Производная таблица с "order by" использует временную таблицу и сортировку файлов, хотя я выбираю только первичный ключ
Есть форум с таблицами: сообщения, темы, форумы, пользователи.
Я пытаюсь перечислить последние 30 сообщений с соответствующими данными из других таблиц, а также количество сообщений в теме, в которой находится сообщение.
Это запрос, который я использую:
SELECT t.id, t.name, t.permissions, t.author, t.added, COUNT(p2.id) pcount, u2.username pusername, u2.id pauthor, p.added padded, p.id pid, u.username
FROM posts p
INNER JOIN (SELECT id FROM posts ORDER BY id DESC LIMIT 30) tmp ON tmp.id = p.id
INNER JOIN topics t ON t.id = p.topic
INNER JOIN users u ON t.author = u.id
INNER JOIN users u2 ON p.author = u2.id
INNER JOIN posts p2 ON p2.topic = t.id
GROUP BY id, name, permissions, author, added, pusername, pauthor, padded, pid, username
Объясните SQL: 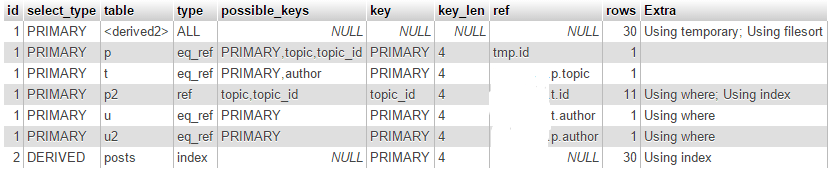
Если я уберу оператор GROUP BY, файловая сортировка и временная таблица исчезнут, хотя это не должно изменить это (я полагаю).
SELECT t.id, t.name, t.permissions, t.author, t.added, u2.username pusername, u2.id pauthor, p.added padded, p.id pid, u.username
FROM posts p
INNER JOIN (SELECT id FROM posts ORDER BY id DESC LIMIT 30) tmp ON tmp.id = p.id
INNER JOIN topics t ON t.id = p.topic
INNER JOIN users u ON t.author = u.id
INNER JOIN users u2 ON p.author = u2.id
INNER JOIN posts p2 ON p2.topic = t.id
Объясните SQL: http://i.imgur.com/z3Xkqu2.png
Также у меня есть другой запрос, который выполняет то же самое, но я должен использовать левое соединение, чтобы избежать сортировки файлов и временной таблицы.
SELECT t.id, t.name, t.permissions, t.author, t.added, (SELECT COUNT(*) FROM posts WHERE topic = t.id) as pcount, u2.username as pusername, u2.id as pauthor, p.added as padded, p.id as pid, u.username
FROM posts p
LEFT JOIN topics t ON t.id = p.topic
LEFT JOIN users u ON t.author = u.id
LEFT JOIN users u2 ON p.author = u2.id
ORDER BY p.id DESC LIMIT 30
Объясните SQL: http://i.imgur.com/qQMjBIV.png
Мои вопросы:
- Какой запрос является лучшим в отношении производительности (оба достигают одного и того же)
- Если первый лучше, как я могу избавиться от сортировки файлов и временной таблицы (я должен даже? Или все в порядке, и только побочный эффект оптимизатора?)
Спасибо, парни!
1 ответ
Ваш третий запрос в порядке и намного проще, чем предыдущие два. Однако я не уверен, почему вам нужно использовать LEFT JOIN или почему не использовать INNER JOIN, что приведет к сортировке файлов.
SELECT t.id, t.name, t.permissions, t.author, t.added, (SELECT COUNT(*) FROM posts WHERE topic = t.id) as pcount, u2.username as pusername, u2.id as pauthor, p.added as padded, p.id as pid, u.username
FROM posts p
INNER JOIN topics t ON t.id = p.topic
INNER JOIN users u ON t.author = u.id
INNER JOIN users u2 ON p.author = u2.id
ORDER BY p.id DESC LIMIT 30
Выше приведен простой запрос по вашему запросу.
Если вы можете предоставить пример http://sqlfiddle.com/ для файловой сортировки, вызванный использованием INNER JOIN вместо LEFT JOIN, то мы можем исследовать это.
Обновление после SQLFiddle при условии
Используя ваше sqlfiddle, я смог обнаружить интересное поведение и информацию. При различных условиях сортировка файлов будет появляться, а другие приводят к ее исчезновению.
Одним из таких вопросов является редкостьusersтаблица в sqlfiddle; поэтому я добавил туда больше записей, так как ранее использование INNER JOIN не приводило к возвращению результатов.
В любом случае, существует 3 возможных исправления, и вам придется применить их к вашему реальному набору данных, чтобы определить, сколько из них вам нужно применить.
Опция 1
Изменить все таблицы сMyISAMвInnoDB,
Вариант 2
Если изменение типа таблицы невозможно или недостаточно, добавьте индекс кpostsТаблица.
ALTER TABLE `posts`
ADD INDEX `id_topic_author_added_i` (`id`,`topic`,`author`,`added`);
Вариант 3
Если два вышеуказанных варианта недоступны или недостаточны, добавьте индекс кusersТаблица.
ALTER TABLE `users`
ADD INDEX `id_username_i` (`id`,`username`);
аргументация
Назначение индексов и движка изменяет его, чтобы запрос мог совершить одиночное путешествие к таблице. В InnoDB кластерный первичный ключ должен предоставлять именно те индексы, которые необходимы для этого на основе вашего запроса. Я не так хорошо знаком с MyISAM, но это не работало в sqlfiddle, по крайней мере.
Я могу расширить "почему", эти индексы помогают, если вы хотите.
Вы также можете посмотреть на мой http://sqlfiddle.com/ со всеми примененными 3 опциями и убедиться, что произойдет, когда вы удалите каждую из опций выше.
Обновление: почему добавление этих индексов работает
Во-первых, давайте начнем с некоторых вещей из документации, которая, как нам говорят, разрешит или не позволит использовать индекс (если вы не используете индекс, вы, скорее всего, получите вместо этого файловую сортировку):
Следующие запросы используют индекс для разрешения части ORDER BY:
SELECT * FROM t1 ORDER BY key_part1, key_part2,...;
Таким образом, это означает, что мы должны иметь столбец ORDER BY первой частью ключа (он же индекс).
Это все, что говорит о том, что относится к этому запросу с точки зрения того, что позволит использовать индексы. Теперь, что помешает индексам быть полезными:
Вы объединяете много таблиц, и столбцы в ORDER BY не все из первой непостоянной таблицы, которая используется для получения строк. (Это первая таблица в выводе EXPLAIN, которая не имеет типа соединения const.)
Мы присоединяемся к таблицам, поэтому мы обязательно должны рассмотреть этот вопрос и выяснить, как posts Стол первый.
Ключ, используемый для извлечения строк, не совпадает с ключом, используемым в ORDER BY
Итак, нам нужно убедиться, что мы используем один и тот же ключ. Как мы это делаем?
Ну, в общем, лучший ответ - создать так называемый индекс покрытия. Это означает, что один индекс содержит все столбцы, которые вы хотите иметь в операторе SELECT.
Если у вас нет покрывающего индекса, то может случиться так, что запрос в конечном итоге использует индекс для поиска записи, а затем использует первичный ключ, добавленный ко всем индексам, для поиска в главной строке (которая содержит все столбцы), а затем он имеет все необходимые значения столбцов. Однако при этом он выполнил 2 поиска в строке, и это то, чего пытается избежать индекс покрытия.
Таким образом, с индексом Варианта 2, который работал выше, вы можете видеть, что это индекс покрытия, так что можно получить один просмотр posts Таблица. Также из-за id Во-первых, мы выполняем первое условие выше. Покрывающая индексная часть и размещение столбцов, используемых для объединения с другими таблицами (topic а также author) мы разрешаем запросу сделать эти объединения после перехода к posts таблица (по крайней мере, я думаю, что это то, что происходит, я как бы махаю рукой на это предложение.) Таким образом, мы гарантируем, что оно является первым в EXPLAIN, и поэтому избегаем второго условия, описанного выше, которое помешало бы использованию индекса,
Вот почему индекс работает.
Теперь странно то, что если вы используете InnoDB, то строки организуются вокруг первичного ключа каждой из таблиц, что называется кластеризованным индексом. Кластерный индекс - это эффективный индекс для всех столбцов, не относящихся к TEXT или BLOB.
Таким образом, изменение типа двигателя на InnoDB должно быть достаточно. Что касается того, почему это не так, это превышает мои знания, и поэтому вам придется открыть новый вопрос для этого, если вам все еще интересно.