Повысить дух карма реальная производительность генератора
Я проверял работоспособность генератора бодрости духа, когда был несколько удивлен снижением производительности при использовании политики для реальных чисел. Жить на Колиру
Код был взят из Boost Spirit и была добавлена пара тестовых функций. Пример Coliru заменяет используемый таймер. Обратите внимание, что Coliru прерывает длительно работающие проги, поэтому может не завершить все тесты.
Как можно видеть, использование политики снижает производительность в 2-3 раза (в 10 раз). Это ожидаемое поведение?
Мои цифры:
Спринт: 0.367
Iostreams: 0,818
формат: 1.036
карма: 0,087
(строка): 0,152
карма (строка) с политикой: 0,396
карма (правило): 0,12
карма (прямая): 0,083
Строка кармы (прямая): 0,089
Строка кармы (прямая) с политикой: 0,278
Построен с x64 VC14
1 ответ
Это не регресс, если сравнивать яблоки и груши. В этом случае дважды.
Первая пара яблоко / груша
Вот fixed это яблоки, и scientific это груши.
Мало того, что результирующий результат явно отличается, но и для его получения результат требует различных шагов.
важно scientific включает в себя принятие log10 из входных значений, чтобы установить величину числа в десятизначных цифрах перед десятичной точкой:
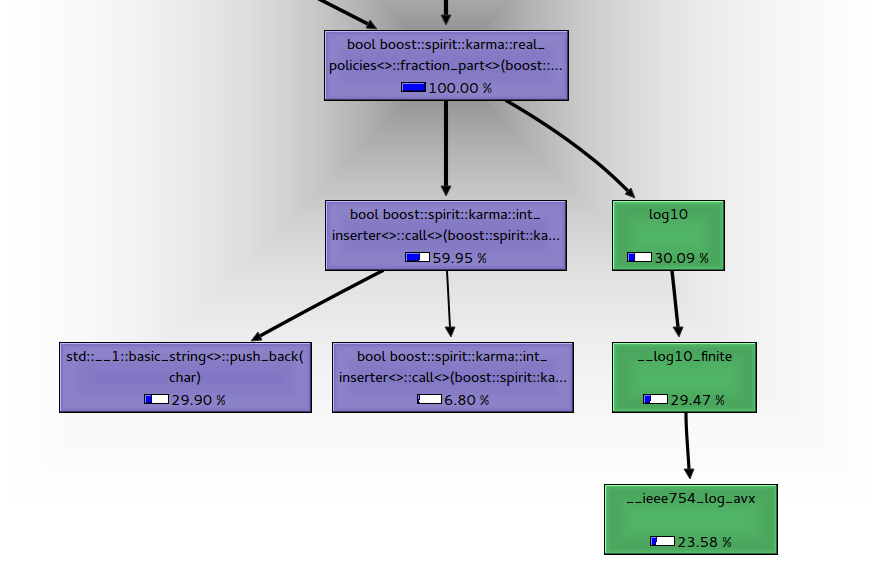
По умолчанию real_policies вызывает "дешевый" вердикт:
static int floatfield(T n)
{
if (traits::test_zero(n))
return fmtflags::fixed;
T abs_n = traits::get_absolute_value(n);
return (abs_n >= 1e5 || abs_n < 1e-3)
? fmtflags::scientific : fmtflags::fixed;
}
Таким образом, вы можете наблюдать, как разница исчезает, если вы выбираете формат, который в любом случае переключится на научный: 123456.123456 вместо 12345.12345...:
clock resolution: mean is 16.9199 ns (40960002 iterations)
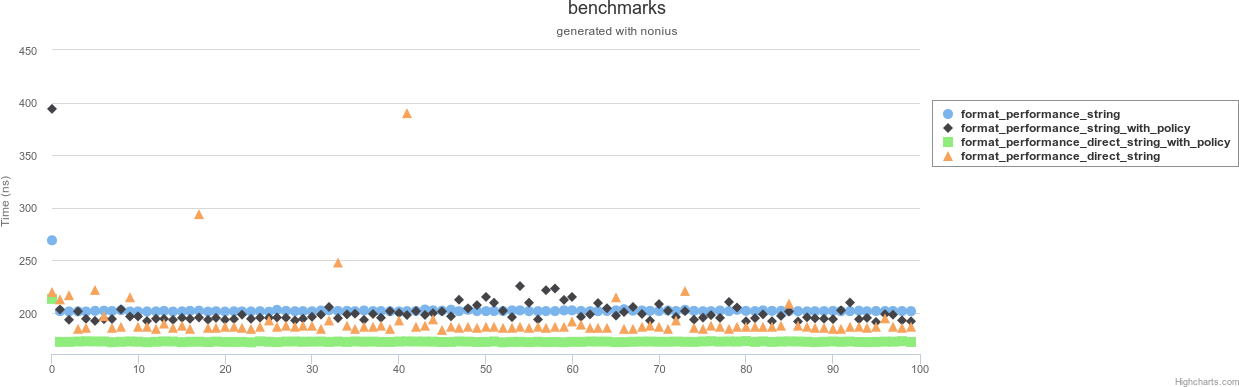
benchmarking format_performance_direct_string
collecting 100 samples, 1 iterations each, in estimated 4.7784 ms
mean: 238.81 ns, lb 187.22 ns, ub 493.46 ns, ci 0.95
std dev: 507.559 ns, lb 5.36317 ns, ub 1111.94 ns, ci 0.95
found 11 outliers among 100 samples (11%)
variance is severely inflated by outliers
benchmarking format_performance_direct_string_with_policy
collecting 100 samples, 96 iterations each, in estimated 1699.2 μs
mean: 173.927 ns, lb 172.764 ns, ub 176.939 ns, ci 0.95
std dev: 8.33706 ns, lb 0.256875 ns, ub 16.9312 ns, ci 0.95
found 2 outliers among 100 samples (2%)
variance is moderately inflated by outliers
benchmarking format_performance_string
collecting 100 samples, 84 iterations each, in estimated 1705.2 μs
mean: 312.646 ns, lb 311.027 ns, ub 314.819 ns, ci 0.95
std dev: 9.42479 ns, lb 7.32668 ns, ub 15.2546 ns, ci 0.95
found 1 outliers among 100 samples (1%)
variance is moderately inflated by outliers
benchmarking format_performance_string_with_policy
collecting 100 samples, 31 iterations each, in estimated 1736 μs
mean: 193.572 ns, lb 192.257 ns, ub 200.032 ns, ci 0.95
std dev: 12.8586 ns, lb 0.322008 ns, ub 30.6708 ns, ci 0.95
found 4 outliers among 100 samples (4%)
variance is severely inflated by outliers
Как видите, пользовательская политика (предсказуема) намного быстрее
Как интерактивная ссылка:
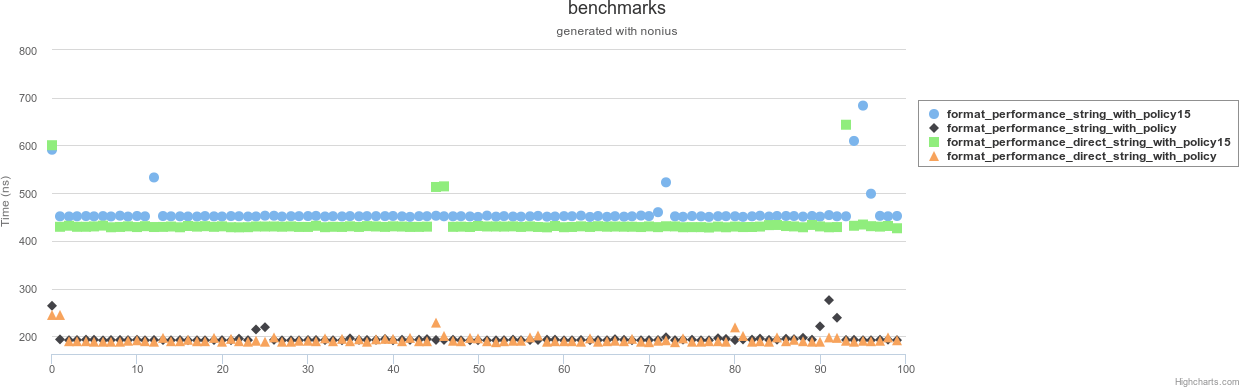
Вторая пара яблок / груш
Это происходит, когда вы закрепили точность до 15 цифр.
Используя отдельный эталонный тест двух политик, который дополнительно обеспечивает точность: http://paste.ubuntu.com/13087371/ вы можете увидеть, что это больше, чем потеря преимущества от фиксации формата в scientific видно выше:
clock resolution: mean is 18.6041 ns (40960002 iterations)
benchmarking format_performance_direct_string_with_policy
collecting 100 samples, 1 iterations each, in estimated 1892.9 μs
mean: 228.83 ns, lb 179.9 ns, ub 471.84 ns, ci 0.95
std dev: 483.67 ns, lb 2.29965 ns, ub 1153.98 ns, ci 0.95
found 14 outliers among 100 samples (14%)
variance is severely inflated by outliers
benchmarking format_performance_direct_string_with_policy15
collecting 100 samples, 45 iterations each, in estimated 1858.5 μs
mean: 418.697 ns, lb 410.976 ns, ub 438.865 ns, ci 0.95
std dev: 58.0984 ns, lb 24.1313 ns, ub 115.549 ns, ci 0.95
found 6 outliers among 100 samples (6%)
variance is severely inflated by outliers
benchmarking format_performance_string_with_policy
collecting 100 samples, 87 iterations each, in estimated 1870.5 μs
mean: 262.057 ns, lb 254.73 ns, ub 269.354 ns, ci 0.95
std dev: 37.2502 ns, lb 31.1261 ns, ub 50.5813 ns, ci 0.95
found 17 outliers among 100 samples (17%)
variance is severely inflated by outliers
benchmarking format_performance_string_with_policy15
collecting 100 samples, 42 iterations each, in estimated 1898.4 μs
mean: 458.505 ns, lb 453.626 ns, ub 481.044 ns, ci 0.95
std dev: 45.5401 ns, lb 4.30147 ns, ub 108.045 ns, ci 0.95
found 4 outliers among 100 samples (4%)
variance is severely inflated by outliers
Или на графике: Интерактивная ссылка