Два выбора или один выбор + одно объединение в SQL?
Следующие фрагменты кода должны выполнять ту же работу.
SELECT t1.* FROM table1 t1
INNER JOIN table2 t2
ON t1.ID = t2.IDService
WHERE t2.Code = @code
а также
SELECT * FROM table1 t1
WHERE t1.ID IN (SELECT IDService FROM table2 WHERE Code = @code)
Какое из них является лучшим решением, в целом? И в вычислительном отношении, лучше иметь два вложенных выбора или лучше использовать внутреннее соединение?
РЕДАКТИРОВАТЬ: Учтите, что PK таблицы 1 ID и PK таблицы 2 идентифицируют пару (IDService,Code). Итак, исправляя код (используя WHERE пункт) и применение пункта ON IDService, я могу предположить, что результат каждого выбора одинаковы.
2 ответа
Ваше мнение о том, что они должны выполнять одну и ту же работу, не соответствует действительности. Представьте себе этот тестовый набор данных:
T1
ID
----
1
2
3
4
5
T2
ID
---
1
1
1
2
2
3
DDL
CREATE TABLE dbo.T1 (ID INT NOT NULL);
INSERT dbo.T1 (ID) VALUES (1), (2), (3), (4), (5);
CREATE TABLE dbo.T2 (ID INT NOT NULL);
INSERT dbo.T2 (ID) VALUES (1), (1), (1), (2), (2), (3);
SELECT *
FROM dbo.T1
WHERE T1.ID IN (SELECT T2.ID FROM dbo.T2);
SELECT T1.*
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.ID = T2.ID;
Результаты
ID
---
1
2
3
ID
---
1
1
1
2
2
3
Ваши результаты совпадают, только если столбец, в котором вы ищете, уникален.
CREATE TABLE dbo.T1 (ID INT NOT NULL);
INSERT dbo.T1 (ID) VALUES (1), (2), (3), (4), (5);
CREATE TABLE dbo.T2 (ID INT NOT NULL);
INSERT dbo.T2 (ID) VALUES (1), (2), (3);
SELECT *
FROM dbo.T1
WHERE T1.ID IN (SELECT T2.ID FROM dbo.T2);
SELECT T1.*
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.ID = T2.ID;
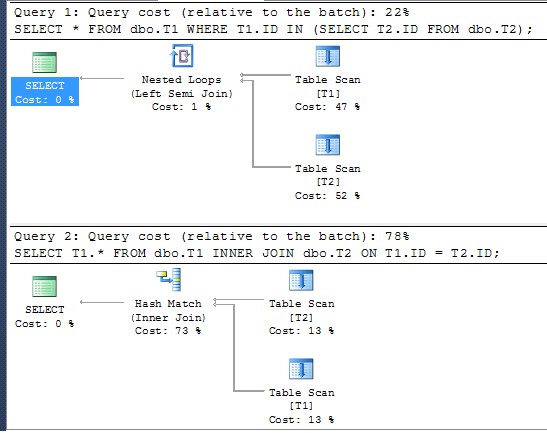
Несмотря на то, что результаты совпадают, план выполнения не так. Первый запрос с использованием IN может использовать объединение anti-semi, что означает, что он знает, что данные в t2 не нужны, поэтому, как только он находит одно совпадение, он может прекратить сканирование для дальнейших совпадений.
Если вы ограничите свою вторую таблицу только уникальными значениями, то увидите тот же план:
CREATE TABLE dbo.T1 (ID INT NOT NULL PRIMARY KEY);
INSERT dbo.T1 (ID) VALUES (1), (2), (3), (4), (5);
CREATE TABLE dbo.T2 (ID INT NOT NULL PRIMARY KEY);
INSERT dbo.T2 (ID) VALUES (1), (2), (3);
SELECT *
FROM dbo.T1
WHERE T1.ID IN (SELECT T2.ID FROM dbo.T2);
SELECT T1.*
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.ID = T2.ID;
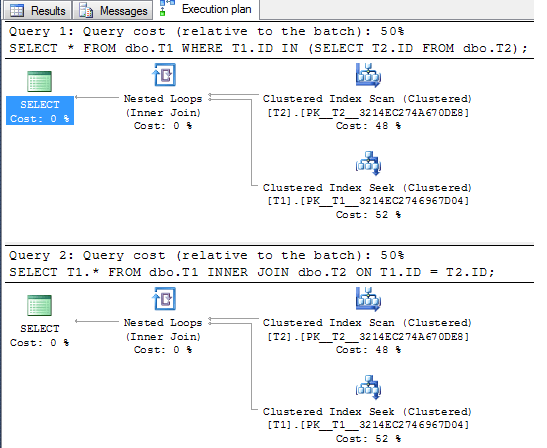
Таким образом, два запроса не всегда будут давать одинаковые результаты, и они не всегда будут иметь один и тот же план. Это действительно зависит от ваших индексов и ширины ваших данных / запросов.
Как очень общее правило, JOIN почти всегда работает лучше, чем SUB-QUERY, есть исключения.
Если вы хотите использовать подзапрос, предложение EXIST, как правило, работает лучше, чем IN для большинства случаев использования.
Для тестовых случаев, вы можете посмотреть на этом сайте
Вы должны пойти по следующему правилу...
Если вам нужны данные из более чем одной таблицы, то вы всегда можете использовать объединение.
Вы можете использовать подзапросы, если вам требуется более одного запроса, и каждый подзапрос предоставляет подмножество таблицы, участвующей в запросе.
Если для запроса требуется условие NOT EXISTS, то вы должны использовать подзапрос, поскольку NOT EXISTS работает только в подзапросе; тот же принцип справедлив для условия EXISTS.
ПРОЦЕДУРА Оптимизатор SQL-запросов заменяет некоторые подзапросы на объединения, а объединение, как правило, более эффективно для обработки.