Заголовки не извлекаются из PDF при извлечении данных таблицы из PDF с помощью camelot
Я использую Camelot для извлечения данных таблицы, однако заголовок не извлекается как часть PDF.
Прикрепленная ниже целевая PDF-ссылка и целевая таблица находятся на страницах № 3 и 4, которые нужно извлечь.
https://drive.google.com/file/d/1xniTIwpnNIdA_k4xvEARlVH97Lk-K2Yr/view?usp=sharing
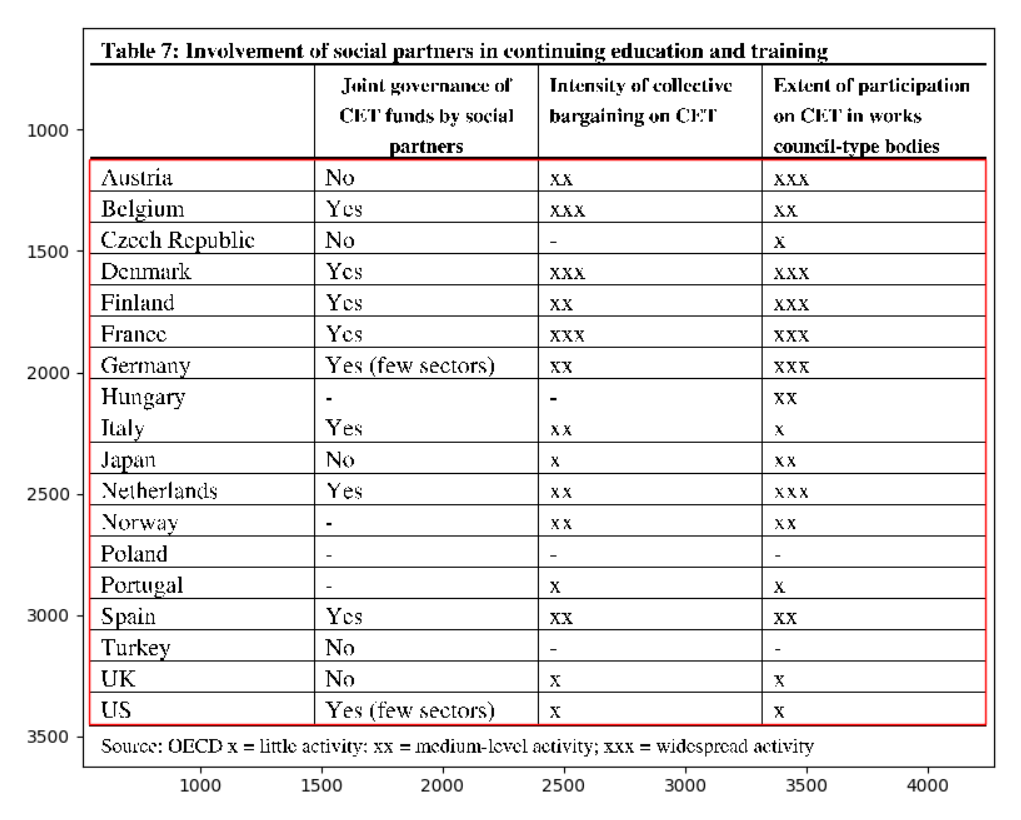
Одна из таблиц выглядит ниже 
Я видел документацию Camelot и думаю, что проблема связана с "Обнаружение коротких линий".
https://camelot-py.readthedocs.io/en/master/user/advanced.html
Однако не удалось решить проблему путем настройки параметра line_size_scaling.
Пожалуйста помогите.
1 ответ
Я построил обнаруженную границу таблицы на странице 3, используя $ camelot -p 3 lattice -plot contour 007.pdf, Похоже, что Camelot не включает строку заголовка в обнаруженную границу таблицы [ошибка 1] (см. Изображение ниже). Затем я попытался с помощью table_areas аргумент с ключевым словом flavor='lattice' но тогда он не включал строки в указанную границу таблицы [ошибка 2]. Я добавил их в систему отслеживания проблем как #200 и # 201.
Вы все еще можете использовать table_areas аргумент с ключевым словом flavor='stream' чтобы получить стол.
Используя CLI: $ camelot -p 3 --output 007.csv --format csv stream -T 60,770,520,400 007.pdf
Используя API: tables = camelot.read_pdf('007.pdf', pages='3', flavor='stream', table_areas=['60,770,520,400'])
Вы можете найти координаты границы таблицы, используя шаги, описанные здесь: https://camelot-py.readthedocs.io/en/master/user/advanced.html
Надеюсь, это поможет!