codellama неоднократно генерирует символ новой строки
Я использую Langchain с codellama, используя Llama.cpp. (обнимающее лицо - TheBloke/CodeLlama-34B-Instruct-GPTQ) У меня в устройстве 4 Testla T4. Я установил Llama.cpp с OpenBLAS. Когда я загружаю модель с помощью файла hgguf, я вижу параметр BLAS=1 и вижу использование памяти графического процессора с помощью nvdia-smi, оно увеличивается во время загрузки модели. Когда я пытаюсь сгенерировать коделламу с помощью Llama(), все сгенерировалось хорошо.
Но я пытаюсь использовать PromptTemplate и LLMChain. Это не удается, модель не дает значимых результатов. Она просто генерирует много символов \n в качестве вывода. Я не понимаю, почему. Пока он работает, я мог использовать графический процессор, поэтому он использует мои графические процессоры Tesla.
Я использую токен <>, чтобы предоставить LLM дополнительную информацию.
Мой код выглядит следующим образом:
%set_env TEMPERATURE=0.5
%set_env GPU_LAYERS=100
%set_env MODEL_PATH=../../llm-models/codellama-34b-instruct.Q4_K_M.gguf
%set_env MODEL_N_CTX=4096
%set_env TOP_P=0.95
%set_env TOP_K=40
%set_env THREADS=8
%set_env EMBEDDINGS_MODEL_NAME=all-mpnet-base-v2
from langchain.llms import LlamaCpp
stop = ['Human:', 'Assistant:', 'User:']
llm = LlamaCpp(model_path=model_path,
n_ctx=model_n_ctx,
verbose=True,
n_threads=threads,
n_gpu_layers=gpu_layers,
n_batch=int(model_n_ctx)/8,
stop=stop,
temperature=temperature,
top_p=top_p,
top_k=top_k,
use_mlock=False,
max_tokens=2000,
)
template = f"""<s>[INST] <<SYS>>
{custom_initial_prompt}""" + """
<</SYS>>
problem description:
{text}
code:
{code}[/INST]"""
prompt_template = PromptTemplate(template=template, input_variables=["text", "code"])
chain = LLMChain(llm=llm, prompt=prompt_template, verbose=True)
%%time
result = chain.run(code = script[0].page_content, text = pages[0].page_content)
Результат этой подсказки показан ниже.
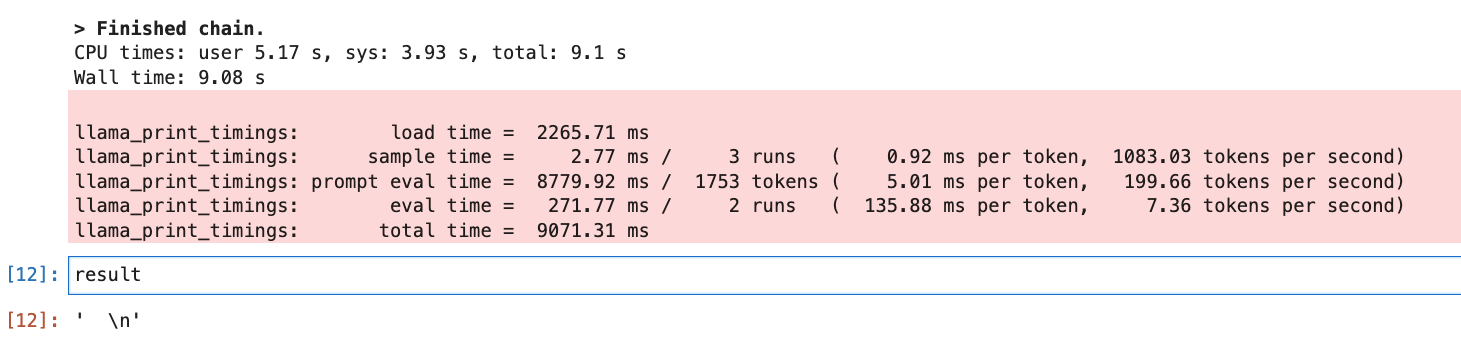
Иногда он генерирует много символов новой строки. Как я могу решить эту проблему ?
Я увеличиваю количество графических процессоров. Я попробовал уменьшенную версию модели коделламы (модель 7B). Я пробовал другую версию cuda. Я попробовал загрузить маленькую модель на свой локальный компьютер, все работает хорошо.