Взаимодействие с прокручиваемым контейнером javascript из python/selenium
Я пытаюсь использовать Selenium/Python для автоматизации загрузки наборов данных с http://factfinder.census.gov/. Я новичок в Javascript, поэтому извиняюсь, если это легко решаемая проблема. Сейчас я работаю над начальной частью кода, и она должна:
- Иди сюда
- Нажмите кнопку "Темы"
- После нажатия "Темы" и загрузки новой страницы нажмите "Набор данных".
- Выберите наборы данных, которые мне нужны, в идеале путем индексации (под) таблицы.
Я застрял на шаге 3. Вот скриншот; Кажется, я хочу получить доступ к div с идентификатором scrollable_container_topics, а затем выполнить итерацию или индексирование, чтобы получить его дочерние узлы (в данном случае я хочу последний дочерний узел). Я пытался использовать script_execute, а затем найти элемент по id, а также по имени класса, но пока ничего не получалось. Буду благодарен за любые указатели.
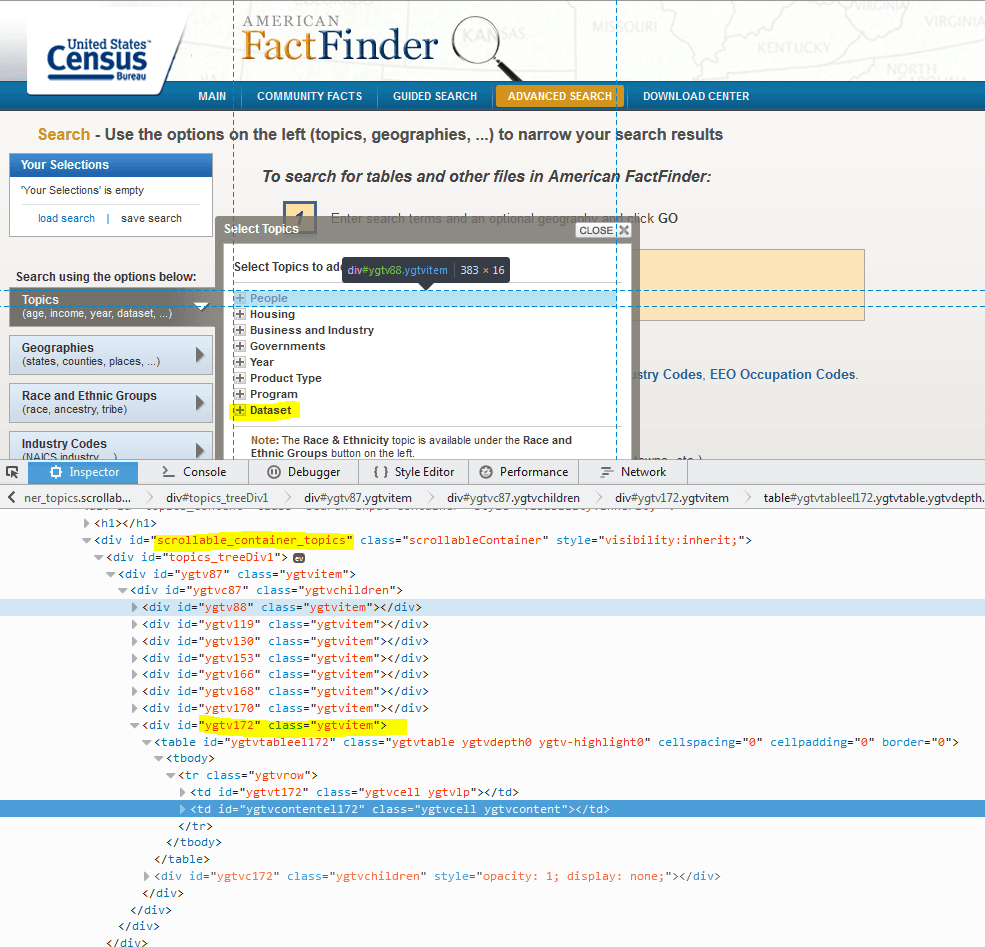
Вот мой код:
import os
import re
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support.select import Select
# A list of all the variables we want to extract; corresponds to "Topics" field on site
topics = ["B03003", "B05001"]
# A list of all the states we want to extract data for (currently, strings; is there a numeric code?)
states = ["New Jersey", "Georgia"]
# A vector of all the years we want to extract data for [lower, upper) *Note* this != range of years covered by data
years = range(2009, 2010)
# Define the class
class CensusSearch:
# Initialize and set attributes of the query
def __init__(self, topic, state, year):
"""
:type topic: str
:type state: str
:type year: int
"""
self.topic = topic
self.state = state
self.year = year
def setUp(self):
# self.driver = webdriver.Chrome("C:/Python34/Scripts/chromedriver.exe")
self.driver = webdriver.Firefox()
def extractData(self):
driver = self.driver
driver.set_page_load_timeout(1000000000000)
driver.implicitly_wait(100)
# Navigate to site; this url = after you have already chosen "Advanced Search"
driver.get("http://factfinder.census.gov/faces/nav/jsf/pages/searchresults.xhtml?refresh=t")
driver.implicitly_wait(10)
# FIlter by dataset (want the ACS 1, 3, and 5-year estimates)
driver.execute_script("document.getElementsByClassName('leftnav_btn')[0].click()") # click the "Topics" button
driver.implicitly_wait(20)
# This is where I am stuck; I've tried the following:
getData = driver.find_element_by_id("ygtvlabelel172")
getData.click()
driver.implicitly_wait(10)
# Filter geographically: select all counties in the United States and Puerto Rico
# Click "Geographies" button
driver.execute_script("document.getElementsByClassName('leftnav_btn')[1].click()")
driver.implicitly_wait(10)
drop_down = driver.find_element_by_class_name("popular_summarylevel")
select_box = Select(drop_down)
select_box.select_by_value("050")
# Once "Geography" is clicked, select "County - 050" from the drop-down menu; then select "All US + Puerto Rico"
drop_down_counties = driver.find_element_by_id("geoAssistList")
select_box_counties = Select(drop_down_counties)
select_box_counties.select_by_index(1)
# Click the "ADD TO YOUR SELECTIONS" button
driver.execute_script("document.getElementsByClassName('button-g')[0].click()")
driver.implicitly_wait(10)
def tearDown(self):
self.driver.quit()
def main(self):
#print(getattr(self))
print(self.state)
print(self.topic)
print(self.year)
self.setUp()
self.extractData()
self.tearDown()
for a in topics:
for b in states:
for c in years:
query = CensusSearch(a, b, c)
query.main()
print("done")
1 ответ
Несколько вещей для исправления:
- вам не нужно использовать
document.getElement..методы - у селена есть свои собственные методы для поиска элементов на странице - нет необходимости манипулировать неявными ожиданиями (плюс, убедитесь, что вы понимаете, что вызов
implicitly_wait()не будет вести себя какtime.sleep()- в этом случае вы не получите немедленную задержку) или тайм-ауты загрузки страницы - просто используйте явные ожидания перед выполнением действий на странице
Вот рабочий код, который нажимает "Темы", а затем "Набор данных":
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://factfinder.census.gov/faces/nav/jsf/pages/searchresults.xhtml?refresh=t")
wait = WebDriverWait(driver, 10)
actions = ActionChains(driver)
# click "Topics"
topics = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "a#topic-overlay-btn")))
driver.execute_script("arguments[0].click();", topics)
# click "Dataset"
dataset = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "span[title=Dataset]")))
dataset.click()