Как я могу переместить таблицу в другую файловую группу?
У меня есть SQL Server 2008 Ent и база данных OLTP с двумя большими таблицами. Как я могу переместить эти таблицы в другую файловую группу без прерывания обслуживания? Теперь вставлено около 100-130 записей и 30-50 записей обновляются каждую секунду в этих таблицах. Каждая таблица имеет около 100 миллионов записей и шесть полей (включая географию одного поля).
Я ищу решение через Google, но все решения содержат "создать вторую таблицу, вставить строки из первой таблицы, удалить первую таблицу, бла-бла-бла".
Могу ли я использовать функции разбиения для решения этой проблемы? Спасибо.
10 ответов
Если вы хотите просто переместить таблицу в новую файловую группу, вам нужно воссоздать кластеризованный индекс в таблице (в конце концов: кластеризованный индекс - это данные таблицы) в новой файловой группе, которую вы хотите.
Вы можете сделать это, например:
CREATE CLUSTERED INDEX CIX_YourTable
ON dbo.YourTable(YourClusteringKeyFields)
WITH DROP_EXISTING
ON [filegroup_name]
или если ваш кластерный индекс уникален:
CREATE UNIQUE CLUSTERED INDEX CIX_YourTable
ON dbo.YourTable(YourClusteringKeyFields)
WITH DROP_EXISTING
ON [filegroup_name]
Это создает новый кластеризованный индекс и удаляет существующий, а также создает новый кластеризованный индекс в указанной вами файловой группе - и вуаля, данные вашей таблицы были перемещены в новую файловую группу.
Посмотрите документы MSDN на CREATE INDEX для получения подробной информации обо всех доступных опциях, которые вы можете указать.
Это, конечно, еще не касается разделения, но это уже совсем другая история...
Чтобы ответить на этот вопрос, сначала мы должны понять
- Если таблица не имеет индекса, ее данные называются кучей
- Если таблица имеет кластеризованный индекс, этот индекс фактически является данными вашей таблицы. Следовательно, если вы перемещаете кластерный индекс, вы также перемещаете свои данные.
Первый шаг - узнать больше информации о таблице, которую мы хотим переместить. Мы делаем это, выполняя этот T-SQL:
sp_help N'<<your table name>>'
Вывод покажет вам столбец с названием "Data_located_on_filegroup". Это удобный способ узнать, в какой файловой группе находятся данные вашей таблицы. Но более важным является вывод, который показывает вам информацию об индексах таблицы. (Если вы хотите видеть только информацию об индексах таблиц, просто запустите sp_helpindex N'<<your table name>>') Ваша таблица может иметь: 1) нет индексов (так что это куча), 2) один индекс или 3) несколько индексов. Если index_description начинается с 'cluster, unique, ...', это индекс, который вы хотите переместить. Если индекс также является первичным ключом, это нормально, вы все равно можете его переместить.
Чтобы переместить индекс, запишите index_name и index_keys, показанные в результатах вышеупомянутого запроса справки, а затем используйте их для заполнения <<blanks>> в следующем запросе:
CREATE UNIQUE CLUSTERED INDEX [<<name of clustered index>>]
ON [<<table name>>]([<<column name the index is on - from index_keys above>>])
WITH DROP_EXISTING, ONLINE
ON <<name of file group you want to move the index to>>
DROP EXISTING, ONLINE варианты выше важны. DROP EXISTING следит за тем, чтобы индекс не дублировался, и ONLINE держит стол в сети, пока вы двигаете его.
Если перемещаемый вами индекс не является кластеризованным, то замените UNIQUE CLUSTERED выше с NONCLUSTERED
Чтобы переместить таблицу кучи, добавьте в нее кластеризованный индекс, затем запустите приведенный выше оператор, чтобы переместить его в другую файловую группу, а затем отбросьте индекс.
А теперь вернись и беги sp_help на вашей таблице и проверьте результаты, чтобы увидеть, где теперь находятся ваши данные таблицы и индекса.
Если ваша таблица имеет более одного индекса, то после выполнения приведенного выше оператора для перемещения кластеризованного индекса, sp_helpindex покажет, что ваш кластерный индекс находится в новой файловой группе, но все остальные индексы все еще будут в исходной файловой группе. Таблица продолжит нормально функционировать, но у вас должна быть веская причина, по которой вы хотите, чтобы индексы находились в разных файловых группах. Если вы хотите, чтобы таблица и все ее индексы находились в одной файловой группе, повторите приведенные выше инструкции для каждого индекса, заменив CREATE [NONCLUSTERED, or other] ... DROP EXISTING... по мере необходимости, в зависимости от типа перемещаемого вами индекса.
Разделение - это одно из решений, но вы можете "переместить" кластеризованный индекс в новую файловую группу без прерывания обслуживания (в зависимости от некоторых условий, см. Ссылку ниже), используя
CREATE CLUSTERED /*oops*/ INDEX ... WITH (DROP_EXISTING = ON, ONLINE = ON, ...) ON newfilegroup
Кластерный индекс - это данные, и это то же самое, что и перемещение файловой группы.
Пожалуйста, смотрите CREATE INDEX
Это зависит от того, является ли ваш первичный ключ кластеризованным или нет, что меняет то, как мы это сделаем
Обратите внимание, что при воссоздании кластеризованного индекса перемещаются только "примитивные" столбцы, например int, bit, datetime и т.п.
Двигаться varchar(max), varbinary и другие столбцы "blob", которые вы должны воссоздать таблицу. К счастью, есть способ сделать это полуавтоматически в SSMS - изменив "текстовую файловую группу" в окне "дизайн" таблицы, а затем сохранив изменения.
Я написал об этом здесь: https://www.jitbit.com/alexblog/153-moving-sql-table-textimage-to-a-new-filegroup/ если вам нужна дополнительная информация.
В SSMS разверните «Таблицы», разверните таблицу, которую вы хотите переместить, разверните «Индексы», щелкните правой кнопкой мыши кластерный индекс, выберите «Сценарий индексирования как» -> «Перетащить и создать в»
Это откроет окно запроса со сценарием, чтобы удалить кластерный индекс и создать новый с теми же характеристиками, что и исходный.
В окне запроса в операторе «ALTER TABLE <> ADD CONSTRAINT» измените имя файловой группы после ключевого слова «ON» в конце оператора, например, если таблица находится в ПЕРВИЧНОЙ файловой группе и вы хотите перейти в файловую группу с именем « ВТОРИЧНЫЙ ", измените" ВКЛ [ПЕРВИЧНЫЙ] "на" ВКЛ [ВТОРИЧНЫЙ]". Также измените «ONLINE = OFF» на «ONLINE = ON», если вы хотите, чтобы стол оставался в сети.
Запустите сценарий, и он отбросит оригинал и создаст новый в данной файловой группе.
В этом отрывке из SQL Server Books Online сказано все: "Поскольку конечный уровень кластерного индекса и страниц данных по определению одинаков, создание кластерного индекса и использование предложения ON partition_scheme_name или ON filegroup_name эффективно перемещает таблицу из файловой группы. на котором была создана таблица с новой схемой разделов или файловой группой." (Источник - http://msdn.microsoft.com/en-us/library/ms188783.aspx) из ( http://www.mssqltips.com/sqlservertip/2442/move-data-between-sql-server-database-filegroups/)
как уже говорили другие друзья, например, принятый ответ marc_s, следующий скриншот дает вам еще один способ сделать это с помощью SSMS GUI.
обратите внимание, что вы можете легко перейти к другой файловой группе из свойства index на вкладке Storage.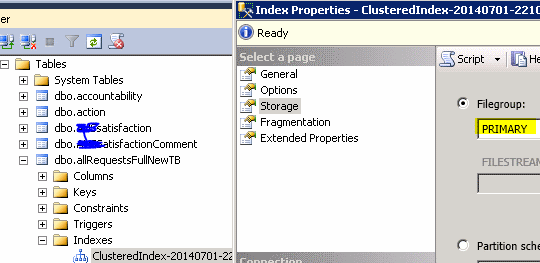
Как я могу переместить таблицу в другую файловую группу?
ПРИМЕЧАНИЕ. Перемещение таблицы в другую файловую группу работает только в Enterprise Edition.
Шаг 1:
Проверьте, в какой таблице находится файловая группа:
-- Query to check the tables and their current filegroup:
SELECT tbl.name AS [Table Name],
CASE WHEN dsidx.type='FG' THEN dsidx.name ELSE '(Partitioned)' END AS [File Group]
FROM sys.tables AS tbl
JOIN sys.indexes AS idx
ON idx.object_id = tbl.object_id
AND idx.index_id <= 1
LEFT JOIN sys.data_spaces AS dsidx
ON dsidx.data_space_id = idx.data_space_id
ORDER BY [File Group], [Table Name]
Шаг 2:
Переместить существующую таблицу / таблицы в новую файловую группу
Если файловая группа, в которую вы хотите переместить таблицу, еще не существует, создайте дополнительную файловую группу и переместите таблицу.
Чтобы переместить таблицу в другую файловую группу, необходимо переместить кластерный индекс таблицы в новую файловую группу. Конечный уровень кластеризованного индекса фактически содержит данные таблицы. Таким образом, перемещение кластеризованного индекса может быть выполнено в одном выражении с помощью предложения DROP_EXISTING следующим образом:
CREATE UNIQUE CLUSTERED INDEX [Index_Name] ON [SchemaName].[TableName]
(
[ClusteredIndexKeyFields]
)WITH (DROP_EXISTING = ON, ONLINE = ON) ON [FilegroupName]
GO
Шаг 3:
Переместите оставшиеся некластеризованные индексы во вторичную файловую группу
Вы должны переместить некластеризованные индексы вручную, используя приведенный ниже синтаксис:
--1st check the index information using the following sp
sp_helpindex [YourTableName]
--Now by using the following query you can move the remaining indexes to secondary filegroup
CREATE NONCLUSTERED INDEX [Index_Name] ON [SchemaName].[TableName]
(
[IndexKeyFields]
)WITH (DROP_EXISTING = ON, ONLINE = ON) ON [FilegroupName]
GO
Перемещение кучи в другую файловую группу:
Как я знаю, единственный способ переместить кучу в другую файловую группу - это временно добавить кластерный индекс в новую файловую группу, а затем удалить его (при необходимости).
CREATE CLUSTERED INDEX IXC_Products_Product_id
ON dbo.Products(Product_id)
WITH (DROP_EXISTING = ON) ON MyNewFileGroup
Была та же проблема, и это сценарий, который я придумал (проверено и работает так, как вы ожидаете):
DECLARE @Target_Filegroup sysname = N'XXX';
-----------------------------------------------------------------------------------------
;WITH [IX] AS(
SELECT
[Schema] = SCHEMA_NAME(so.[schema_id]) COLLATE DATABASE_DEFAULT,
[Object_Name] = so.[name] COLLATE DATABASE_DEFAULT,
[Object_Type] = so.[type],
[Is_Published] = so.[is_published],
[Is_Schema_Published] = so.[is_schema_published],
[IX_Name] = ix.[name] COLLATE DATABASE_DEFAULT,
[IX_Type] = ix.[type],
[IX_Type_Desc] = ix.[type_desc] COLLATE DATABASE_DEFAULT,
[Is_PK] = ix.[is_primary_key],
[Is_Unique] = ix.[is_unique],
[IX_Data_Space] = ds.[name] COLLATE DATABASE_DEFAULT,
[Is_UC] = ix.[is_unique_constraint],
[FF] = ix.[fill_factor],
[Is_Padded] = ix.[is_padded],
[Is_Disabled] = ix.[is_disabled],
[Is_Hypothetical] = ix.[is_hypothetical],
[Allow_Row_Locks] = ix.[allow_row_locks],
[Allow_Page_Locks] = ix.[allow_page_locks],
[Has_Filter] = ix.[has_filter],
[Filter] = ix.[filter_definition] COLLATE DATABASE_DEFAULT,
--[auto_created] = ix.[auto_created],
--[optimize_seq_key] = ix.[optimize_for_sequential_key],
[Indexed_Columns] = STUFF(( SELECT [text()] = CONCAT(', ', QUOTENAME(COL_NAME(ic.[object_id],ic.[column_id])))
FROM sys.index_columns ic
WHERE ic.[object_id] = so.[object_id]
AND ic.[index_id] = ix.[index_id]
AND ic.[is_included_column] = 0
ORDER BY ic.[key_ordinal]
FOR XML PATH('')
), 1, 2, '') COLLATE DATABASE_DEFAULT,
[Indexed_Columns_Order] = STUFF(( SELECT [text()] = CONCAT(', ', QUOTENAME(COL_NAME(ic.[object_id],ic.[column_id])), CASE [is_descending_key] WHEN 1 THEN ' DESC' ELSE ' ASC' END)
FROM sys.index_columns ic
WHERE ic.[object_id] = so.[object_id]
AND ic.[index_id] = ix.[index_id]
AND ic.[is_included_column] = 0
ORDER BY ic.[key_ordinal]
FOR XML PATH('')
), 1, 2, '') COLLATE DATABASE_DEFAULT,
[Included_Columns] = STUFF(( SELECT [text()] = CONCAT(', ', QUOTENAME(COL_NAME(ic.[object_id],ic.[column_id])))
FROM sys.index_columns ic
WHERE ic.[object_id] = so.[object_id]
AND ic.[index_id] = ix.[index_id]
AND ic.[is_included_column] = 1
ORDER BY ic.[key_ordinal]
FOR XML PATH('')
), 1, 2, '') COLLATE DATABASE_DEFAULT
FROM sys.objects so
LEFT JOIN sys.indexes ix ON so.[object_id] = ix.[object_id]
LEFT JOIN sys.data_spaces ds ON ix.[data_space_id] = ds.[data_space_id]
WHERE so.[type] IN ('U', 'V')
AND so.[is_ms_shipped] = 0
AND ix.[type] IS NOT NULL --| so we get heaps, and indexed views
)
SELECT
[Schema], [Object_Name], [Object_Type],
--[Is_Published], [Is_Schema_Published],
[IX_Name],
[IX_Data_Space],
[IX_Move_SQL] = CASE WHEN [IX_Data_Space] <> @Target_Filegroup AND [IX_Type] IN (1,2) THEN CONCAT(
'CREATE ', CASE [Is_Unique] WHEN 1 THEN 'UNIQUE ' END, [IX_Type_Desc], ' INDEX ', QUOTENAME([IX_Name]),
' ON ', QUOTENAME([Schema]), '.', QUOTENAME([Object_Name]), ' (', [Indexed_Columns_Order], ')',
CASE WHEN [Included_Columns] IS NOT NULL THEN CONCAT(' INCLUDE (', [Included_Columns], ')') END,
CASE WHEN [Has_Filter] = 1 THEN CONCAT(' WHERE ', [Filter]) END,
' WITH (PAD_INDEX=', CASE [Is_Padded] WHEN 1 THEN 'ON' ELSE 'OFF' END,
', FILLFACTOR=', CASE WHEN [FF] = 0 THEN '100' ELSE CAST([FF] as varchar(3)) COLLATE DATABASE_DEFAULT END,
', ALLOW_ROW_LOCKS=', CASE [Allow_Row_Locks] WHEN 1 THEN 'ON' ELSE 'OFF' END,
', ALLOW_PAGE_LOCKS=', CASE [Allow_Page_Locks] WHEN 1 THEN 'ON' ELSE 'OFF' END,
', DROP_EXISTING=ON ',')',
' ON ', QUOTENAME(@Target_Filegroup), ';')
END COLLATE DATABASE_DEFAULT
FROM [IX]
ORDER BY [Object_Type] ASC, [Schema] ASC , [Object_Name] ASC;
Я думаю, что эти шаги очень просты и просты для перемещения любой таблицы в другую файловую группу (через Management Studio):
Переместите все некластеризованные индексы в новую файловую группу, просто изменив свойство FileGroup для каждого индекса
Измените свой кластерный индекс на некластерный и просто измените его файловую группу (как в предыдущем шаге)
Добавьте новый временный индекс кластера с "новой файловой группой" с помощью этой команды (или через IDE):
CREATE CLUSTERED INDEX [PK_temp] ON YOURTABLE([Id]) ON NEWFILEGROUP(приведенная выше команда вызывает перемещение всех данных в новую файловую группу)
Удалите вышеуказанный временный PK (когда он делает свою работу префектно!)
Измените свой основной кластерный индекс на кластерный индекс снова (через IDE снова)
Преимущество вышеперечисленных шагов заключается в отсутствии необходимости отбрасывать существующие отношения FK. Также использование IDE предотвращает потерю данных в условиях ошибки.
ПРИМЕЧАНИЕ. Убедитесь, что дисковая квота не включена для вашей файловой группы, или установите ее правильно. В противном случае вы получите исключение "filegroup is full"!