Эта функция для одновременного получения минимального и максимального значений быстрее, чем использование минимального и максимального значений отдельно?
У меня есть функция для одновременного получения минимальных и максимальных значений списка:
def min_max(iterable, key=None):
"""Retrieve the min and max values of `iterable` simultaneously."""
if key is None: key = lambda x: x
if not iterable:
return None, None
min_ = max_ = key(iterable[0])
for i in iterable[1:]:
if key(i) > key(max_): max_ = i
if key(i) < key(min_): min_ = i
return min_, max_
Но это заставило меня задуматься, так как в любом случае я делаю два сравнения в цикле for, не будет ли быстрее просто использовать min а также max по отдельности? Если это так, как я могу отредактировать эту функцию, чтобы сделать ее более эффективной?
4 ответа
Дорогая часть в определении минимального или максимального значения в списке - это не сравнение. Сравнение значений довольно быстрое, и здесь проблем не будет. Вместо этого, что влияет на время выполнения, так это цикл.
Когда вы используете min() или же max()затем каждый из них должен будет выполнить итерацию один раз. Они делают это отдельно, поэтому, когда вам нужно минимальное и максимальное значение, используя встроенные функции, вы выполняете итерацию дважды.
Ваша функция просто перебирает один раз, поэтому ее теоретическое время выполнения короче. Теперь, как упомянуто в комментариях, min а также max реализованы в собственном коде, поэтому они, безусловно, быстрее, чем при его реализации в коде Python самостоятельно.
Теперь от вашей итерации зависит, будут ли два нативных цикла работать быстрее, чем ваша функция Python. Для более длинных списков, где повторение уже дорого, повторное его повторение определенно будет лучше, но для более коротких вы, вероятно, получите лучшие результаты с нативным кодом. Я не могу сказать, где находится точный порог, но вы можете легко проверить ваши фактические данные, что быстрее. Однако в большинстве случаев это редко имеет значение, так как мин / макс не будет узким местом вашего приложения, поэтому вам не следует беспокоиться об этом, пока это не станет проблемой.
Btw. ваша реализация имеет несколько проблем прямо сейчас, которые вы должны исправить, если хотите использовать:
- Это требует
iterableбыть последовательностью, а не повторяемой (так как вы используете для нее индексы) - Вы также требуете, чтобы он имел по крайней мере один предмет - который технически не требуется. Пока вы проверяете
not iterable, это не обязательно скажет вам что-то о длине последовательности / повторяемой. Пользовательские типы могут легко предоставлять свое собственное логическое значение и / или поведение последовательности. - Наконец, вы инициализируете
_minа также_maxс ключевыми значениями повторяемого элемента, но позже вы (правильно) просто назначаете исходный элемент из повторяемого элемента.
Поэтому я бы предложил вам использовать вместо этого итераторы и исправить эту ключевую вещь - вы также можете сохранить ключевые результаты, чтобы сохранить некоторые вычисления для более сложных ключевых функций:
it = iter(iterable)
try:
min_ = max_ = next(it)
minv = maxv = key(min_)
except StopIteration:
return None, None
for i in it:
k = key(i)
if k > maxv:
max_, maxv = i, k
elif k < minv:
min_, minv = i, k
Я провел некоторое тестирование по этому вопросу, и оказалось, что - без пользовательской функции клавиш - использование встроенного параметра max/min практически невозможно. Даже для очень больших списков реализация purce C слишком быстра. Однако, как только вы добавите ключевую функцию (которая написана в коде Python), ситуация полностью изменится. С помощью ключевой функции вы получаете практически одинаковый результат синхронизации для одного min или же max вызов как для полной функции, выполняющей оба. Таким образом, использование решения, написанного на Python, намного быстрее.
Так что это привело к мысли, что, возможно, реализация в Python не была реальной проблемой, но вместо этого key функция, которая используется. И действительно, именно ключевая функция делает реализацию Python дорогой. И это тоже имеет большой смысл. Даже с тождественной лямбой у вас все еще остаются накладные расходы на вызовы функций; len(iterable) много вызовов функций (с моим оптимизированным вариантом выше). И вызовы функций довольно дороги.
В моих тестах с отключенной поддержкой ключевой функции были получены действительно ожидаемые результаты: повторение только один раз быстрее, чем вдвое. Но для не очень больших итераций разница действительно мала. Так что, если итерация итерируемая очень дорогая (хотя вы могли бы затем использовать tee и по-прежнему повторять дважды), или вы все равно хотите зациклить его (в этом случае вы бы объединили это с проверкой мин / макс), используя встроенный max() а также min() функции отдельно будут быстрее, а также намного проще в использовании. И они оба идут с внутренней оптимизацией, что они пропускают ключевые функции, если вы не укажете одну из них.
И наконец, как вы можете добавить эту ключевую функцию оптимизации в свой код? Ну, к сожалению, есть только один способ сделать это - дублирование кода. По сути, вы должны проверить, указана ли ключевая функция, и пропустить вызов функции, когда ее нет. Итак, как то так:
def min_max(iterable, key=None):
if key:
# do it with a key function
else:
# do it without
TL;DR
Если ввод представляет собой массив NumPy, см . .
Если вход представляет собой последовательность:
- и, как правило, быстрее, чем ручной цикл (если только не используется параметр, а затем это зависит от того, насколько быстро выполняется вызов функции)
- ручное выполнение циклов можно ускорить с помощью Python, при этом производительность превосходит два отдельных вызова и .
Если вход не является итерируемым последовательностью:
- и не может использоваться для одного и того же итерируемого
- iterable необходимо привести к или (или можно было бы использовать , но, согласно его документации , / кастинг в этом случае быстрее), но имеет большой объем памяти
- можно использовать подход с одним циклом, который снова можно ускорить с помощью Cython.
Случай с явным здесь подробно не рассматривается, но эффективная адаптация одного из эффективных подходов, который может быть Cython-изирован, описана ниже:
def extrema_for_with_key(items, key=None):
items = iter(items)
if callable(key):
try:
max_item = min_item = next(items)
max_val = min_val = key(item)
except StopIteration:
return None, None
else:
for item in items:
val = key(item)
if val > max_val:
max_val = val
max_item = item
elif val < min_val:
min_val = val
min_item = item
return max_item, min_item
else:
try:
max_item = min_item = next(items)
except StopIteration:
return None, None
else:
for item in items:
if item > max_item:
max_item = item
elif item < min_item:
min_item = item
return max_item, min_item
Полный бенчмарк .
Более длинный ответ
Хотя зацикливание в чистом Python может быть вашим узким местом, тем не менее верно то, что проблема нахождения как максимума, так и минимума может быть решена с помощью значительно меньшего количества шагов (меньше сравнений и меньше присваиваний), чем два отдельных вызова и -- на случайной основе. распределенная последовательность значений, а точнее, путем обхода последовательности (или итерации) только один раз. Это может быть полезно при использовании функций, обеспечиваемых использованием параметра, или когда входные данные являются итератором и преобразуются в
tuple()или же
list()(или используя
itertools.tee()) приведет к чрезмерному потреблению памяти. Кроме того, такие подходы могут привести к более быстрому выполнению, если есть возможность ускорить зацикливание через Cython или Numba. Если входные данные не являются массивом NumPy, ускорение Cython будет наиболее эффективным, а если входными данными является массив NumPy, то ускорение Numba приведет к наибольшему ускорению. Как правило, стоимость преобразования универсального ввода в массив NumPy не компенсируется увеличением скорости использования Numba. Обсуждение для случая массивов NumPy можно найти здесьздесь.
Базовая реализация, игнорирующая
keyпараметр, следующий (где
min_loops()а также
max_loops()по сути являются повторной реализацией с помощью циклов
min()а также
max()):
def min_loops(seq):
iseq = iter(seq) # ensure iterator
try:
result = next(iseq)
except StopIteration:
return None
else:
for item in iseq:
if item < result:
result = item
return result
def max_loops(seq):
iseq = iter(seq) # ensure iterator
try:
result = next(iseq)
except StopIteration:
return None
else:
for item in iseq:
if item > result:
result = item
return result
def extrema_loops(items):
seq = tuple(items) # required if items is actually an iterable
return max_loops(seq), min_loops(seq)
Их можно наивно объединить в один цикл, аналогично предложению ОП:
def extrema_for(seq):
iseq = iter(seq)
try:
max_val = min_val = next(iseq)
except StopIteration:
return None, None
else:
for item in iseq:
if item > max_val:
max_val = item
elif item < min_val: # <-- reduces comparisons
min_val = item
return max_val, min_val
где использование
elifэффективно снижает количество сравнений (и присвоений) «в среднем» (на входах со случайно распределенными значениями) до 1,5 на элемент.
Количество присвоений можно еще уменьшить, рассматривая два элемента «сразу» (количество сравнений в среднем 1,5 на элемент в обоих случаях):
def extrema_for2(seq):
iseq = iter(seq)
try:
max_val = min_val = next(iseq)
except StopIteration:
return None, None
else:
for x, y in zip(iseq, iseq):
if x > y: # reduces assignments
x, y = y, x
if x < min_val:
min_val = x
if y > max_val:
max_val = y
try:
last = next(iseq)
except StopIteration:
pass
else:
if last < min_val:
min_val = x
if last > max_val:
max_val = y
return max_val, min_val
относительная скорость каждого метода сильно зависит от относительной скорости каждой инструкции, и альтернативные реализации могут быть быстрее. Например, если основной цикл (
for x, y in zip(iseq, iseq)) заменяется на
while True: x = next(iseq); y = next(iseq)построить, то есть:
def extrema_while(seq):
iseq = iter(seq)
try:
max_val = min_val = x = next(iseq)
try:
while True:
x = next(iseq)
y = next(iseq)
if x > y:
x, y = y, x
if x < min_val:
min_val = x
if y > max_val:
max_val = y
except StopIteration:
if x < min_val:
min_val = x
if x > max_val:
max_val = x
return max_val, min_val
except StopIteration:
return None, None
это оказывается медленнее в Python, НО быстрее с ускорением Cython.
Эти и следующие реализации в качестве базовых:
def extrema(seq):
return max(seq), min(seq)
def extrema_iter(items):
seq = tuple(items)
return max(seq), min(seq)
сравниваются ниже:
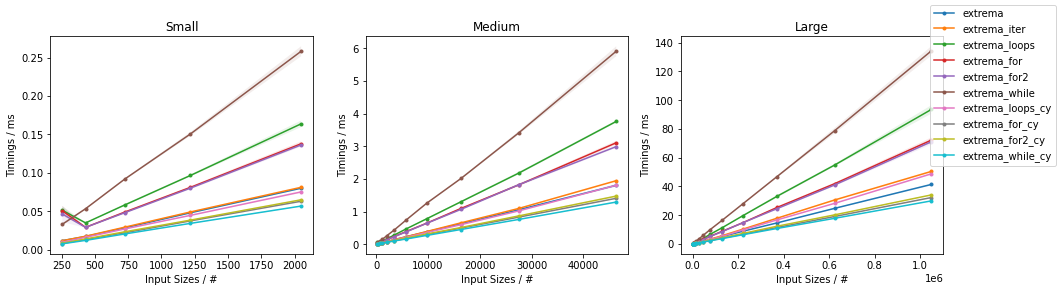
Обратите внимание, что в целом:
-
extrema_while()>extrema_loops()>extrema_for()>extrema_for2()(это связано с дорогими звонками наnext()) - >
extrema_for_cy()>extrema_for2_cy()>extrema_while_cy() -
extrema_loops_cy()на самом деле медленнее, чемextrema().
Функции имеют контрпаты Cython (с
_cyсуффикс) и по сути являются одним и тем же кодом, за исключением
defзаменено на
cpdef, например:
%%cython -c-O3 -c-march=native -a
#cython: language_level=3, boundscheck=False, wraparound=False, initializedcheck=False, cdivision=True, infer_types=True
cpdef extrema_while_cy(seq):
items = iter(seq)
try:
max_val = min_val = x = next(items)
try:
while True:
x = next(items)
y = next(items)
if x > y:
x, y = y, x
if x < min_val:
min_val = x
if y > max_val:
max_val = y
except StopIteration:
if x < min_val:
min_val = x
if x > max_val:
max_val = x
return max_val, min_val
except StopIteration:
return None, None
Полный бенчмарк здесьздесь.
Пожалуйста, проверьте здесь:
Это не совсем то, что вы ищете, но я могу уменьшить цикл:
def min_max(iterable):
if not iterable:
raise Exception('Required iterable object')
_min = _max = iterable[0]
ind = 0
if len(iterable) & 1:
ind = 1
for elm in iterable[1::2]:
ind += 2
try:
if iterable[ind] < iterable[ind + 1]:
if _min > iterable[ind]:
_min = iterable[ind]
if _max < iterable[ind + 1]:
_max = iterable[ind + 1]
else:
if _min > iterable[ind + 1]:
_min = iterable[ind + 1]
if _max < iterable[ind]:
_max = iterable[ind]
except:
pass
return _min, _max
print min_max([11,2,3,5,0,1000,14,5,100,1,999])
Выход:
(0, 1000)
Используйте этот код:
for i in iterable[1:]:
if key(i) > key(max_):
max_ = i
elif key(i) < key(min_):
min_ = i