OpenMP худшая производительность с большим количеством потоков (после уроков openMP)
Я начинаю работать с OpenMP и следую этим урокам:
Я кодирую именно то, что появляется на видео, но вместо лучшей производительности с большим количеством потоков мне становится хуже. Я не понимаю почему.
Вот мой код:
#include <iostream>
#include <time.h>
#include <omp.h>
using namespace std;
static long num_steps = 100000000;
double step;
#define NUM_THREADS 2
int main()
{
clock_t t;
t = clock();
int i, nthreads; double pi, sum[NUM_THREADS];
step = 1.0/(double)num_steps;
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel
{
int i, id, nthrds;
double x;
id = omp_get_thread_num();
nthrds = omp_get_num_threads();
if(id == 0) nthreads = nthrds;
for(i=id, sum[id]=0.0; i < num_steps; i = i + nthrds)
{
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i = 0, pi=0.0; i<nthreads; i++) pi += sum[i] * step;
t = clock() - t;
cout << "time: " << t << " miliseconds" << endl;
}
Как вы можете видеть, это точно так же, как в видео, я только добавил код для измерения прошедшего времени.
В учебнике, чем больше потоков мы используем, тем лучше производительность.
В моем случае этого не происходит. Вот время, которое я получил:
1 thread: 433590 miliseconds
2 threads: 1705704 miliseconds
3 threads: 2689001 miliseconds
4 threads: 4221881 miliseconds
Почему я получаю такое поведение?
-- РЕДАКТИРОВАТЬ --
версия gcc: gcc 5.5.0
результат lscpu:
Architechure: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 60
Model name: Intel(R) Core(TM) i7-4720HQ CPU @ 2.60Ghz
Stepping: 3
CPU Mhz: 2594.436
CPU max MHz: 3600,0000
CPU min Mhz: 800,0000
BogoMIPS: 5188.41
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 6144K
NUMA node0 CPU(s): 0-7
-- РЕДАКТИРОВАТЬ --
Я пытался использовать omp_get_wtime() вместо этого, вот так:
#include <iostream>
#include <time.h>
#include <omp.h>
using namespace std;
static long num_steps = 100000000;
double step;
#define NUM_THREADS 8
int main()
{
int i, nthreads; double pi, sum[NUM_THREADS];
step = 1.0/(double)num_steps;
double start_time = omp_get_wtime();
omp_set_num_threads(NUM_THREADS);
#pragma omp parallel
{
int i, id, nthrds;
double x;
id = omp_get_thread_num();
nthrds = omp_get_num_threads();
if(id == 0) nthreads = nthrds;
for(i=id, sum[id]=0.0; i < num_steps; i = i + nthrds)
{
x = (i+0.5)*step;
sum[id] += 4.0/(1.0+x*x);
}
}
for(i = 0, pi=0.0; i<nthreads; i++) pi += sum[i] * step;
double time = omp_get_wtime() - start_time;
cout << "time: " << time << " seconds" << endl;
}
Поведение другое, хотя у меня есть несколько вопросов.
Теперь, если я увеличу количество потоков на 1, например, 1 поток, 2 потока, 3, 4, ..., результаты будут в основном такими же, как и в предыдущем случае, производительность ухудшится, хотя, если я увеличу до 64 потоков или 128 потоков я получаю действительно лучшую производительность, время уменьшается от 0.44 [s] (для 1 потока), чтобы 0.13 [s] (для 128 потоков).
Мой вопрос: почему у меня не такое поведение, как в учебнике?
2 потока получают лучшую производительность, чем 1,
3 потока получают лучшую производительность, чем 2 и т. Д.
Почему я получаю только лучшую производительность с гораздо большим количеством потоков?
2 ответа
вместо лучшего выступления с большим количеством потоков я становлюсь хуже... я не понимаю почему.
Что ж,
давайте сделаем тестирование более систематическим и повторяемым
чтобы увидеть, если:
// time: 1535120 milliseconds 1 thread
// time: 200679 milliseconds 1 thread -O2
// time: 191205 milliseconds 1 thread -O3
// time: 184502 milliseconds 2 threads -O3
// time: 189947 milliseconds 3 threads -O3
// time: 202277 milliseconds 4 threads -O3
// time: 182628 milliseconds 5 threads -O3
// time: 192032 milliseconds 6 threads -O3
// time: 185771 milliseconds 7 threads -O3
// time: 187606 milliseconds 16 threads -O3
// time: 187231 milliseconds 32 threads -O3
// time: 186131 milliseconds 64 threads -O3
Это действительно показывает больше эффектов { -O2 |-O3 } - эффекты оптимизации режима компиляции, чем предложенная выше основная деградация для растущего числа потоков.
Затем идет "фоновый" шум от неуправляемой экосистемы выполнения кода, где O/S легко искажает упрощенный сравнительный анализ производительности
Если вы действительно заинтересованы в более подробной информации, не стесняйтесь читать о Законе убывающей отдачи (о реальных композициях [SERIAL] соответственно [PARALLEL] части процесса планирования), где д-р Джин AMDAHL инициировал основные правила, 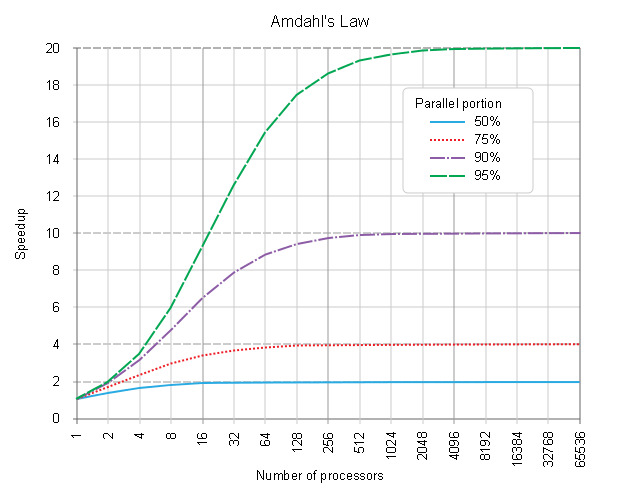 почему большее количество потоков не может получить более высокую производительность (и где более современная переформулировка этого закона объясняет, почему большее количество потоков может даже получить отрицательное улучшение (более дорогие дополнительные издержки), чем правильно настроенная пиковая производительность.
почему большее количество потоков не может получить более высокую производительность (и где более современная переформулировка этого закона объясняет, почему большее количество потоков может даже получить отрицательное улучшение (более дорогие дополнительные издержки), чем правильно настроенная пиковая производительность.
#include <time.h>
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
static long num_steps = 100000000;
double step;
#define NUM_THREADS 7
int main()
{
clock_t t;
t = clock();
int i, nthreads; double pi, sum[NUM_THREADS];
step = 1.0 / ( double )num_steps;
omp_set_num_threads( NUM_THREADS );
// struct timespec start;
// t = clock(); // _________________________________________ BEST START HERE
// clock_gettime( CLOCK_MONOTONIC, &start ); // ____________ USING MONOTONIC CLOCK
#pragma omp parallel
{
int i,
nthrds = omp_get_num_threads(),
id = omp_get_thread_num();;
double x;
if ( id == 0 ) nthreads = nthrds;
for ( i = id, sum[id] = 0.0;
i < num_steps;
i += nthrds
)
{
x = ( i + 0.5 ) * step;
sum[id] += 4.0 / ( 1.0 + x * x );
}
}
// t = clock() - t; // _____________________________________ BEST STOP HERE
// clock_gettime( CLOCK_MONOTONIC, &end ); // ______________ USING MONOTONIC CLOCK
for ( i = 0, pi = 0.0;
i < nthreads;
i++
) pi += sum[i] * step;
t = clock() - t;
// // time: 1535120 milliseconds 1 thread
// // time: 200679 milliseconds 1 thread -O2
// // time: 191205 milliseconds 1 thread -O3
printf( "time: %d milliseconds %d threads\n", // time: 184502 milliseconds 2 threads -O3
t, // time: 189947 milliseconds 3 threads -O3
NUM_THREADS // time: 202277 milliseconds 4 threads -O3
); // time: 182628 milliseconds 5 threads -O3
} // time: 192032 milliseconds 6 threads -O3
// time: 185771 milliseconds 7 threads -O3
Основная проблема в этой версии - ложный обмен. Это объясняется позже в видео, которое вы начали смотреть. Вы получаете это, когда много потоков обращаются к данным, которые смежны в памяти (sum массив). Видео также объясняет, как использовать отступы, чтобы вручную избежать этой проблемы.
Тем не менее, идиоматическое решение состоит в том, чтобы использовать сокращение и даже не беспокоиться о ручном распределении работы:
double sum = 0;
#pragma omp parallel for reduction(+:sum)
for(int i=0; i < num_steps; i++)
{
double x = (i+0.5)*step;
sum += 4.0/(1.0+x*x);
}
Это также объясняется в более позднем видео серии. Это намного проще, чем то, с чего вы начали, и, скорее всего, наиболее эффективным способом.
Несмотря на то, что докладчик, безусловно, компетентен, стиль этих обучающих видео по OpenMP очень сильно снизу вверх. Я не уверен, что это хороший образовательный подход. В любом случае вам, вероятно, стоит посмотреть все видео, чтобы узнать, как лучше всего использовать OpenMP на практике.
Почему я получаю только лучшую производительность с гораздо большим количеством потоков?
Это немного нелогично, вы очень редко получаете лучшую производительность от использования большего количества потоков OpenMP, чем от аппаратных потоков - если это не косвенно решает другую проблему. В вашем случае большое количество потоков означает, что sum массив распределяется по большей области в памяти, и ложное разделение менее вероятно.