Почему TensorRT enqueueV2 занимает больше времени при использовании более изолированных потоков в C++?
- ОС: Windows 10
- CUDA: версия 11.5
- ТензорРТ: 8.6.1.6
- OpenCV: 4.8.0, созданный с использованием CUDA.
- Версия драйвера: Самый последний драйвер (545.84).
В моем приложении будет транслироваться с нескольких камер. Каждая камера будет управляться одним потоком ЦП, и между этими потоками нет никакого совместного использования. Кроме того, каждый поток будет загружать и использовать модель обнаружения объектов, развернутую с помощью TensorRT. Каждый поток будет иметь свою собственную модель, и модели также не будут общими.
Для двух потоков функция TensorRT enqueuev2, которая выполняет процесс вывода модели, занимает в среднем почти 1 миллисекунду, что кажется довольно многообещающим. Для профилирования программы я использую инструмент NVIDIA Nsight System.
Когда я профилирую программу в системе Nsight, на следующем рисунке показан отчет о профилировании.
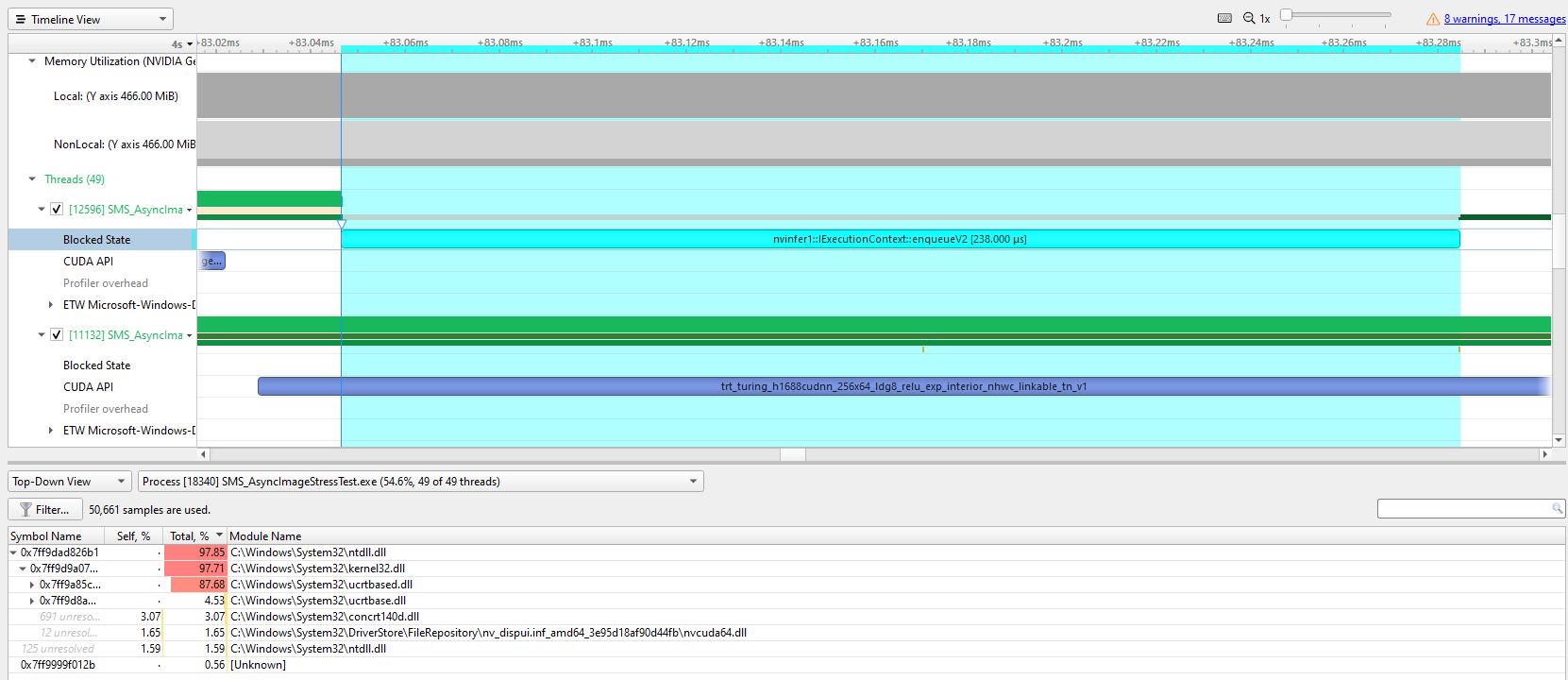
Как показано на изображении выше, для одного из потоков enqueuev2 потребовалось 238 микросекунд, что кажется хорошим показателем для двух потоков.
Для второго теста я запускаю 20 потоков, но на этот раз постановке в очередь TensorRT потребовалось почти 20 миллисекунд, чтобы вернуть результаты, и это значение продолжает расти по мере увеличения количества потоков. Вы можете увидеть отчет Nishgt System на следующем изображении:
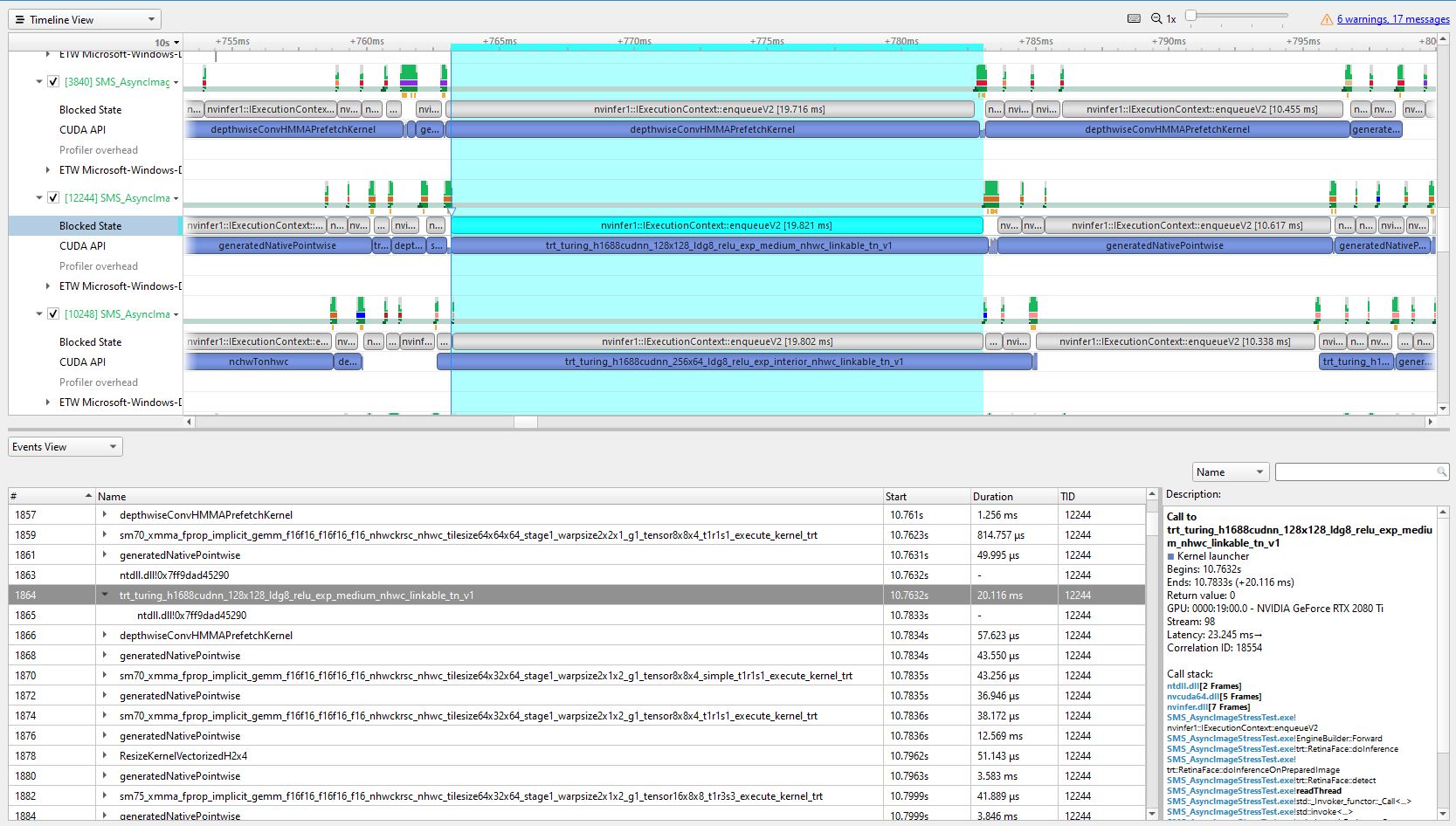
Как показано цветом наклона, enqueuev2 потребовалось 19 миллисекунд, чтобы вернуть результат, который отрицательно влияет на конечный FPS каждого потока.
Я внимательно просмотрел отчеты и увидел некоторые заблокированные состояния, с которыми я не знаком, и думаю, что это узкое место программы, но понятия не имею, как их уменьшить или устранить.
Вот фрагмент кода, который я использовал для процесса вывода:
auto t1 = std::chrono::high_resolution_clock::now();
status = mContext->enqueueV2(&mBindingDataHolder[0], *inferenceCudaStream, nullptr);
CUDA_CHECK(cudaEventRecord(syncEvent, *inferenceCudaStream));
CUDA_CHECK(cudaEventSynchronize(syncEvent));
auto t2 = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
spdlog::info("enqueueV2 time: {} ms", duration);
Поскольку ресурсы и потоки изолированы и ничего не совместно используют, я ожидаю, что функция постановки в очередь для каждого потока займет около 1 миллисекунды, как и в первом случае с двумя потоками, но это в 20 раз медленнее.
Буду признателен, если кто-нибудь скажет мне, являются ли эти заблокированные состояния основной причиной проблемы и если да, то как ее можно решить.