Насколько медленна конкатенация строк в Python против str.join?
В результате комментариев в моем ответе на эту тему я хотел узнать, какая разница в скорости между += оператор и ''.join()
Так каково сравнение скорости между ними?
8 ответов
От: Эффективная конкатенация строк
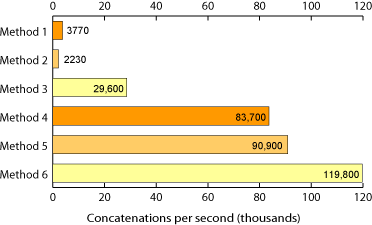
Способ 1:
def method1():
out_str = ''
for num in xrange(loop_count):
out_str += 'num'
return out_str
Способ 4:
def method4():
str_list = []
for num in xrange(loop_count):
str_list.append('num')
return ''.join(str_list)
Теперь я понимаю, что они не являются строго репрезентативными, и 4-й метод добавляется в список перед повторением и присоединением к каждому элементу, но это справедливое указание.
Соединение строк значительно быстрее, чем конкатенация.
Зачем? Строки являются неизменяемыми и не могут быть изменены на месте. Чтобы изменить один, необходимо создать новое представление (объединение двух).
Мой оригинальный код был неправильным, кажется, что + конкатенация обычно быстрее (особенно с новыми версиями Python на новом оборудовании)
Время выглядит следующим образом:
Iterations: 1,000,000
Python 3.3 на Windows 7, Core i7
String of len: 1 took: 0.5710 0.2880 seconds
String of len: 4 took: 0.9480 0.5830 seconds
String of len: 6 took: 1.2770 0.8130 seconds
String of len: 12 took: 2.0610 1.5930 seconds
String of len: 80 took: 10.5140 37.8590 seconds
String of len: 222 took: 27.3400 134.7440 seconds
String of len: 443 took: 52.9640 170.6440 seconds
Python 2.7 на Windows 7, Core i7
String of len: 1 took: 0.7190 0.4960 seconds
String of len: 4 took: 1.0660 0.6920 seconds
String of len: 6 took: 1.3300 0.8560 seconds
String of len: 12 took: 1.9980 1.5330 seconds
String of len: 80 took: 9.0520 25.7190 seconds
String of len: 222 took: 23.1620 71.3620 seconds
String of len: 443 took: 44.3620 117.1510 seconds
В Linux Mint, Python 2.7, более медленный процессор
String of len: 1 took: 1.8840 1.2990 seconds
String of len: 4 took: 2.8394 1.9663 seconds
String of len: 6 took: 3.5177 2.4162 seconds
String of len: 12 took: 5.5456 4.1695 seconds
String of len: 80 took: 27.8813 19.2180 seconds
String of len: 222 took: 69.5679 55.7790 seconds
String of len: 443 took: 135.6101 153.8212 seconds
И вот код:
from __future__ import print_function
import time
def strcat(string):
newstr = ''
for char in string:
newstr += char
return newstr
def listcat(string):
chars = []
for char in string:
chars.append(char)
return ''.join(chars)
def test(fn, times, *args):
start = time.time()
for x in range(times):
fn(*args)
return "{:>10.4f}".format(time.time() - start)
def testall():
strings = ['a', 'long', 'longer', 'a bit longer',
'''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''',
'''this is a really long string that's so long
it had to be triple quoted and contains lots of
superflous characters for kicks and gigles
@!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''',
'''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.''']
for string in strings:
print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")
testall()
Существующие ответы очень хорошо написаны и исследованы, но вот еще один ответ для эры Python 3.6, так как теперь у нас есть интерполяция буквенных строк (AKA, f-струны):
>>> import timeit
>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)
0.14618930302094668
>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)
0.23334730707574636
>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)
0.14985873899422586
Тест проводился с использованием CPython 3.6.5 на Retina MacBook Pro 2012 года с процессором Intel Core i7 с частотой 2,3 ГГц.
Это ни в коем случае не формальный тест, но похоже, что f-strings примерно такой же производительный, как использование += конкатенация; Любые улучшенные метрики или предложения, конечно, приветствуются.
Если я ожидаю хорошо, для списка с k строками, всего с n символами, временная сложность соединения должна быть O(nlogk), а временная сложность классической конкатенации должна быть O(nk).
Это будут те же относительные затраты, что и объединение k отсортированного списка (эффективный метод - O (nlkg), а простой, похожий на конкатенацию, - O (nk)).
Если я скажу это алгоритмически , если вы выберете [ += ], то он сгенерирует новый объект, и это будет O(n)**2. Но если вы используете [ .join ], то это будет O(n).
Посмотрите этот удивительный пост о конкатенации и соединении с полным примером.https://developerstacks.com/post/how-slow-is-pythons-string-concatenation-vs-join/
Я переписал последний ответ, не могли бы вы поделиться своим мнением о том, как я тестировал?
import time
start1 = time.clock()
for x in range (10000000):
dog1 = ' and '.join(['spam', 'eggs', 'spam', 'spam', 'eggs', 'spam','spam', 'eggs', 'spam', 'spam', 'eggs', 'spam'])
end1 = time.clock()
print("Time to run Joiner = ", end1 - start1, "seconds")
start2 = time.clock()
for x in range (10000000):
dog2 = 'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'
end2 = time.clock()
print("Time to run + = ", end2 - start2, "seconds")
ПРИМЕЧАНИЕ: этот пример написан на Python 3.5, где range() действует как прежний xrange()
Выход я получил:
Time to run Joiner = 27.086106206103153 seconds
Time to run + = 69.79100515996426 seconds
Лично я предпочитаю '.join([]) над'Plusser way', потому что он чище и более читабелен.
Это то, что глупые программы предназначены для тестирования:)
Используйте плюс
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a" + "b"
end = time.clock()
print "Time to run Plusser = ", end - start, "seconds"
Выход:
Time to run Plusser = 1.16350010965 seconds
Теперь с присоединением....
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a".join("b")
end = time.clock()
print "Time to run Joiner = ", end - start, "seconds"
Выход из:
Time to run Joiner = 21.3877386651 seconds
Так что на python 2.6 на windows я бы сказал + примерно в 18 раз быстрее, чем join:)