструмент с графическим пользовательским интерфейсом, который позволяет вам проверять кодировку текста одного или нескольких файлов. Инструмент может отображать кодировку для всех выбранных файлов или только тех файлов, которые не имеют указанных вами кодировок.
Для работы средства проверки кодировки файлов требуется.NET 4 или более поздняя версия.
Для обнаружения кодировки средство проверки кодировки файлов использует библиотеку UtfUnknown Charset Detector. Текстовые файлы UTF-16 без метки порядка следования байтов (BOM) могут быть обнаружены эвристикой.
Код Visual Studio
- Откройте файл в Visual Studio Code
- Повторно открыть с кодировкой : в нижней строке состояния справа вы должны увидеть текущую кодировку файла (например, «UTF-8»). Нажмите на это и выберите «Повторно открыть с кодировкой».
- Выберите правильную кодировку файла (например, ISO 8859-2).
- Убедитесь , что ваш контент отображается должным образом.
- Сохранить с кодировкой : теперь в нижней строке состояния должен отображаться новый формат кодировки (например, ISO 8859-2). Нажмите на это и выберите «Сохранить с кодировкой» и выберите UTF-8 (или любую новую кодировку, которую вы хотите).
ПРИМЕЧАНИЕ. ЭТО ЗАМЕНИТ ВАШ ИСХОДНЫЙ ФАЙЛ. СДЕЛАЙТЕ РЕЗЕРВНУЮ КОПИИ ПЕРВЫМ.
Просто измените кодировку загруженного файла в IDE IntelliJ, справа от строки состояния (внизу), где указана текущая кодировка. Он предлагает перезагрузить или конвертировать, использовать конвертировать. Убедитесь, что вы сделали резервную копию оригинального файла заранее.
Используйте этот скрипт Python: https://github.com/goerz/convert_encoding.py Работает на любой платформе. Требуется Python 2.7.
Редактор Yudit поддерживает и конвертирует различные текстовые кодировки, работает в Linux, Windows, Mac и т. Д.
-Адам
В PowerShell:
function Recode($InCharset, $InFile, $OutCharset, $OutFile) {
# Read input file in the source encoding
$Encoding = [System.Text.Encoding]::GetEncoding($InCharset)
$Text = [System.IO.File]::ReadAllText($InFile, $Encoding)
# Write output file in the destination encoding
$Encoding = [System.Text.Encoding]::GetEncoding($OutCharset)
[System.IO.File]::WriteAllText($OutFile, $Text, $Encoding)
}
Recode Windows-1252 "$pwd\in.txt" utf8 "$pwd\out.txt"
Для списка поддерживаемых имен кодировок:
https://docs.microsoft.com/en-us/dotnet/api/system.text.encoding
Чтобы написать файл свойств (Java) обычно я использую это в Linux (дистрибутивы Mint и Ubuntu):
$ native2ascii filename.properties
Например:
$ cat test.properties
first=Execução número um
second=Execução número dois
$ native2ascii test.properties
first=Execu\u00e7\u00e3o n\u00famero um
second=Execu\u00e7\u00e3o n\u00famero dois
PS: Я написал исполнение номер один / два на португальском языке, чтобы заставить специальные символы.
В моем случае при первом исполнении я получил это сообщение:
$ native2ascii teste.txt
The program 'native2ascii' can be found in the following packages:
* gcj-5-jdk
* openjdk-8-jdk-headless
* gcj-4.8-jdk
* gcj-4.9-jdk
Try: sudo apt install <selected package>
Когда я установил первый вариант (gcj-5-jdk), проблема была закончена.
Я надеюсь, что это поможет кому-то.
Также существует веб-инструмент для преобразования кодировки файлов: https://webtool.cloud/change-file-encoding
Он поддерживает широкий спектр кодировок, в том числе некоторые редкие, такие как кодовая страница IBM 37.
С рубином:
ruby -e "File.write('output.txt', File.read('input.txt').encode('UTF-8', 'binary', invalid: :replace, undef: :replace, replace: ''))"
Источник: https://robots.thoughtbot.com/fight-back-utf-8-invalid-byte-sequences
Мой любимый инструмент для этого - Jedit (текстовый редактор на основе Java), который имеет две очень удобные функции:
- Тот, который позволяет пользователю перезагрузить текст с другой кодировкой (и, таким образом, визуально контролировать результат)
- Еще один, который позволяет пользователю явно выбирать кодировку (и конец строки) перед сохранением
Если приложения с графическим интерфейсом пользователя macOS - это ваш хлеб с маслом, SubEthaEdit - это текстовый редактор, к которому я обычно обращаюсь для борьбы с кодированием - его "предварительный просмотр преобразования" позволяет вам видеть все недопустимые символы в выходной кодировке и исправлять / удалять их.
И теперь он с открытым исходным кодом, так что ура им.
Как описано в разделе Как исправить кодировку символов в файле? Synalyze It! позволяет легко конвертировать в OS X все кодировки, поддерживаемые библиотекой ICU.
Кроме того, вы можете отобразить несколько байтов файла, переведенного в Unicode из всех кодировок, чтобы быстро увидеть, какой из них подходит для вашего файла.