Сохранить / получить структуру данных
Я реализовал дерево суффиксов в Python для полнотекстового поиска, и оно работает очень хорошо. Но есть проблема: индексированный текст может быть очень большим, поэтому мы не сможем иметь всю структуру в оперативной памяти.
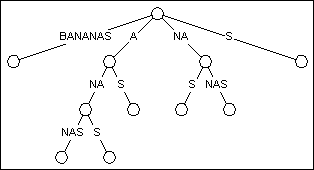
ИЗОБРАЖЕНИЕ: Суффикс дерева для слова BANANAS (в моем сценарии представьте дерево в 100000 раз больше).
Итак, изучив немного об этом, я нашел pickle модуль, отличный модуль Python для "загрузки" и "выгрузки" объектов из / в файлы, и знаете что? Это прекрасно работает с моей структурой данных.
Итак, короче говоря: какова будет лучшая стратегия для хранения и извлечения этой структуры на / с диска? Я имею в виду, что решением может быть сохранение каждого узла в файле и загрузка его с диска всякий раз, когда это необходимо, но это не лучший вариант (слишком много обращений к диску).
Сноска. Несмотря на то, что я пометил этот вопрос как python, язык программирования не является важной частью вопроса, стратегия хранения / извлечения диска на самом деле является основным пунктом.
5 ответов
Если pickle уже работает для вас, вы можете взглянуть на ZODB, который добавляет некоторые функции поверх pickle, Просматривая документацию, я увидел этот абзац, который рассматривает проблемы размера, которые у вас есть:
База данных свободно перемещает объекты между памятью и хранилищем. Если объект некоторое время не использовался, он может быть освобожден, а его содержимое загружено из хранилища при следующем использовании.
Эффективный способ управления структурой, подобной этой, заключается в использовании файла с отображением в памяти. В файле вместо хранения ссылок на указатели узлов вы сохраняете смещения в файле. Вы все еще можете использоватьpickleсериализовать данные узла в поток, подходящий для хранения на диске, но вы захотите избежать хранения ссылок, так какpickleМодуль захочет внедрить все дерево целиком (как вы видели).
С использованиемmmap модуль, вы можете отобразить файл в адресное пространство и прочитать его, как огромную последовательность байтов. ОС заботится о фактическом чтении из файла и управлении файловыми буферами и всеми деталями.
Вы можете сохранить первый узел в начале файла и иметь смещения, которые указывают на следующий узел (ы). Чтение следующего узла - это всего лишь чтение правильного смещения в файле.
Преимущество отображаемых в память файлов заключается в том, что они не загружаются в память сразу, а только читаются с диска при необходимости. Я сделал это (на 64-битной ОС) с файлом 30 ГБ на компьютере, на котором установлено только 4 ГБ ОЗУ, и он работал нормально.
Вместо этого попробуйте сжатое суффиксное дерево.
Основная идея заключается в том, что вместо множества узлов по 1 символу вы можете сжать их в 1 узел из нескольких символов, что позволит сэкономить дополнительные узлы.
Эта ссылка здесь ( http://www.cs.sunysb.edu/~algorith/implement/suds/implement.shtml) говорит, что вы можете преобразовать дерево суффиксов 160 МБ в дерево суффиксов сжатых 33 МБ. Довольно выигрыш.
Эти сжатые деревья используются для сопоставления генетических подстрок на огромных строках. Раньше у меня не хватало памяти с деревом суффиксов, но после того, как я сжал его, ошибка нехватки памяти исчезла.
Хотел бы я найти неоплачиваемую статью, которая лучше объясняет реализацию. ( http://dl.acm.org/citation.cfm?id=1768593)
Может быть, вы могли бы объединить cPickle и bsddb база данных, которая позволит вам хранить ваши засоленные узлы в похожем на словарь объекте, который будет храниться в файловой системе; таким образом, вы можете загрузить базу данных позже и получить нужные вам узлы с действительно хорошими показателями.
Очень простым способом:
import bsddb
import cPickle
db = bsddb.btopen('/tmp/nodes.db', 'c')
def store_node(node, key, db):
db[key] = cPickle.dumps(node)
def get_node(key, db):
return cPickle.loads(db[key])
Как насчет хранения его в sqlite?
SQLite:
- имеет поддержку до 2 терабайт данных,
- поддерживает запросы SQL,
- отличная замена для хранения данных в приложении,
- может поддерживать ~100 тыс. посещений в день (если используется для обычного веб-приложения),
Поэтому может быть целесообразно более внимательно посмотреть на это решение, поскольку оно оказалось эффективным способом хранения данных в приложениях.