Обоснование для std::lower_bound и std::upper_bound?
STL предоставляет бинарные функции поиска std::lower_bound и std::upper_bound, но я не использую их, потому что не могу вспомнить, что они делают, потому что их контракты кажутся мне совершенно загадочными.
Просто взглянув на имена, я бы предположил, что "lower_bound" может быть сокращением от "последней нижней границы",
т.е. последний элемент в отсортированном списке, который является <= заданным значением (если есть).
И точно так же я бы предположил, что "upper_bound" может быть сокращенным от "первой верхней границы",
то есть первый элемент в отсортированном списке, который>= данный val (если есть).
Но документация говорит, что они делают что-то отличное от этого - что-то, что кажется мне смесью обратной и случайной. Перефразируя документ:
- lower_bound находит первый элемент, который>= val
- upper_bound находит первый элемент, который> val
Так что lower_bound вообще не находит нижней границы; он находит первую верхнюю границу!? И upper_bound находит первую строгую верхнюю границу.
Есть ли в этом смысл?? Как ты это помнишь?
9 ответов
Если у вас есть несколько элементов в диапазоне [first, last) значение которого равно значению val вы ищете, то диапазон [l, u) где
l = std::lower_bound(first, last, val)
u = std::upper_bound(first, last, val)
точно диапазон элементов равен val в пределах диапазона [first, last). Так l а также u являются "нижней границей" и "верхней границей" для равного диапазона. Это имеет смысл, если вы привыкли мыслить в терминах полуоткрытых интервалов.
(Обратите внимание, что std::equal_range вернет нижнюю и верхнюю границу в паре за один вызов.)
std::lower_bound
Возвращает итератор, указывающий на первый элемент в диапазоне [first, last), который не меньше (то есть больше или равен) значению.
std::upper_bound
Возвращает итератор, указывающий на первый элемент в диапазоне [first, last), который больше значения.
Таким образом, смешивая нижнюю и верхнюю границы, вы можете точно описать, где начинается ваш диапазон и где он заканчивается.
Есть ли в этом смысл??
Да.
Пример:
представьте себе вектор
std::vector<int> data = { 1, 1, 2, 3, 3, 3, 3, 4, 4, 4, 5, 5, 6 };
auto lower = std::lower_bound(data.begin(), data.end(), 4);
1, 1, 2, 3, 3, 3, 3, 4, 4, 4, 5, 5, 6
// ^ lower
auto upper = std::upper_bound(data.begin(), data.end(), 4);
1, 1, 2, 3, 3, 3, 3, 4, 4, 4, 5, 5, 6
// ^ upper
std::copy(lower, upper, std::ostream_iterator<int>(std::cout, " "));
принты: 4 4 4
В этом случае, я думаю, картина стоит тысячи слов. Давайте предположим, что мы используем их для поиска 2 в следующих коллекциях. Стрелки показывают, какие итераторы вернутся:
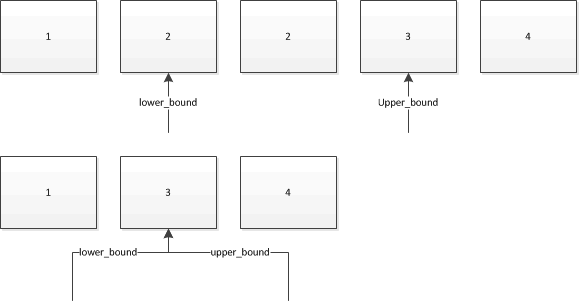
Итак, если у вас есть более одного объекта с этим значением, уже присутствующим в коллекции, lower_bound даст вам итератор, который ссылается на первый из них, и upper_bound даст итератор, который ссылается на объект сразу после последнего из них.
Это (среди прочего) делает возвращаемые итераторы пригодными для использования в качестве hint параметр для insert,
Поэтому, если вы используете их в качестве подсказки, вставляемый элемент станет новым первым элементом с этим значением (если вы использовали lower_bound) или последний элемент с этим значением (если вы использовали upper_bound). Если в коллекции ранее не было элемента с этим значением, вы все равно получите итератор, который можно использовать как hint вставить его в правильное положение в коллекции.
Конечно, вы также можете вставить без подсказки, но с помощью подсказки вы получите гарантию, что вставка завершится с постоянной сложностью, при условии, что новый элемент для вставки может быть вставлен непосредственно перед элементом, на который указывает итератор (как это будет в оба эти случая).
Я принял ответ Брайана, но я только что понял другой полезный способ обдумать его, который добавляет мне ясности, поэтому я добавляю это для справки.
Воспринимайте возвращаемый итератор как указывающий не на элемент *iter, а непосредственно перед этим элементом, то есть между этим элементом и предыдущим элементом в списке, если таковой имеется. Думая об этом, контракты двух функций становятся симметричными: lower_bound находит позицию перехода от
Я хотел бы, чтобы они говорили об этом (или любой другой хороший ответ) в документах; это сделало бы это намного менее таинственным!
Рассмотрим последовательность
1 2 3 4 5 6 6 6 7 8 9
нижняя граница для 6- это позиция первых 6.
верхняя граница для 6- это позиция 7.
эти позиции служат общей (начало, конец) парой, обозначающей последовательность 6 значений.
Пример:
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
auto main()
-> int
{
vector<int> v = {1, 2, 3, 4, 5, 6, 6, 6, 7, 8, 9};
auto const pos1 = lower_bound( v.begin(), v.end(), 6 );
auto const pos2 = upper_bound( v.begin(), v.end(), 6 );
for( auto it = pos1; it != pos2; ++it )
{
cout << *it;
}
cout << endl;
}
Обе функции очень похожи в том, что они найдут точку вставки в отсортированной последовательности, которая сохранит сортировку. Если в последовательности нет существующих элементов, равных элементу поиска, они возвращают тот же итератор.
Если вы пытаетесь найти что-то в последовательности, используйте lower_bound - он будет указывать непосредственно на элемент, если он найден.
Если вы вставляете в последовательность, используйте upper_bound - сохраняет первоначальный порядок дубликатов.
Исходный код на самом деле имеет второе объяснение, которое я нашел очень полезным для понимания значения функции:
lower_bound: находит первую позицию, в которую можно вставить [val] без изменения порядка.
upper_bound: находит последнюю позицию, в которую можно вставить [ val] без изменения порядка.
this [first, last) формирует диапазон, в который val может быть вставлен, но при этом сохраняет первоначальный порядок контейнера
lower_bound возвращает "first", т.е. находит "нижнюю границу диапазона"
upper_bound возвращает "последний", т.е. находит "верхнюю границу диапазона"
Да. Вопрос абсолютно имеет смысл. Когда кто-то называл эти функции своими именами, он думал только о отсортированных массивах с повторяющимися элементами. Если у вас есть массив с уникальными элементами, std::lower_bound() действует больше как поиск "верхней границы", если он не находит фактический элемент.
Вот что я помню об этих функциях:
- Если вы выполняете бинарный поиск, подумайте об использовании std::lower_bound() и прочитайте руководство. На этом основывается и std::binary_search().
- Если вы хотите найти "место" значения в отсортированном массиве уникальных значений, рассмотрите std::lower_bound() и прочитайте руководство.
- Если у вас есть произвольная задача поиска в отсортированном массиве, прочтите руководство для std::lower_bound() и std::upper_bound().
Если вы не прочитали руководство по истечении месяца или двух с момента последнего использования этих функций, это почти наверняка приведет к ошибке.
Представьте, что бы вы сделали, если хотите найти первый элемент, равный val в [first, last), Вы сначала исключаете из первых элементов, которые строго меньше, чем val, а затем исключить назад из прошлого - 1 строго больше, чем val, Тогда оставшийся диапазон [lower_bound, upper_bound]
Уже есть хорошие ответы о том, что std::lower_bound а также std::upper_boundявляется.
Я хотел бы ответить на ваш вопрос "как их запомнить"?
Его легко понять / запомнить, если провести аналогию с STL begin() а также end() методы любого контейнера. begin() возвращает начальный итератор в контейнер end() возвращает итератор, который находится вне контейнера, и мы все знаем, насколько они полезны при итерации.
Теперь на отсортированном контейнере и заданном значении, lower_boundа также upper_bound вернет диапазон итераторов для этого значения, которое легко перебирать (как начало и конец)
Практическое использование::
Помимо вышеупомянутого использования в отсортированном списке для доступа к диапазону для данного значения, одно из лучших применений upper_bound - это доступ к данным, имеющим отношение "многие к одному" на карте.
Например, рассмотрим следующее соотношение: 1 -> a, 2 -> a, 3 -> a, 4 -> b, 5 -> c, 6 -> c, 7 -> c, 8 -> c, 9 -> с, 10 -> с
Вышеуказанные 10 отображений могут быть сохранены в карте следующим образом:
numeric_limits<T>::lowest() : UND
1 : a
4 : b
5 : c
11 : UND
Доступ к значениям можно получить по выражению (--map.upper_bound(val))->second,
Для значений T в диапазоне от минимального до 0 выражение будет возвращать UND, Для значений T в диапазоне от 1 до 3 он возвращает "a" и т. Д.
Теперь представьте, что у нас есть сотни отображений данных на одно значение и сотни таких отображений. Такой подход уменьшает размер карты и тем самым делает ее эффективной.
Для массива или вектора:
std:: lower_bound: возвращает итератор, указывающий на первый элемент в диапазоне
- меньше или равно значению.(для массива или вектора в порядке убывания)
- больше или равно значению.(для массива или вектора в порядке возрастания)
std:: upper_bound: возвращает итератор, указывающий на первый элемент в диапазоне
меньше значения.(для массива или вектора в порядке убывания)
больше значения.(для массива или вектора в порядке возрастания)