Почему мне нужно экранировать Unicode в исходных файлах Java?
Обратите внимание, что я не спрашиваю, как, но почему. И я не знаю, является ли это конкретной проблемой для RCP, или это что-то присуще Java.
Мои исходные файлы Java закодированы в UTF-8.
Если я определю свои буквальные строки следующим образом:
new Language("fr", "Français"),
new Language("zh", "中文")
Он работает так, как я ожидаю, когда я использую строку в приложении, запуская ее из Eclipse как приложение Eclipse:
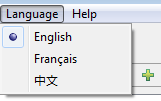
Но если происходит сбой при запуске.exe, созданного "Мастером экспорта продуктов Eclipse":

Решение, которое я использую, состоит в том, чтобы избежать символов следующим образом:
new Language("fr", "Fran\u00e7ais"), // Français
new Language("zh", "\u4e2d\u6587") // 中文
В этом нет никаких проблем (все мои другие строки находятся в файлах свойств, только названия языков жестко запрограммированы), но я хотел бы понять.
Я думал, что компилятор должен был преобразовывать строки Java-букв при построении байт-кода. Так почему же нужен экранирование Юникода? Это неправильно использовать высокоуровневые символы Юникода в исходных файлах Java? Что происходит именно с этими символами при компиляции и чем это отличается от обработки экранированных символов? Проблема только связана с кешем RCP?
2 ответа
Похоже, что мастер экспорта продуктов Eclipse не интерпретирует ваши файлы как UTF-8. Возможно, вам нужно запустить JVM Eclipse с кодировкой UTF-8 (-Dfile.encoding=UTF8 в eclipse.ini)?
(Copypasta'd по запросу ОП)
При экспорте плагина он компилируется через процесс, отдельный от обычного процесса сборки в среде IDE. Существует известная ошибка, что процесс сборки (PDE.Build) игнорирует кодировку текста, используемую IDE.
Экспорт можно заставить работать должным образом, указав кодировку текста в файле build.properties вашего плагина
javacDefaultEncoding.. =UTF-8