Оценка Size() для последовательного Spliterator
Я реализую Spliterator что явно ограничивает распараллеливание, имея trySplit() вернуть null, Будет внедрять estimateSize() предложить какие-либо улучшения производительности для потока, созданного этим сплитератором? Или приблизительный размер полезен только для распараллеливания?
РЕДАКТИРОВАТЬ: Чтобы уточнить, я специально спрашиваю о приблизительном размере. Другими словами, мой сплитератор не имеет SIZED характеристика.
2 ответа
Глядя на иерархию вызовов для соответствующей характеристики сплитератора, выявляется, что она, по крайней мере, актуальна для stream.toArray() спектакль
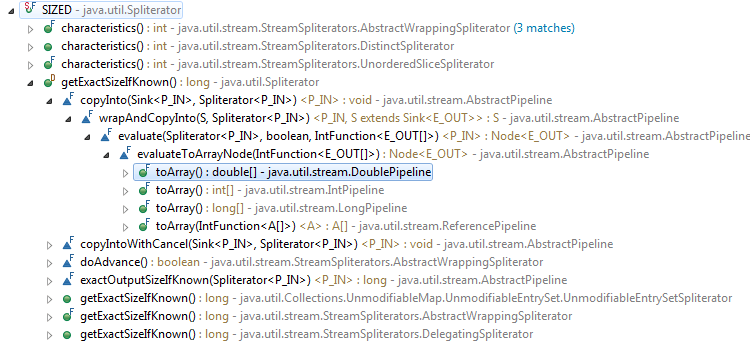
Кроме того, в реализации внутреннего потока есть эквивалентный флаг, который, кажется, используется для сортировки:
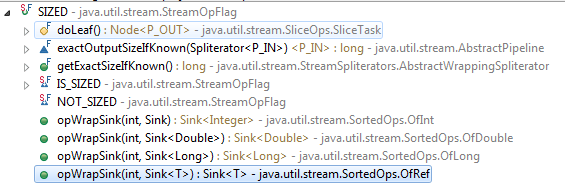
Таким образом, помимо параллельных потоковых операций, оценка размера, по-видимому, используется для этих двух операций.
Я не требую исчерпывающих результатов для моего поиска, поэтому просто возьмите их в качестве примеров.
Без характеристики SIZED я могу только найти звонки estimateSize() которые имеют отношение к параллельному выполнению потокового конвейера.
Конечно, это может измениться в будущем или другой реализации Stream, чем стандартная JDK, которая могла бы действовать по-другому.
Сплитератор может проходить элементы:
1. Индивидуально ( tryAdvance ())
2. Последовательно навалом ( forEachRemaining ())
Согласно документам Java estimateSize() пригодится при расщеплении.
Сплитераторы могут предоставить оценку количества оставшихся элементов с помощью метода эстимейзинга (). В идеале, как отражено в характеристике SIZED, это значение точно соответствует количеству элементов, которые встретятся при успешном обходе. Однако, даже когда точно не известно, значение оценочного значения может все еще быть полезным для операций, выполняемых над источником, таких как помощь в определении того, является ли предпочтительным разделение дальше или прохождение остальных элементов последовательно.
Так как ваш сплитератор не имеет характеристики SIZED estimateSize не будет предлагать никакой производительности (из-за отсутствия параллелизма), однако имейте в виду, что Java-документы estimateSize ничего не говорится о параллелизме, все, что он заявляет:
Возвращает: предполагаемый размер или Long.MAX_VALUE, если он бесконечен, неизвестен или слишком дорог для вычисления.