Как я могу построить интегральную функцию распределения (CDF) для связанных данных?
У меня есть дискретные данные, которые я представил в диапазонах, например
Marks Freq cumFreq
1 (37.9,43.1] 4 4
2 (43.1,48.2] 16 20
3 (48.2,53.3] 76 96
мне нужно построить CMF для этих данных, я знаю, что есть
plot(ecdf(x))
но я не знаю, что добавить, чтобы иметь то, что мне нужно.
1 ответ
Вот несколько вариантов:
library(ggplot2)
library(scales)
library(dplyr)
## Fake data
set.seed(2)
dat = data.frame(score=c(rnorm(130,40,10), rnorm(130,80,5)))
Вот как построить ECDF, если у вас есть необработанные данные:
# Base graphics
plot(ecdf(dat$score))
# ggplot2
ggplot(dat, aes(score)) +
stat_ecdf(aes(group=1), geom="step")
Вот один из способов построить ECDF, если у вас есть только сводные данные:
Во-первых, давайте сгруппируем данные в бункеры, аналогично тому, что у вас есть в вашем вопросе. Мы используем cut функция для создания бункеров, а затем создать новый pct столбец для расчета каждой ячейки доли от общего количества баллов. Мы используем dplyr оператор цепочки (%>%) сделать все это в одной "цепочке" функций.
dat.binned = dat %>% count(Marks=cut(score,seq(0,100,5))) %>%
mutate(pct = n/sum(n))
Теперь мы можем построить это. cumsum(pct) рассчитывает совокупный процент (как cumFreq в твоем вопросе). geom_step создает пошаговый график с этими совокупными процентами.
ggplot(dat.binned, aes(Marks, cumsum(pct))) +
geom_step(aes(group=1)) +
scale_y_continuous(labels=percent_format())
Вот как выглядят графики:



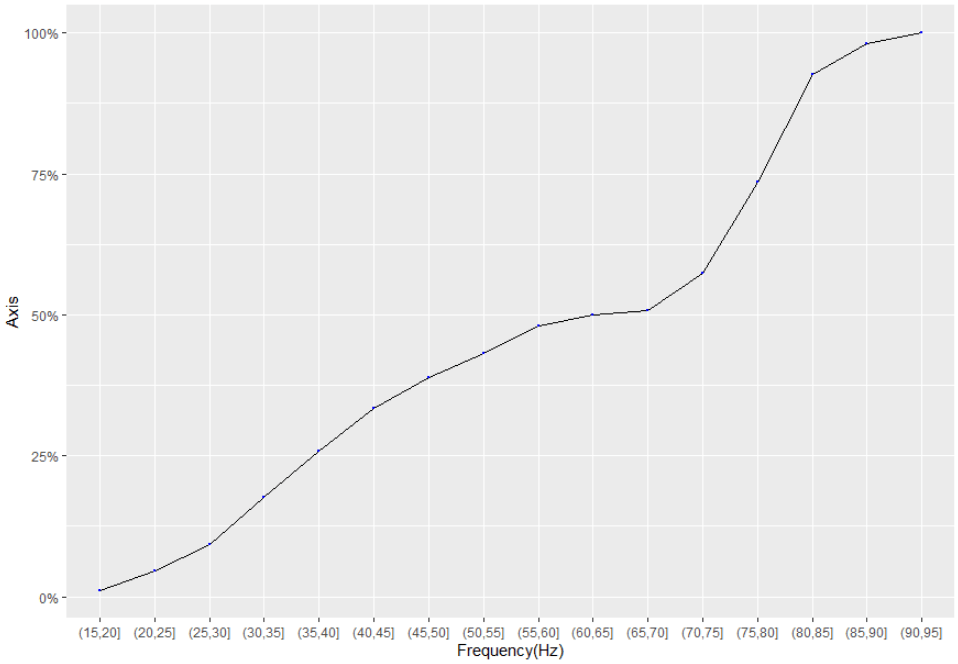
Как насчет этого:
library(ggplot2)
library(scales)
library(dplyr)
set.seed(2)
dat = data.frame(score = c(rnorm(130,40,10), rnorm(130,80,5)))
dat.binned = dat %>% count(Marks = cut(score,seq(0,100,5))) %>%
mutate(pct = n/sum(n))
ggplot(data = dat.binned, mapping = aes(Marks, cumsum(pct))) +
geom_line(aes(group = 1)) +
geom_point(data = dat.binned, size = 0.1, color = "blue") +
labs(x = "Frequency(Hz)", y = "Axis") +
scale_y_continuous(labels = percent_format())