Доступ к данным в куче быстрее, чем из стека?
Я знаю, что это звучит как общий вопрос, и я видел много похожих вопросов (как здесь, так и в Интернете), но ни один из них не похож на мою дилемму.
Скажи, у меня есть этот код:
void GetSomeData(char* buffer)
{
// put some data in buffer
}
int main()
{
char buffer[1024];
while(1)
{
GetSomeData(buffer);
// do something with the data
}
return 0;
}
Получу ли я какую-либо производительность, если я объявлю буфер [1024] глобально?
Я провел несколько тестов на Unix с помощью команды time, и различий во времени выполнения практически нет.
Но я не совсем уверен...
В теории это изменение должно иметь значение?
5 ответов
Доступ к данным в куче быстрее, чем из стека?
Не по своей природе... в каждой архитектуре, над которой я когда-либо работал, можно ожидать, что весь процесс "память" будет работать с одинаковым набором скоростей, в зависимости от того, какой уровень файла кэша ЦП / ОЗУ / файла подкачки содержит текущие данные и любая синхронизация на уровне оборудования задерживает то, что операции с этой памятью могут запускаться, чтобы сделать ее видимой для других процессов, включать изменения других процессов / ЦП (ядра) и т. д.
Операционная система (которая отвечает за сбой / подкачку страниц) и аппаратное (ЦП) прерывание доступа к выгруженным или еще не полученным страницам даже не будут отслеживать, какие страницы являются "стеками" по сравнению с "кучей"... страница памяти - это страница памяти. Тем не менее, виртуальный адрес глобальных данных может быть рассчитан и жестко закодирован во время компиляции, адреса стековых данных, как правило, относятся к указателю стека, в то время как память в куче почти всегда должна быть доступна с помощью указателей, которые могут быть немного медленнее в некоторых системах - это зависит от режимов и циклов адресации процессора, но это почти всегда незначительно - даже не стоит взглянуть или подумать, если вы не пишете что-то, где миллионные доли секунды чрезвычайно важны.
В любом случае, в вашем примере вы сравниваете глобальную переменную с локальной (стековая / автоматическая) функциональной переменной... в этом нет кучи. Куча памяти исходит от new или же malloc/realloc, Что касается динамической памяти, следует отметить, что проблема производительности заключается в том, что само приложение отслеживает, сколько памяти используется по каким адресам - записи всего, что занимает некоторое время для обновления, поскольку указатели на память выдаются new/malloc/reallocи еще немного времени для обновления, так как указатели deleteд или freeд.
Для глобальных переменных выделение памяти может эффективно выполняться во время компиляции, в то время как для переменных на основе стека обычно есть указатель стека, который увеличивается каждый раз на вычисляемую во время компиляции сумму размеров локальных переменных (и некоторых служебных данных) каждый раз функция называется. Так когда main() Вызывается, что может быть какое-то время, чтобы изменить указатель стека, но он, вероятно, просто изменяется на другую величину, а не изменяется, если нет buffer и модифицируется, если есть, поэтому нет никакой разницы в производительности во время выполнения.
Цитирую ответ Джеффа Хилла:
Стек быстрее, потому что шаблон доступа делает его тривиальным для выделения и освобождения памяти из него (указатель / целое число просто увеличивается или уменьшается), в то время как куча имеет гораздо более сложную бухгалтерию, вовлеченную в выделение или освобождение. Кроме того, каждый байт в стеке имеет тенденцию использоваться очень часто, что означает, что он имеет тенденцию отображаться в кэш процессора, что делает его очень быстрым. Другим ударом производительности для кучи является то, что куча, являющаяся главным образом глобальным ресурсом, как правило, должна быть многопоточной безопасной, то есть каждое распределение и освобождение должно быть - как правило - синхронизировано со "всеми" другими обращениями к куче в программе.
По этой теме доступно сообщение в блоге: https://publicwork.wordpress.com/2019/06/27/stack-allocation-vs-heap-allocation-performance-benchmark/ котором показан тест стратегии распределения. Тест написан на C и выполняет сравнение между попытками чистого распределения и распределением с инициализацией памяти. При разном общем объеме данных выполняется количество циклов и измеряется время. Каждое распределение состоит из 10 различных блоков alloc/init/free с разными размерами (общий размер показан в диаграммах).
Тесты выполняются на процессоре Intel(R) Core(TM) i7-6600U, Linux 64 bit, 4.15.0-50-generic, патчи Spectre и Meltdown отключены.
Без инициализации:
Внутри:
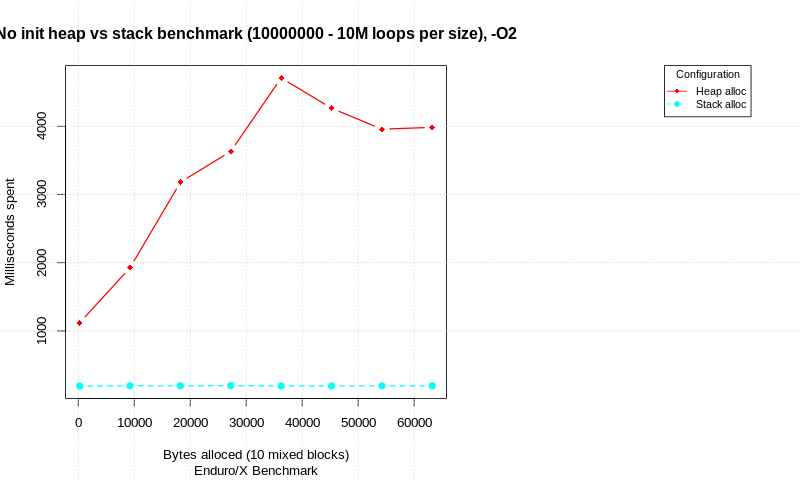
В результате мы видим, что существует значительная разница в чистом распределении без инициализации данных. Стек быстрее, чем куча, но учтите, что количество циклов очень велико.
Когда выделенные данные обрабатываются, кажется, что разница между производительностью стека и кучи уменьшается. При 1M циклах malloc/init/free (или распределении стека) с 10 попытками выделения в каждом цикле стек всего на 8% опережает кучу с точки зрения общего времени.
Что бы это ни стоило, цикл в приведенном ниже коде - который просто читает и записывает каждый элемент в большом массиве - последовательно работает на моей машине в 5 раз быстрее, когда массив находится в стеке, а не в куче (GCC, Windows 10, флаг -O3), даже сразу после перезагрузки (когда фрагментация кучи минимизирована):
const int size = 100100100;
int vals[size]; // STACK
// int *vals = new int[size]; // HEAP
startTimer();
for (int i = 1; i < size; ++i) {
vals[i] = vals[i - 1];
}
stopTimer();
std::cout << vals[size - 1];
// delete[] vals; // HEAP
Конечно, сначала мне пришлось увеличить размер стека до 400 МБ. Обратите внимание, что печать последнего элемента в конце необходима, чтобы компилятор не оптимизировал все.
Ваш вопрос на самом деле не имеет ответа; это зависит от того, что еще вы делаете. Вообще говоря, большинство машин используют одну и ту же структуру "памяти" во всем процессе, поэтому независимо от того, где находится переменная (куча, стек или глобальная память), время доступа будет одинаковым. С другой стороны, большинство современных машин имеют иерархическую структуру памяти с конвейером памяти, несколькими уровнями кэша, основной памяти и виртуальной памяти. В зависимости от того, что ранее было на процессоре, фактический доступ может быть к любому из них (независимо от того, является ли он кучей, стеком или глобальным), и время доступа здесь сильно варьируется, от одного такта, если память в нужном месте в конвейере, примерно до 10 миллисекунд, если система должна перейти в виртуальную память на диске.
Во всех случаях ключом является местность. Если доступ "близок" к предыдущему, вы значительно повышаете вероятность его нахождения в одном из самых быстрых мест: например, в кеше. В этом отношении размещение меньших объектов в стеке может быть быстрее, потому что при доступе к аргументам функции вы получаете доступ к памяти стека (по крайней мере, с 32-разрядным процессором Intel - с процессорами с лучшим дизайном, аргументы, скорее всего, будут в регистрах). Но это, вероятно, не будет проблемой, когда задействован массив.
При распределении буферов по стеку область оптимизации заключается не в стоимости доступа к памяти, а скорее в устранении зачастую очень дорогого динамического выделения памяти в куче (выделение буфера стека можно считать мгновенным, поскольку стек в целом выделяется при запуске потока),
Задавать, что переменные и массивы переменных, которые объявлены в куче, медленнее, это просто факт. Подумайте об этом таким образом;
Глобально созданные переменные распределяются один раз и освобождаются после закрытия программы. Для объекта кучи ваша переменная должна быть размещена на месте каждый раз, когда функция запускается, и освобождается в конце функции.
Вы когда-нибудь пытались выделить указатель на объект внутри функции? Что ж, лучше освободить / удалить его до выхода из функции, иначе у вас возникнет утечка памяти, что означает, что вы не делаете это в объекте класса, где он был бы свободен / удален внутри деконструктора.
Когда дело доходит до доступа к массиву, все они работают одинаково, блок памяти сначала выделяется элементами sizeof(DataType) *. Позже можно получить доступ ->
1 2 3 4 5 6
^ entry point [0]
^ entry point [0]+3