Не могу увидеть выходной файл mapreduce wordcount
Я следовал руководству Майкла Нолса, чтобы загрузить и установить Haddop. Я также запустил пример WordCount. Но я не вижу выхода того же самого. Когда я вижу файлы в DFS, я получаю весь список файлов, которые у меня есть
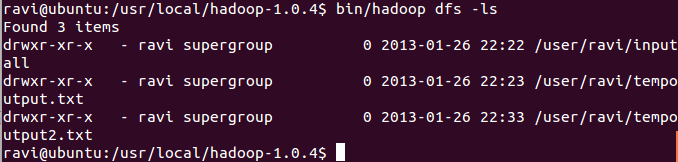
Но когда я котирую эти файлы, я получаю сообщение об ошибке
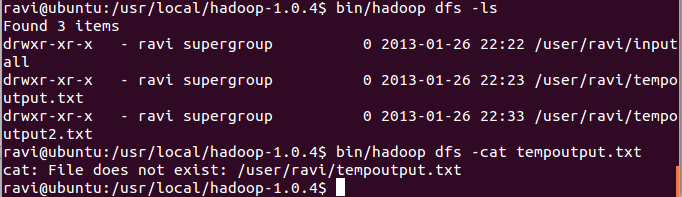
Интересно, что пошло не так там...
2 ответа
Файл в HDFS, который вы пытаетесь перехватить, является каталогом (столбец флагов показывает drwxr-xr-x). Задания Hadoop обычно выводят свой результат в каталог с одним файлом на редуктор (или на маппер, если вы запускаете задание без редукторов).
Итак, содержимое этой папки, вы должны увидеть некоторые файлы part-r - попробуйте эти файлы:
bin/hadoop dfs -cat /user/ravi/tempoutput.txt/part-r-*
Ожидаемый синтаксис для запуска примера wordcount: bin/hadoop jar hadoop-examples-1.0.4.jar wordcount <input_dir> <output_dir>, Вполне возможно, что ваш WordCount не обработал какие-либо данные, и поэтому вы не можете увидеть результаты. Попробуйте запустить bin/hadoop jar hadoop-examples-1.0.4.jar wordcount /user/ravi/inputall /user/ravi/output с последующим bin/hadoop dfs -ls /user/ravi/output чтобы увидеть результаты.
Кроме того, вы должны проверить детали карты, чтобы уменьшить выполнение работы после ее запуска (либо непосредственно в консоли, либо через веб-интерфейс). Должна быть подробная информация о количестве обработанных входных записей / байтов. Вы также можете просмотреть всю файловую систему в своем веб-браузере: http://localhost:50070/dfshealth.jsp