Генерация нескольких последовательных графиков / диаграмм рассеяния из данных в двух информационных фреймах
У меня есть 2 кадра данных, Tg и Pf, каждый из 127 столбцов. Все столбцы имеют хотя бы одну строку и могут содержать до тысячи. Все значения находятся в диапазоне от 0 до 1, и есть некоторые пропущенные значения (пустые ячейки). Вот небольшое подмножество:
Tg
Tg1 Tg2 Tg3 ... Tg127
0.9 0.5 0.4 0
0.9 0.3 0.6 0
0.4 0.6 0.6 0.3
0.1 0.7 0.6 0.4
0.1 0.8
0.3 0.9
0.9
0.6
0.1
Pf
Pf1 Pf2 Pf3 ...Pf127
0.9 0.5 0.4 1
0.9 0.3 0.6 0.8
0.6 0.6 0.6 0.7
0.4 0.7 0.6 0.5
0.1 0.6 0.5
0.3
0.3
0.3
Обратите внимание, что некоторые ячейки пусты, и длины вектора для одного и того же подмножества (т.е. от 1 до 127) могут иметь очень разную длину и редко иметь одинаковую точную длину. Я хочу сгенерировать 127 графиков следующим образом для 127 векторов (то есть график для столбца 1 для каждого кадра данных, график 2 для столбца 2 для каждого кадра данных и т. Д.):
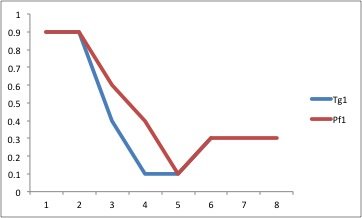
Надеюсь, что это имеет смысл. Я с нетерпением жду вашей помощи, поскольку я не хочу делать эти графики один за другим... Спасибо!
3 ответа
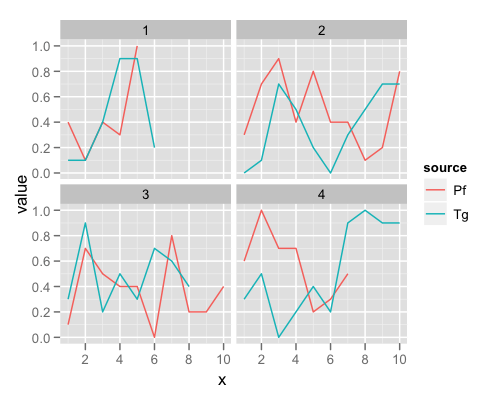
Вот пример для начала (данные на https://gist.github.com/1349300). Для дальнейшей настройки, проверьте отличные ggplot2 документация, которая есть по всей сети.
library(ggplot2)
# Load data
Tg = read.table('Tg.txt', header=T, fill=T, sep=' ')
Pf = read.table('Pf.txt', header=T, fill=T, sep=' ')
# Format data
Tg$x = as.numeric(rownames(Tg))
Tg = melt(Tg, id.vars='x')
Tg$source = 'Tg'
Tg$variable = factor(as.numeric(gsub('Tg(.+)', '\\1', Tg$variable)))
Pf$x = as.numeric(rownames(Pf))
Pf = melt(Pf, id.vars='x')
Pf$source = 'Pf'
Pf$variable = factor(as.numeric(gsub('Pf(.+)', '\\1', Pf$variable)))
# Stack data
data = rbind(Tg, Pf)
# Plot
dev.new(width=5, height=4)
p = ggplot(data=data, aes(x=x)) + geom_line(aes(y=value, group=source, color=source)) + facet_wrap(~variable)
p
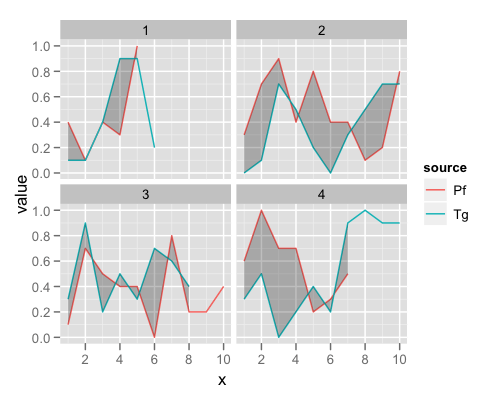
Подсветка области между строк
Сначала интерполируйте данные на более мелкую сетку. Таким образом, лента будет следовать фактическому огибающему линий, а не только тому, где были расположены исходные точки данных.
data = ddply(data, c('variable', 'source'), function(x) data.frame(approx(x$x, x$value, xout=seq(min(x$x), max(x$x), length.out=100))))
names(data)[4] = 'value'
Далее рассчитайте данные, необходимые для geom_ribbon а именно ymax а также ymin,
ribbon.data = ddply(data, c('variable', 'x'), summarize, ymin=min(value), ymax=max(value))
Теперь пришло время для заговора. Обратите внимание, как мы добавили новый слой ленты, для которого мы заменили наш новый ribbon.data Рамка.
dev.new(width=5, height=4)
p + geom_ribbon(aes(ymin=ymin, ymax=ymax), alpha=0.3, data=ribbon.data)
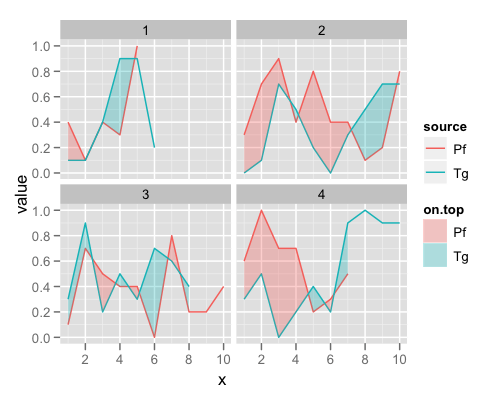
Динамическая раскраска между линиями
Самый хитрый вариант - если вы хотите, чтобы окраска менялась в зависимости от данных. Для этого вам необходимо создать новую переменную группировки, чтобы идентифицировать различные сегменты. Здесь, например, мы могли бы использовать функцию, которая указывает, когда группа "Tg" находится сверху:
GetSegs <- function(x) {
segs = x[x$source=='Tg', ]$value > x[x$source=='Pf', ]$value
segs.rle = rle(segs)
on.top = ifelse(segs, 'Tg', 'Pf')
on.top[is.na(on.top)] = 'Tg'
group = rep.int(1:length(segs.rle$lengths), times=segs.rle$lengths)
group[is.na(segs)] = NA
data.frame(x=unique(x$x), group, on.top)
}
Теперь мы применяем его и объединяем результаты с нашими исходными данными ленты.
groups = ddply(data, 'variable', GetSegs)
ribbon.data = join(ribbon.data, groups)
Для графика ключевым моментом является то, что мы теперь указываем эстетику группировки для геома ленты.
dev.new(width=5, height=4)
p + geom_ribbon(aes(ymin=ymin, ymax=ymax, group=group, fill=on.top), alpha=0.3, data=ribbon.data)
Код доступен вместе по адресу: https://gist.github.com/1349300
Вот три лайнера, чтобы сделать то же самое:-). Мы первые reshape от base преобразовать данные в длинную форму. Затем он расплавляется, чтобы удовлетворить ggplot2, Наконец, мы генерируем сюжет!
mydf <- reshape(cbind(Tg, Pf), varying = 1:8, direction = 'long', sep = "")
mydf_m <- melt(mydf, id.var = c(1, 4), variable = 'source')
qplot(id, value, colour = source, data = mydf_m, geom = 'line') +
facet_wrap(~ time, ncol = 2)
НОТА. reshape функция в base R очень мощный, хотя и очень запутанный в использовании. Он используется для преобразования данных между long а также wide форматы.
Престижность для автоматизации того, что вы делали в Excel, используя R! Именно так я и начал с R и общего пути к R просветлению:)
Все, что вам действительно нужно, это немного зацикливаться. Вот пример, большинство из которых создает пример данных, которые представляют вашу структуру данных:
## create some example data
Tg <- data.frame(Tg1 = rnorm(10))
for (i in 2:10) {
vec <- rep(NA, 8)
vec <- c(rnorm(sample(5:10,1)), vec)
Tg[paste("Tg", i, sep="")] <- vec[1:10]
}
Pf <- data.frame(Pf1 = rnorm(10))
for (i in 2:10) {
vec <- rep(NA, 8)
vec <- c(rnorm(sample(5:10,1)), vec)
Pf[paste("Pf", i, sep="")] <- vec[1:10]
}
## ok, sample data created
## now lets loop through all the columns
## if you didn't know how many columns there are you could
## use ncol(Tg) to figure out
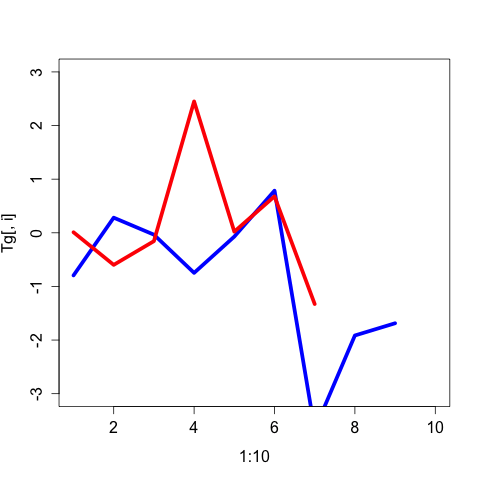
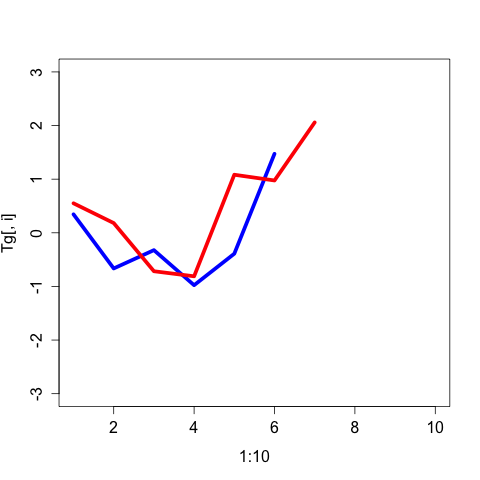
for (i in 1:10) {
plot(1:10, Tg[,i], type = "l", col="blue", lwd=5, ylim=c(-3,3),
xlim=c(1, max(length(na.omit(Tg[,i])), length(na.omit(Pf[,i])))))
lines(1:10, Pf[,i], type = "l", col="red", lwd=5, ylim=c(-3,3))
dev.copy(png, paste('rplot', i, '.png', sep=""))
dev.off()
}
Это приведет к 10 графам в вашем рабочем каталоге, которые выглядят следующим образом: