Почему C++ выводит отрицательные числа при использовании по модулю?
Математика:
Если у вас есть такое уравнение:
x = 3 mod 7
х может быть... -4, 3, 10, 17, ... или, в более общем случае:
x = 3 + k * 7
где k может быть любым целым числом. Я не знаю, какая операция по модулю определена для математики, но кольцо факторов определенно таково.
Python:
В Python вы всегда получите неотрицательные значения при использовании % с положительным m:
#!/usr/bin/python
# -*- coding: utf-8 -*-
m = 7
for i in xrange(-8, 10 + 1):
print(i % 7)
Результаты в:
6 0 1 2 3 4 5 6 0 1 2 3 4 5 6 0 1 2 3
C++:
#include <iostream>
using namespace std;
int main(){
int m = 7;
for(int i=-8; i <= 10; i++) {
cout << (i % m) << endl;
}
return 0;
}
Будет выводить:
-1 0 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 0 1 2 3
ISO / IEC 14882: 2003 (E) - 5.6 Мультипликативные операторы:
Двоичный / оператор дает частное, а двоичный оператор% - остаток от деления первого выражения на второе. Если второй операнд / или% равен нулю, поведение не определено; в противном случае (a/b)*b + a%b равно a. Если оба операнда неотрицательны, то остаток неотрицателен; если нет, то знак остатка определяется реализацией 74).
а также
74) В соответствии с проводимой работой по пересмотру ISO C, предпочтительный алгоритм целочисленного деления следует правилам, определенным в стандарте ISO Fortran, ISO/IEC 1539:1991, в котором частное всегда округляется до нуля.
Источник: ISO / IEC 14882: 2003 (E)
(Я не мог найти бесплатную версию ISO/IEC 1539:1991, Кто-нибудь знает, где его взять?)
Кажется, что операция определена так:
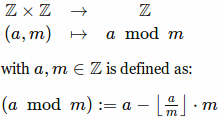
Вопрос:
Есть ли смысл определять это так?
Каковы аргументы для этой спецификации? Есть ли место, где люди, которые создают такие стандарты, обсуждают это? Где я могу прочитать кое-что о причинах, почему они решили сделать это таким образом?
Большую часть времени, когда я использую модуль, я хочу получить доступ к элементам структуры данных. В этом случае я должен убедиться, что мод возвращает неотрицательное значение. Таким образом, для этого случая было бы хорошо, чтобы мод всегда возвращал неотрицательное значение. (Другое использование - это евклидов алгоритм. Поскольку вы могли бы сделать оба числа положительными, прежде чем использовать этот алгоритм, знак модуля имел бы значение.)
Дополнительный материал:
Посмотрите Википедию для длинного списка того, что по модулю делает на разных языках.
4 ответа
На x86 (и других процессорных архитектурах) целочисленное деление и деление по модулю выполняются одной операцией, idiv (div для значений без знака), который производит как частное, так и остаток (для аргументов размером с слово, в AX а также DX соответственно). Это используется в функции библиотеки C divmod, который может быть оптимизирован компилятором для одной инструкции!
Целочисленное деление соблюдает два правила:
- Нецелые коэффициенты округляются до нуля; а также
- уравнение
dividend = quotient*divisor + remainderдоволен результатами.
Соответственно, при делении отрицательного числа на положительное число частное будет отрицательным (или нулем).
Таким образом, это поведение можно рассматривать как результат цепочки локальных решений:
- Конструкция набора команд процессора оптимизируется для общего случая (деления) по сравнению с менее распространенным случаем (по модулю);
- Согласованность (округление до нуля и соблюдение уравнения деления) предпочтительнее математической корректности;
- C предпочитает эффективность и просто (особенно учитывая тенденцию рассматривать C как "ассемблер высокого уровня"); а также
- C++ предпочитает совместимость с C.
Когда-то, кто-то разрабатывал набор команд x86, решил, что правильно и хорошо округлять целочисленное деление в сторону нуля, а не округлять в меньшую сторону. (Пусть бороды тысячи верблюдов гнездятся в бороде его матери.) Чтобы сохранить некоторое подобие математической правильности, оператор REM, который произносится как "остаток", должен был вести себя соответствующим образом. НЕ читайте это: https://www.ibm.com/support/knowledgecenter/ssw_ibm_i_73/rzatk/REM.htm
Я предупреждал тебя. Позже кто-то, кто занимался спецификацией C, решил, что компилятору будет целесообразно сделать это правильно или x86. Затем комитет, занимающийся спецификацией C++, решил сделать это C-способом. Но позже, после того, как этот вопрос был опубликован, комитет по С ++ решил стандартизировать неправильный путь. Теперь мы застряли с этим. Многие программисты написали следующую функцию или что-то в этом роде. Я, вероятно, делал это по крайней мере дюжину раз.
inline int mod(int a, int b) {int ret = a%b; return ret>=0? ret: ret+b; }
Там идет ваша эффективность.
В эти дни я использую, по существу, следующее, с добавлением некоторых вещей type_traits. (Спасибо Clearer за комментарий, который дал мне идею для улучшения, используя последний день C++. См. Ниже.)
<strike>template<class T>
inline T mod(T a, T b) {
assert(b > 0);
T ret = a%b;
return (ret>=0)?(ret):(ret+b);
}</strike>
template<>
inline unsigned mod(unsigned a, unsigned b) {
assert(b > 0);
return a % b;
}
Истинный факт: я лоббировал комитет по стандартам Pascal, чтобы сделать мод правильно, пока они не уступят. К моему ужасу, они делали целочисленное деление в неправильном направлении. Так что они даже не совпадают.
РЕДАКТИРОВАТЬ: Яснее дал мне идею. Я работаю над новым.
#include <type_traits>
template<class T1, class T2>
inline T1 mod(T1 a, T2 b) {
assert(b > 0);
T1 ret = a % b;
if constexpr ( std::is_unsigned_v<T1>)
{
return ret;
} else {
return (ret >= 0) ? (ret) : (ret + b);
}
}
Каковы аргументы для этой спецификации?
Одной из целей разработки C++ является эффективное сопоставление с оборудованием. Если базовое аппаратное обеспечение реализует разделение таким образом, чтобы получить отрицательные остатки, то это то, что вы получите, если будете использовать % в C++. Вот и все, что нужно сделать.
Есть ли место, где люди, которые создают такие стандарты, обсуждают это?
Вы найдете интересные дискуссии по comp.lang.C++. Moderated и, в меньшей степени, comp.lang.C++
Другие достаточно хорошо описали причину, и, к сожалению, вопрос, требующий решения, помечен как дубликат этого вопроса, и исчерпывающий ответ по этому аспекту, похоже, отсутствует. Кажется, есть 2 часто используемых общих решения и один особый случай, который я хотел бы включить:
// 724ms
inline int mod1(int a, int b)
{
const int r = a % b;
return r < 0 ? r + b : r;
}
// 759ms
inline int mod2(int a, int b)
{
return (a % b + b) % b;
}
// 671ms (see NOTE1!)
inline int mod3(int a, int b)
{
return (a + b) % b;
}
int main(int argc, char** argv)
{
volatile int x;
for (int i = 0; i < 10000000; ++i) {
for (int j = -argc + 1; j < argc; ++j) {
x = modX(j, argc);
if (x < 0) return -1; // Sanity check
}
}
}
ПРИМЕЧАНИЕ 1: Обычно это неверно (т. е. еслиa < -b). Причина, по которой я включил его, заключается в том, что почти каждый раз, когда я беру модуль отрицательного числа, это происходит, когда я занимаюсь математикой с уже модифицированными числами , например.(i1 - i2) % nгде0 <= iX < n(например, индексы кольцевого буфера).
Как всегда, YMMV в отношении сроков.