Приведет ли избыточная выборка к переоснащенной модели?
Целевое распределение атрибута в настоящее время выглядит так:
mydata.groupBy("Churn").count().show()
+-----+-----+
|Churn|count|
+-----+-----+
| 1| 483|
| 0| 2850|
+-----+-----+
Мои вопросы:
методы передискретизации, такие как: manully, smote, adasyn собираются использовать имеющиеся данные для создания новых точек данных?
Если мы будем использовать такие данные для обучения модели классификации, не будет ли она переопределена?
1 ответ
Мой вопрос заключается в том, что любой метод передискретизации (вручную, smote, adasyn) будет использовать доступные данные для создания новых точек данных.
- Проблемы с дисбалансом данных в основном решаются в три этапа:
- Превышение выборки класса меньшинства.
- Под выборка класс большинства.
- Синтез новых меньшинств классов.
SMOTE (Техника искусственной избыточной выборки меньшинств) подпадает под третий шаг. Это процесс создания новых меньшинств классов из наборов данных.
Процесс в SMOTE упомянут ниже:
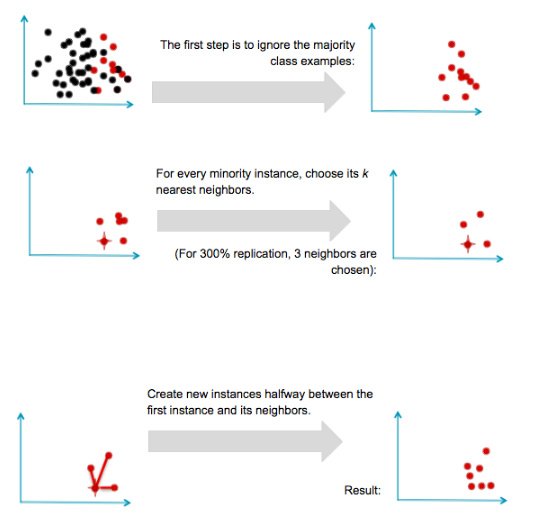
Таким образом, это немного умнее, чем просто передискретизация.
Если мы используем такие данные для построения классификационной модели, не будет ли она переопределена?
Правильный ответ будет ВЕРОЯТНО. Попробуйте!
Вот почему мы используем тестовые наборы и перекрестную проверку, чтобы понять, будет ли модель работать с невидимыми данными!