Абстрактное синтаксическое построение и обход дерева
Мне неясно, как устроены деревья абстрактного синтаксиса. Чтобы перейти "вниз (вперед)" в исходном тексте программы, которую представляет AST, вы идете прямо на самый верхний узел или идете вниз? Например, будет ли пример программы
a = 1
b = 2
c = 3
d = 4
e = 5
Результат в AST, который выглядит так: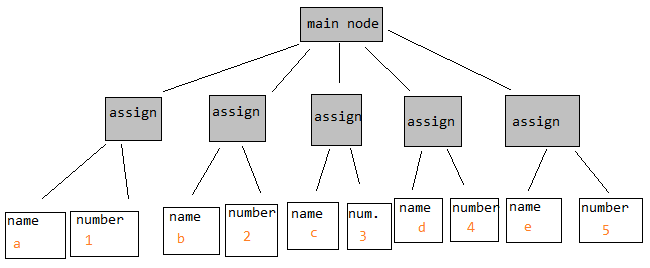
или это: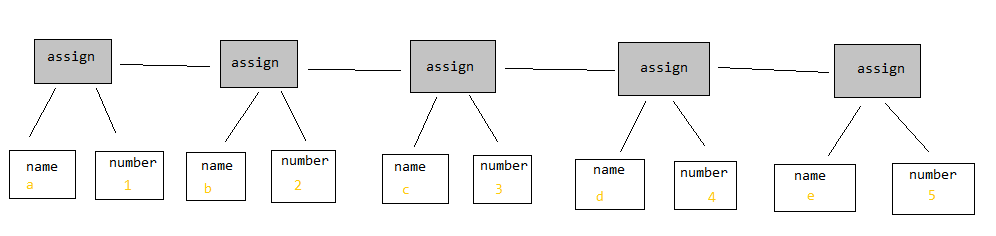
Где в первом, иду "правильно" на main node будет продвигать вас через программу, но во втором просто следуя next указатель на каждый узел будет делать то же самое.
Кажется, что второй вариант был бы более правильным, поскольку вам не нужно что-то вроде специального типа узла с потенциально очень длинным массивом указателей для самого первого узла. Хотя я вижу, что второй становится более сложным, чем первый, когда вы попадаете в for петли и if ветки и более сложные вещи.
5 ответов
Первое представление является более типичным, хотя второе совместимо с построением дерева в качестве рекурсивной структуры данных, что может использоваться, когда платформа реализации является функциональной, а не императивной.
Рассматривать:
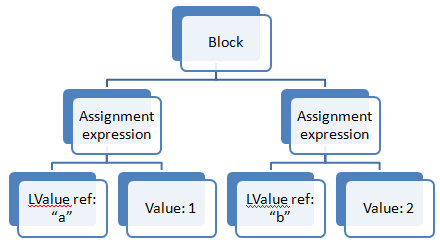
Это ваш первый пример, за исключением сокращенного и с "основным" узлом (концептуальным соломенным человеком), более подходящим образом названным "блоком", чтобы отразить общую конструкцию "блока", содержащего последовательность операторов в императивном языке программирования. Разные виды узлов имеют разные виды дочерних элементов, и иногда эти дочерние элементы включают наборы вспомогательных узлов, порядок которых важен, как в случае с "блоком". То же самое может произойти, скажем, при инициализации массива:
int[] arr = {1, 2}
Рассмотрим, как это может быть представлено в синтаксическом дереве:

Здесь узел типа "массив-литерал" также имеет несколько дочерних элементов одного типа, порядок которых важен.
Если в первом случае движение "вправо" на главном узле будет продвигать вас по программе, то во втором простое следование по следующему указателю на каждом узле сделает то же самое.
Кажется, что второй вариант был бы более правильным, так как вам не нужно что-то вроде специального типа узла с потенциально очень длинным массивом указателей для самого первого узла.
Я почти всегда предпочитаю первый подход, и я думаю, что вам будет гораздо проще построить свой AST, когда вам не нужно поддерживать указатель на следующий узел.
Я думаю, что в целом проще сделать так, чтобы все объекты происходили из общего базового класса, подобного этому:
abstract class Expr { }
class Block : Expr
{
Expr[] Statements { get; set; }
public Block(Expr[] statements) { ... }
}
class Assign : Expr
{
Var Variable { get; set; }
Expr Expression { get; set; }
public Assign(Var variable, Expr expression) { ... }
}
class Var : Expr
{
string Name { get; set; }
public Variable(string name) { ... }
}
class Int : Expr
{
int Value { get; set; }
public Int(int value) { ... }
}
В результате AST выглядит следующим образом:
Expr program =
new Block(new Expr[]
{
new Assign(new Var("a"), new Int(1)),
new Assign(new Var("b"), new Int(2)),
new Assign(new Var("c"), new Int(3)),
new Assign(new Var("d"), new Int(4)),
new Assign(new Var("e"), new Int(5)),
});
Я считаю, что ваша первая версия имеет больше смысла по нескольким причинам.
Во-первых, первая более четко демонстрирует "вложенность" программы, а также четко реализована в виде корневого дерева (что является обычной концепцией дерева).
Вторая, и более важная причина, заключается в том, что ваш "главный узел" мог действительно быть "узлом ветвления" (например), который может быть просто другим узлом в пределах большего AST. Таким образом, ваш AST можно рассматривать в рекурсивном смысле, где каждый AST является узлом с другими AST в качестве дочерних. Это делает дизайн первого намного более простым, более общим и очень однородным.
Это зависит от языка. В C вам придется использовать первую форму, чтобы захватить понятие блока, так как блок имеет переменную область видимости:
{
{
int a = 1;
}
// a doesn't exist here
}
Переменная область будет атрибутом того, что вы называете "основным узлом".
Предложение: При работе с древовидными структурами данных, является ли AST связанным с компилятором или другим видом, всегда используйте один "корневой" узел, это может помочь вам выполнять операции и иметь больший контроль:
class ASTTreeNode {
bool isRoot() {...}
string display() { ... }
// ...
}
void main ()
{
ASTTreeNode MyRoot = new ASTTreeNode();
// ...
// prints the root node, plus each subnode recursively
MyRoot.Show();
}
Приветствия.