Конкретный выбор дубликатов в MySQL
Я заглянул внутрь и наружу SO и до сих пор не знаю, можно ли это сделать. У меня есть таблица, которая выглядит так:
User ID | Role | First Name | Last Name | Email |<br>
0001 | K | John | Smith | e@e.co|<br>
0002 | Q | Jane | Dickens | q@q.co|<br>
0003 | K | John | Smith | e@e.co|<br>
0004 | J | Jack | Paper | j@j.co|<br>
Как видите, таблица содержит дубликат, поскольку пользователь вводит свои данные два раза. Я хочу отобразить строки, которые
Я могу заставить первые три условия работать с внутренним подзапросом соединения, но я получаю 0 возвращенных результатов, когда пытаюсь добавить четвертое условие.
Заранее спасибо за помощь!
6 ответов
SELECT GROUP_CONCAT(`User ID`) as IDs, Role, `First Name`, `Last Name`, Email
FROM users_table
GROUP BY Role,`First Name`,`Last Name`,Email
Даст стол вроде
IDs | Role | First Name | Last Name | Email |
0001,0003 | K | John | Smith | e@e.co|
0002 | Q | Jane | Dickens | q@q.co|
0004 | J | Jack | Paper | j@j.co|
Хитрость заключается в GROUP BY все кроме ID ,
Вы также можете сделать:
SELECT COUNT(`User ID`) as numIDs, GROUP_CONCAT(`User ID`) as IDs,
Role, `First Name`, `Last Name`, Email
FROM users_table
GROUP BY Role,`First Name`,`Last Name`,Email
HAVING numIDs > 1
получить
numIDs |IDs | Role | First Name | Last Name | Email |
2 |0001,0003 | K | John | Smith | e@e.co|
В любом случае, вы понимаете, как изменить это в соответствии с вашими целями.
Я думаю, что вы хотите удалить дубликаты строк. Считайте только по группам и удаляйте дублирующиеся строки.
select * from tb_users
group by first_name, last_name, email
having count(*) > 1
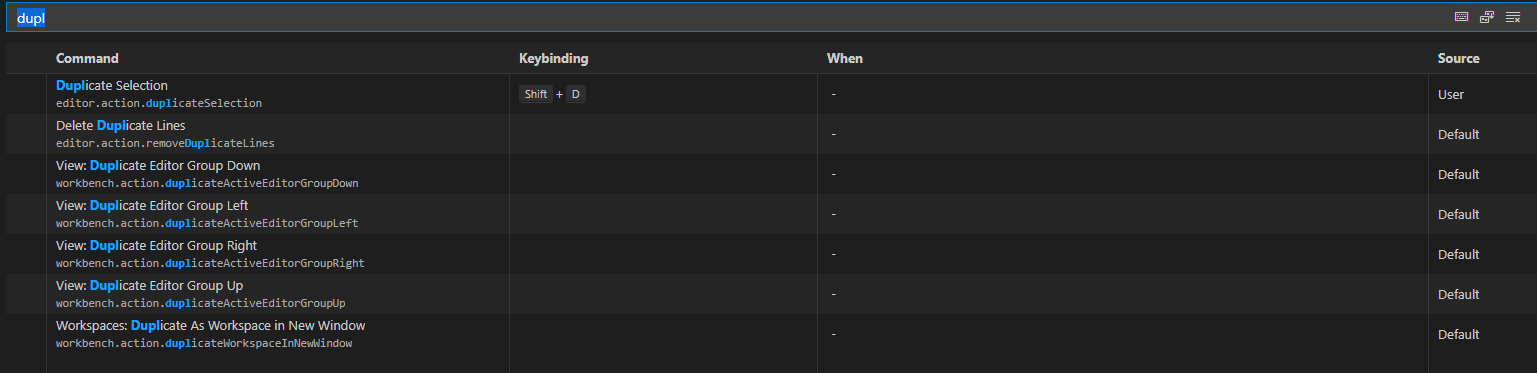
Вам не нужно скачивать расширения; перейдите в левый нижний угол, нажмите «Настройки», нажмите «Сочетания клавиш» и найдите «дублирование». Вы должны увидеть, как показано на изображении ниже, и назначить нужную комбинацию клавиш. Я выбираю Shift+D, потому что не хочу потерять текущее поведение Ctrl+D, это тоже очень полезно.
Попробуйте что-то вроде:
select *
from tb_users
where (first_name, last_name, email) in
(select first_name, last_name, email
from tb_users
group by first_name, last_name, email
having count(*) > 1)
Я предполагаю, что ваша таблица не содержит истинных повторяющихся строк (где также совпадает идентификатор пользователя). Я думаю, что это должно быть так же просто, как вернуть соответствующие строки (с моей скорректированной схемой именования столбцов и таблиц):
SELECT ui.user_id, ui.role, ui.first_name, ui.last_name, ui.email
FROM user_info AS ui
INNER JOIN user_info AS udi
ON ui.first_name = udi.first_name
AND ui.last_name = udi.last_name
AND ui.email = udi.email
AND ui.user_id != udi.user_id;
Я бы использовал count(*) и group by.
Как этот счетчик SELECT (*) как count ОТ группы таблиц по concat(firstname,'\n',last_name), имеющему count=1;